本课主题
- Checkpoint 运行原理图
- Checkpoint 源码解析
引言
Checkpoint 到底是什么和需要用 Checkpoint 解决什么问题:
- Spark 在生产环境下经常会面临 Transformation 的 RDD 非常多(例如一个Job 中包含1万个RDD) 或者是具体的 Transformation 产生的 RDD 本身计算特别复杂和耗时(例如计算时常超过1个小时) , 可能业务比较复杂,此时我们必需考虑对计算结果的持久化。
- Spark 是擅长多步骤迭代,同时擅长基于 Job 的复用。这个时候如果曾经可以对计算的过程进行复用,就可以极大的提升效率。因为有时候有共同的步骤,就可以免却重复计算的时间。
- 如果采用 persists 把数据在内存中的话,虽然最快速但是也是最不可靠的;如果放在磁盘上也不是完全可靠的,例如磁盘会损坏,系统管理员可能会清空磁盘。
- Checkpoint 的产生就是为了相对而言更加可靠的持久化数据,在 Checkpoint 可以指定把数据放在本地并且是多副本的方式,但是在正常生产环境下放在 HDFS 上,这就天然的借助HDFS 高可靠的特征来完成最大化的可靠的持久化数据的方式。
- Checkpoint 是为了最大程度保证绝对可靠的复用 RDD 计算数据的 Spark 的高级功能,通过 Checkpoint 我们通过把数据持久化到 HDFS 上来保证数据的最大程度的安任性
- Checkpoint 就是针对整个RDD 计算链条中特别需要数据持久化的环节(后面会反覆使用当前环节的RDD) 开始基于HDFS 等的数据持久化复用策略,通过对 RDD 启动 Checkpoint 机制来实现容错和高可用;
Checkpoint 运行原理图
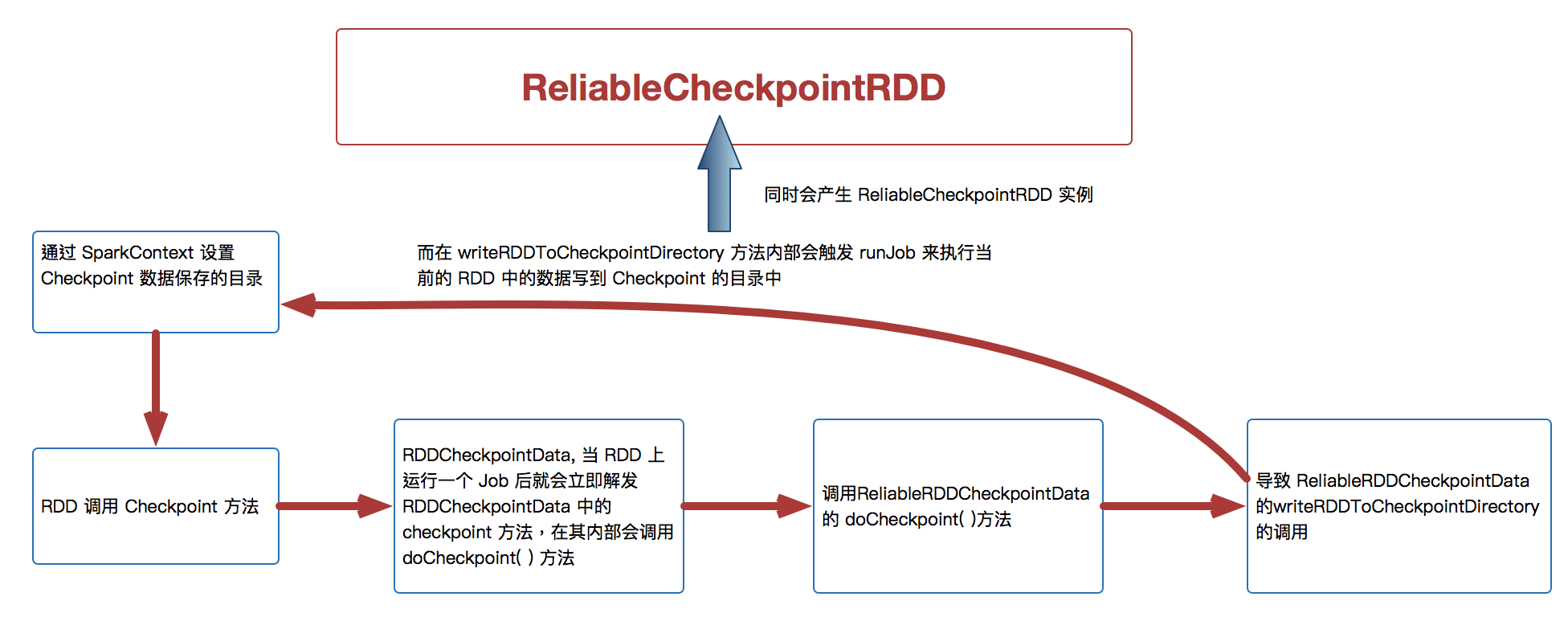
[下图是 Checkpoint 运行原理图]
Checkpoint 源码解析
