虚拟地址
隔离进程,便于管理。
问:为什么不直接划分物理地址为一块一块,直接管理,而要做一层虚拟地址的映射呢?
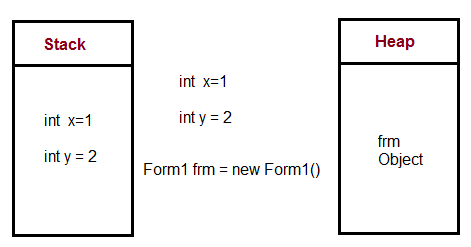
栈和堆
Differences between Stack and Heap
Stack is used for static memory allocation and Heap for dynamic memory allocation, both stored in the computer's RAM .
Variables allocated on the stack are stored directly to the memory and access to this memory is very fast, and it's allocation is dealt with when the program is compiled. When a function or a method calls another function which in turns calls another function etc., the execution of all those functions remains suspended until the very last function returns its value. The stack is always reserved in a LIFO order, the most recently reserved block is always the next block to be freed. This makes it really simple to keep track of the stack, freeing a block from the stack is nothing more than adjusting one pointer.
Variables allocated on the heap have their memory allocated at run time and accessing this memory is a bit slower, but the heap size is only limited by the size of virtual memory . Element of the heap have no dependencies with each other and can always be accessed randomly at any time. You can allocate a block at any time and free it at any time. This makes it much more complex to keep track of which parts of the heap are allocated or free at any given time.
You can use the stack if you know exactly how much data you need to allocate before compile time and it is not too big.You can use heap if you don't know exactly how much data you will need at runtime or if you need to allocate a lot of data.
In a multi-threaded situation each thread will have its own completely independent stack but they will share the heap. Stack is thread specific and Heap is application specific. The stack is important to consider in exception handling and thread executions.
伙伴系统

设计思路:
每次分配的时候,我们不要把一个大的空闲块拿来给它分割 拿一个比较合适的空闲块,这样的话系统中可以始终保持一些大的空闲块。
合适的空闲块:
内存管理方案
目的/最佳
内存利用率最大
页式
设计思想

逻辑地址
由页号、页内地址组成
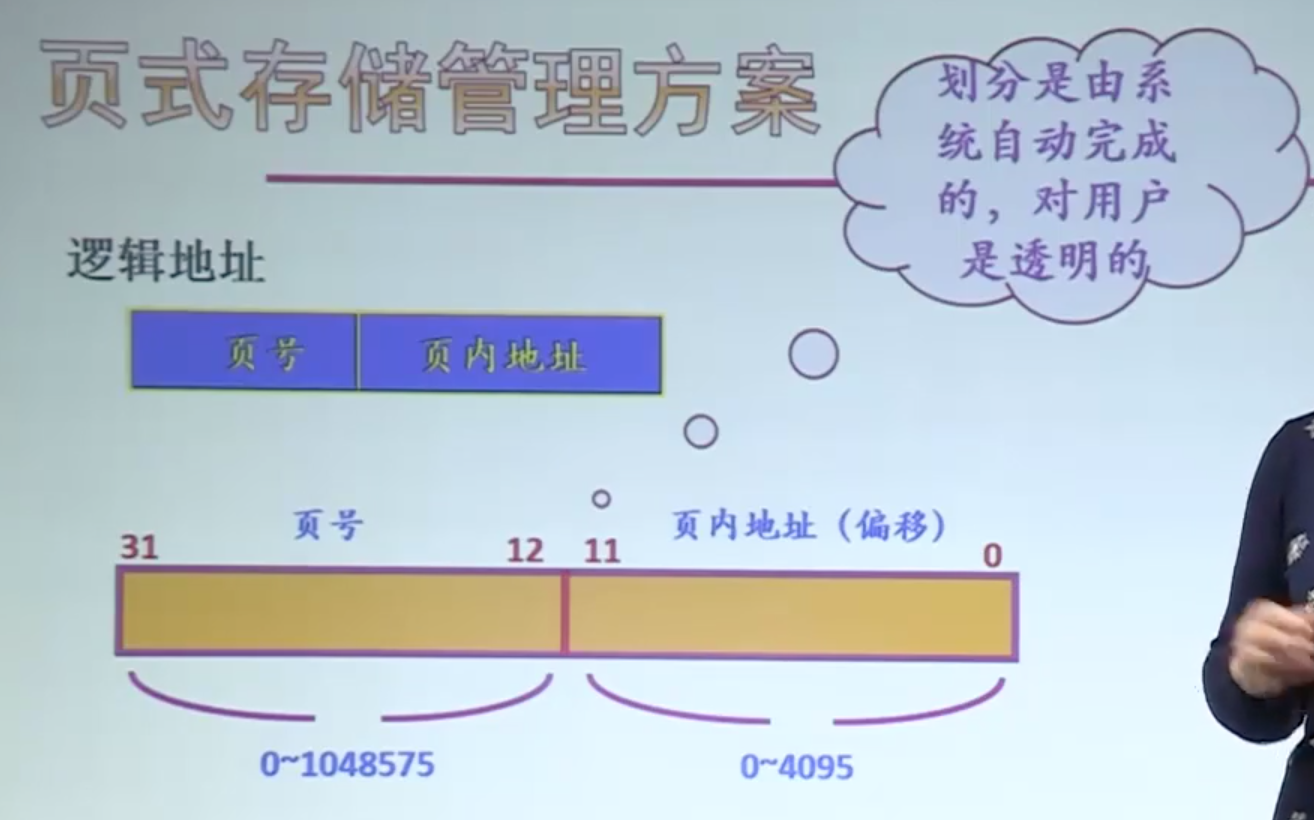
通过页表进行地址转换
页号、页内地址的用法

页表起始地址保存
在系统中只设置一个页表寄存器PTR(Page-Table Register),在其中存放页表在内存的始址和页表的长度。平时,进程未执行时,页表的始址和页表长度存放在本进程的PCB中。当调度程序调度到某进程时,才将这两个数据装入页表寄存器中。因此,在单处理机环境下,虽然系统中可以运行多个进程,但只需一个页表寄存器。
段式
设计思想

