推荐系统的在线部分往往使用spark-streaming实现,这是一个很重要的环节。
在线流程的实时数据一般是从kafka获取消息到spark streaming
spark连接kafka两种方式在面试中会经常被问到,说明这是重点,下面为大家介绍一下这两种方法:
第一种方式:Receiver模式 又称kafka高级api模式
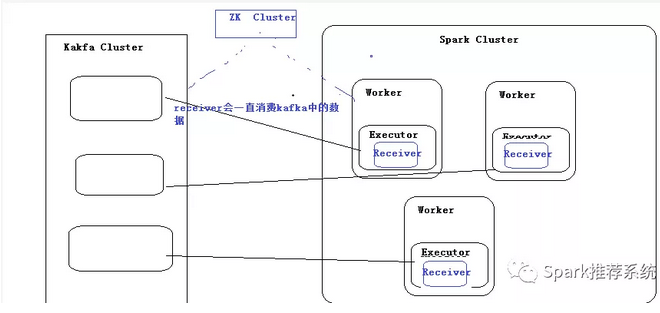
效果:SparkStreaming中的Receivers,恰好kafka有发布、订阅,然而:这种方式企业不常用,说明有bug,不符合企业需求。因为:接收到的数据存储在Executor,会出现数据漏处理或者多处理状况。
简单的理解就是kafka把消息全部封装好,提供给spark去调用,本来kafka的消息分布在不同的partition上面,相当于做了一步数据合并,在发送给spark,故spark可以设置executor个数去消费这部分数据,效率相对慢一些。
代码实例:
object ReceiverKafkaWordCount { Logger.getLogger("org").setLevel(Level.ERROR) def main(args: Array[String]): Unit = { val Array(brokers, topics) = Array(Conf.KAFKA_BROKER, Conf.TEST_TOPIC) // Create context with 2 second batch interval val conf = new SparkConf() .setMaster("local") .setAppName("OnlineStreamHobby") //设置本程序名称 // .set("auto.offset.reset","smallest") val ssc = new StreamingContext(conf, Seconds(2)) // 从kafka取数据 val kafkaParams: Map[String, String] = Map[String, String]( // "auto.offset.reset" -> "smallest", //自动将偏移重置为最早的偏移 "zookeeper.connect" -> Conf.ZK_HOST, // "bootstrap.servers" -> Common.KAFKA_BROKER_LIST, "group.id" -> "test" ) val numThreads = 1 val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val fact_streaming = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_2).map(_._2) // fact_streaming.print() val words = fact_streaming.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _) wordCounts.print() ssc.checkpoint(".") //启动spark并设置执行时间 ssc.start() ssc.awaitTermination() } }
效果:每次到topic的每个partition依据偏移量进行获取数据,拉取数据以后进行处理,可以实现高可用
解释:在spark 1.3中引入了这种新的无接收器“直接”方法,以确保更强大的端到端保证。这种方法不是使用接收器来接收数据,而是定期查询kafka在每个topic+分partition中的最新偏移量,并相应地定义要在每个批次中处理的偏移量范围。当处理数据的作业启动时,Kafka简单的客户API用于读取Kafka中定义的偏移范围(类似于从文件系统读取文件)。请注意,此功能在Spark 1.3中为Scala和Java API引入
简单的理解就是spark直接从kafka底层中的partition直接获取消息,相对于Receiver模式少了一步,效率更快。但是这样一来spark中的executor的工作的个数就为kafka中的partition一致,设置再多的executor都不工作,同时偏移量也需要自己维护。
代码示例:
object DirectTest { def main(args: Array[String]) { val conf = new SparkConf().setAppName("kafka direct test").setMaster("local") val sc = new SparkContext(conf) val ssc = new StreamingContext(sc,Seconds(10)) //kafka基本参数,yourBrokers你的brokers集群 val kafkaParams = Map("metadata.broker.list" -> Conf.KAFKA_BROKER) val topic = "test" val customGroup = "testGroup" //新建一个zkClient,zk是你的zk集群,和broker一样,也是"IP:端口,IP端口..." /** *如果你使用val zkClient = new ZKClient(zk)新建zk客户端, *在后边读取分区信息的文件数据时可能会出现错误 *org.I0Itec.zkclient.exception.ZkMarshallingError: * java.io.StreamCorruptedException: invalid stream header: 7B226A6D at org.I0Itec.zkclient.serialize.SerializableSerializer.deserialize(SerializableSerializer.java:37) at org.I0Itec.zkclient.ZkClient.derializable(ZkClient.java:740) .. *那么使用我的这个新建方法就可以了,指定读取数据时的序列化方式 **/ val zkClient = new ZkClient(Conf.ZK_HOST, Integer.MAX_VALUE, 10000,ZKStringSerializer) //获取zk下该消费者的offset存储路径,一般该路径是/consumers/test_spark_streaming_group/offsets/topic_name val topicDirs = new ZKGroupTopicDirs(customGroup, topic) val children = zkClient.countChildren(s"${topicDirs.consumerOffsetDir}") //设置第一批数据读取的起始位置 var fromOffsets: Map[TopicAndPartition, Long] = Map() var directKafkaStream : InputDStream[(String,String)] = null //如果zk下有该消费者的offset信息,则从zk下保存的offset位置开始读取,否则从最新的数据开始读取(受auto.offset.reset设置影响,此处默认) if (children > 0) { //将zk下保存的该主题该消费者的每个分区的offset值添加到fromOffsets中 for (i <- 0 until children) { val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/$i") val tp = TopicAndPartition(topic, i) //将不同 partition 对应的 offset 增加到 fromOffsets 中 fromOffsets += (tp -> partitionOffset.toLong) println("@@@@@@ topic[" + topic + "] partition[" + i + "] offset[" + partitionOffset + "] @@@@@@") val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.topic,mmd.message()) directKafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String,String)](ssc, kafkaParams, fromOffsets, messageHandler) } }else{ directKafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, Set(topic)) } /** *上边已经实现从zk上保存的值开始读取数据 *下边就是数据处理后,再讲offset值写会到zk上 */ //用于保存当前offset范围 var offsetRanges: Array[OffsetRange] = Array.empty val directKafkaStream1 = directKafkaStream.transform { rdd => //取出该批数据的offset值 offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd }.map(_._2) directKafkaStream1.foreachRDD(rdd=>{ //数据处理完毕后,将offset值更新到zk集群 for (o <- offsetRanges) { val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}" ZkUtils.updatePersistentPath(zkClient, zkPath, o.fromOffset.toString) } rdd.foreach(println) }) ssc.start() ssc.awaitTermination() } }
转载于:https://www.cnblogs.com/yfb918/p/10528651.html
END