- 回顾上一节的 RDD.iterator 方法,它会先在缓存中查看数据 (内部会查看 Checkpoint 有没有相关数据),然后再从 CheckPoint 中查看数据。
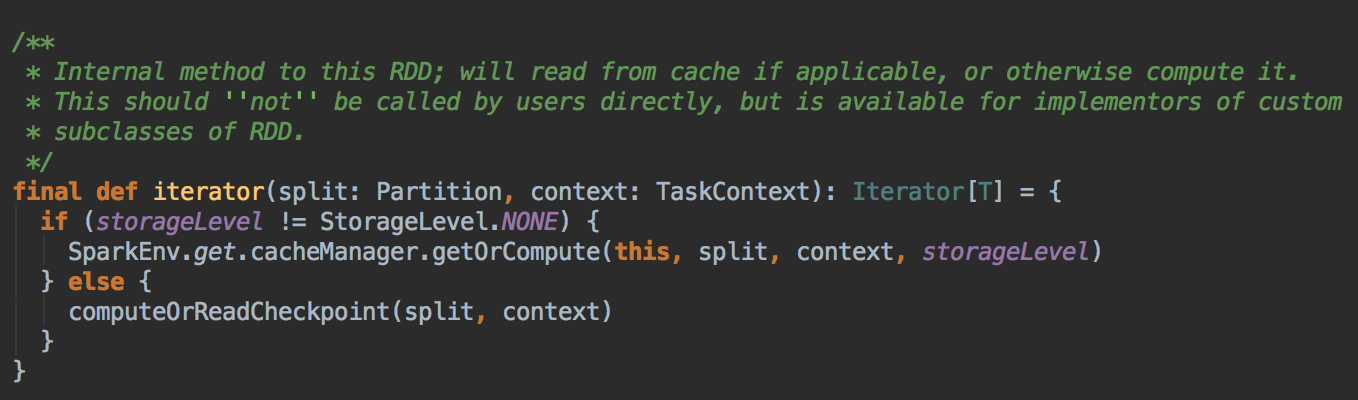
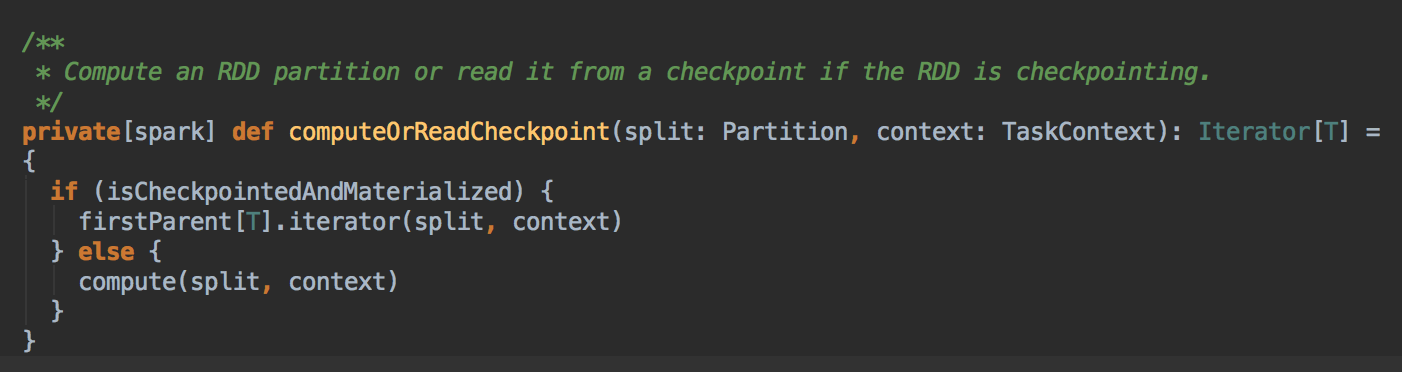
Checkpoint 有两种方法,一种是 reliably 和 一种是 locally
[下图是 RDD.scala 中的 isCheckpointed 变量和 isCheckpointedAndMaterialized 方法]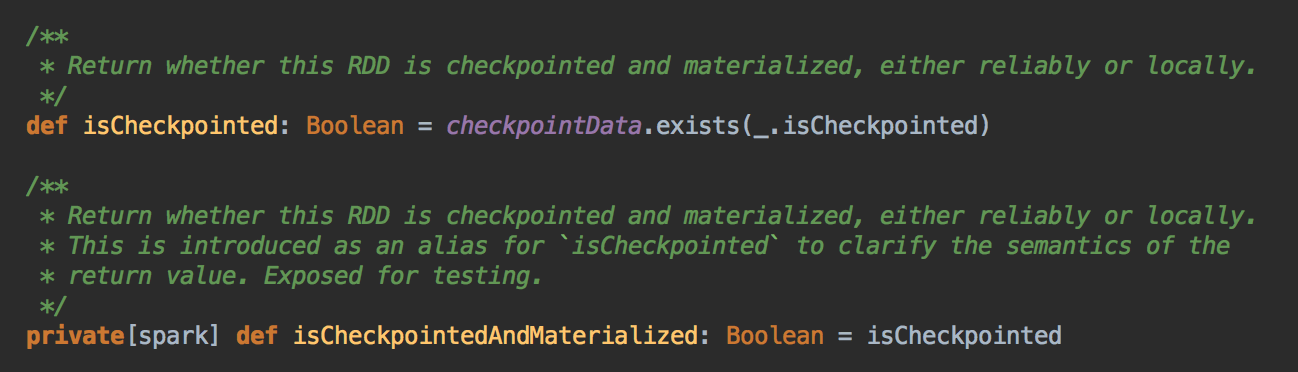
- 通过调用 SparkContext.setCheckpointDir 方法来指定进行 Checkpoint 操作的 RDD 把数据放在那里,在生产集群中是放在 HDFS 上的,同时为了提高效率在进行 Checkpoint 的时候可以指定很多目录