段式的逻辑地址
不是自动划分,必须显式给出
段式的逻辑地址准换
与页式的计算方式一样

总结段式与页式
最小单位不同。一个是段,一个是页
段与页
不同:页的大小固定,而段的大小根据程序来划分,不是固定的;逻辑地址都是相邻的;
相同:段与页在内存中都是连续的;不同段或不同页之间在物理内存中可以是不相邻的
段页式管理

转换

先拿到了一个逻辑地址 然后呢,这个逻辑地址是由两部分组成,段号和段内地址 那么它用段号去查段表,得到了所对应的页表的起始地址和长度 然后再把段内地址自动划分成两部分 页号页内地址,用页号去查对应的页表,得到 页框号,然后再和页内地址拼接成最后的物理地址
小结

上述方案中是否存在最佳的内存管理方案?或者说各个内存管理方案适用于什么情况?
那么Linux, windows使用哪种内存管理方案?
错题:
[多选题]下列关于地址重定位的叙述中,哪些是正确的?
地址重定位又称为地址转换或地址映射
动态地址重定位是在进程执行过程中完成的
用户进程中使用的是逻辑地址,且从0开始编址
内存的地址是按照物理地址编址的
静态地址重定位的完成过程必须有硬件支持

问:内存的地址是按照物理地址编址的
这个表述的什么意思?虚拟地址按照物理地址编址的?
[多选题]下列关于紧缩技术的叙述中,哪些是正确的?
紧缩技术可用于可变分区存储管理方案
紧缩技术不能解决内碎片问题
内存中任意一个进程都可以随时移动
完成紧缩会增加处理器的开销
紧缩技术可以合并分散的小空闲区,以形成大的空闲区
在可变分区管理方式下,在回收内存时,若已判断出“空闲区表中某一表项的起始地址恰好等于被回收分区的起始地址与长度之和”,则表示
被回收分区既有上邻空闲区,又有下邻空闲区
被回收分区有上邻空闲区
被回收分区无相邻空闲区
被回收分区有下邻空闲区
这个答案是错的,不知道为什么?
系统为某进程分配了4个页框,该进程已经完成了下列页号序列的访问:
3,1,3,10,4,5,3,8,3,4,9,5,6
假设该进程要访问的下一个页号是8,根据最近最少(LRU)页面置换算法,应该被淘汰的页的页号是
9
5
3
4
假设使用一级页表,那么该进程的页表大小是多少?
4KB
4MB
32KB
32MB
解析:
P108 3.3.2 页表
页面大小、页面数
地址分为两部分,表示虚拟页号的高位部分以及表示对应虚拟页号的偏移量(低位部分)。比如,对于16位的地址,假设页面大小为4K。那么低位部分就为4K,也就是12位,剩余的16-12=4位
就是高位部分,表示虚拟页号。
一级页表
一个虚拟页面号对应一个页框。虚拟页面号通过页表项找到页框的地址。所以一个虚拟页面号也就对应一个页表项。
页表大小
页表项大小 * 页表项个数
对于本题来说,1024 * 4 = 4 MB
20
题干同19题。如果采用二级页表,且一级页表的大小和二级页表的大小相同(假设一级页表大小是1KB,则一个二级页表的大小也是1KB;假设一级页表大小是2KB,则一个二级页表的大小也是2KB),
那么该进程的两级页表加起来,至少占据____KB?
二级页表
书P111
看书上的概念糊涂了,这里总结一下。
一级页表是,由(页表号,偏移量)组成,页表号对应页框号;
二级页表是,由(一级页表号,二级页表号,偏移量)。由一级页表号找到二级页表号和页框号。
假如需要表达 10^30 个地址,一级需要 10^30 个页表项,二级需要 10^15 个,因为 10^15 * 10^15 = 10^30,三级需要 10^10个。
本题中就需要 2^10/2 = 2^5 个页表项,就是 2^5 * 4 = 128 KB
21 题干同19题。如果采用二级页表,且一级页表的大小是二级页表大小的四倍(假设一级页表大小是4KB,则一个二级页表的大小是1KB;假设一级页表大小是8KB,则一个二级页表的大小是2KB),
那么该进程的两级页表加起来,至少占据____KB?
上面提到,表示 1024个地址,二级页表需要 2^5 个页表项。那么这么多页表项这么分配到一级与二级页表呢?
列出方程: x + y = 5; 求 4x + 2y 的最小值,当 x = 0 时最小,为 10 KB
22 如果需要置换其中一个页面,若采用最近未使用(NRU)页面置换算法,将会置换哪一个页面?
NRU
使用 R位和M位来构建的算法:当启动一个进程时,所有页面的两个位被置为0,R位被定期地清零,来区别最近没有访问的页面。当发生缺页中断时,开始检查所有页面并分类
0:没有被访问,没有被修改
1:没有被访问,已被修改(由3的R位置为0而来)
2:已被访问,没有被修改
3:已被访问,已被修改
然后淘汰数字最小的页面。
可以看出,算法偏向于最近被访问的页面,所以 2>1。
思考:是如何检查所有页面的?如果是遍历,那么当发现 0 分类的时候,直接替换然后就可以终止检查了啊。