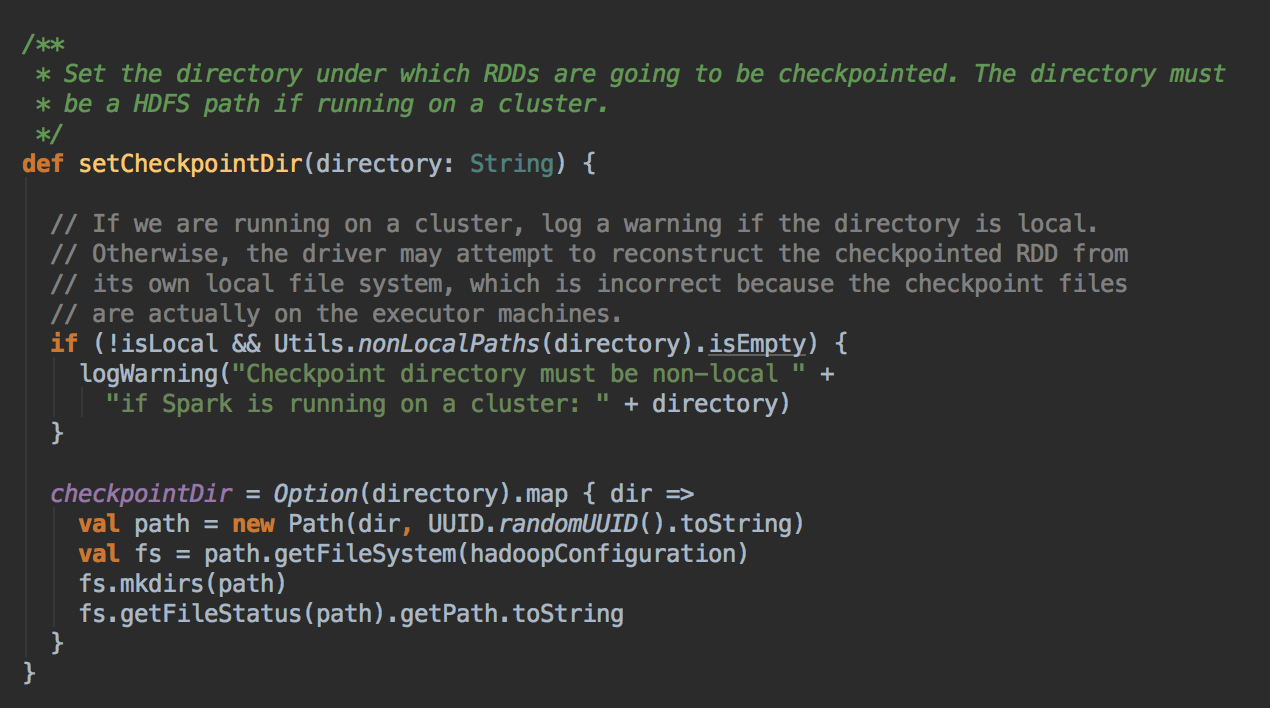
- 在进行 RDD 的 Checkpoint 的时候,其所依赖的所有 RDD 都会清空掉;官方建议如果要进行 checkpoint 时,必需先缓存在内存中。但实际可以考虑缓存在本地磁盘上或者是第三个组件,e.g. Taychon 上。在进行 checkpoint 之前需要通过 SparkConetxt 设置 checkpoint 的文件夹
[下图是 RDD.scala 中的 checkpoint 方法]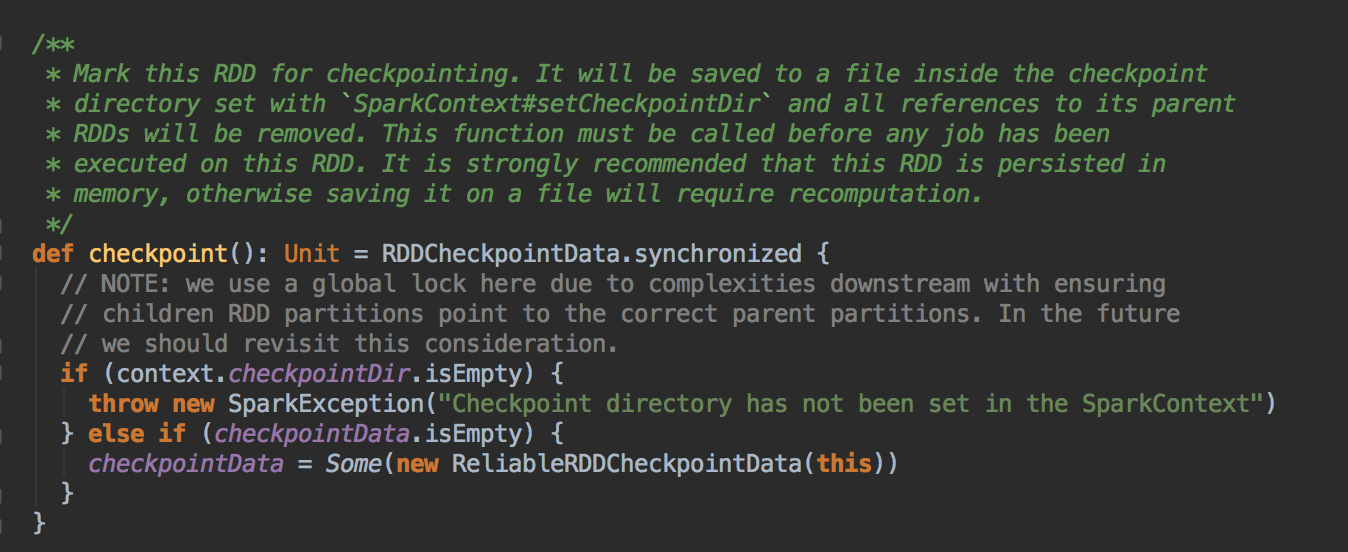
- 作为最住实际,一般在进行 checkpoint 方法调用前通过都要进行 persists 来把当前 RDD 的数据持久化到内存或者是上,这是因为 checkpoint 是 lazy 级别,必需有 Job 的执行且在Job 执行完成后才会从后往前回溯那个 RDD 进行了Checkpoint 标指,然后对该标记了要进行 Checkpoint 的 RDD 新启动一个Job 执行具体 Checkpoint 的过程;
- Checkpoint 改变了 RDD 的 Lineage
- 当我们调用了checkpoint 方法要对RDD 进行Checkpoint 操作的话,此时框架会自动生成 RDDCheckpointData

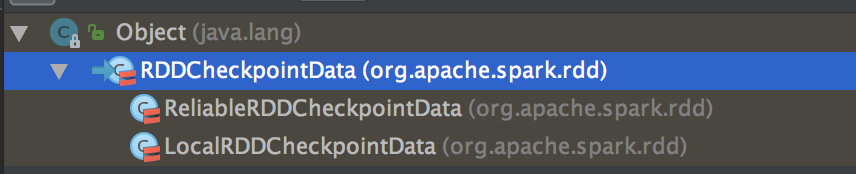
- 当 RDD 上运行一个Job 后就会立即解发 RDDCheckpointData 中的 checkpoint 方法,在其内部会调用 doCheckpoint( )方法,实际上在生产环境上会调用 ReliableRDDCheckpointData 的 doCheckpoint( )方法
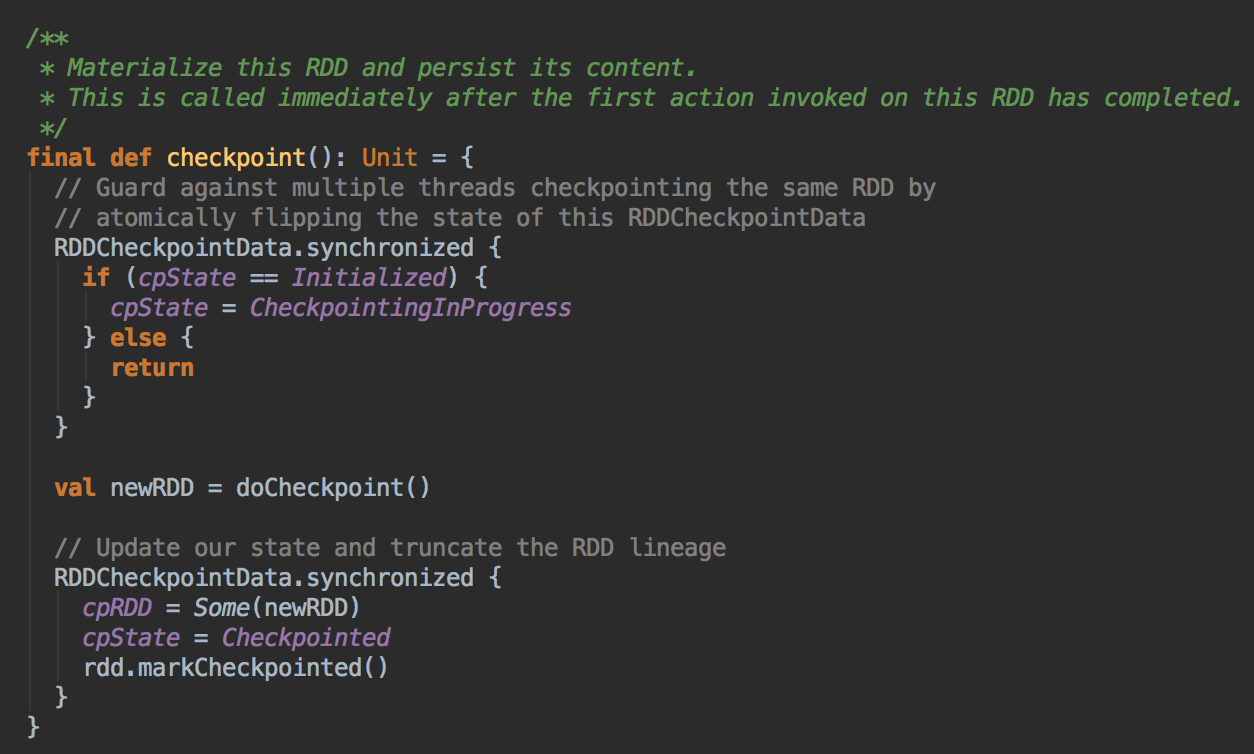
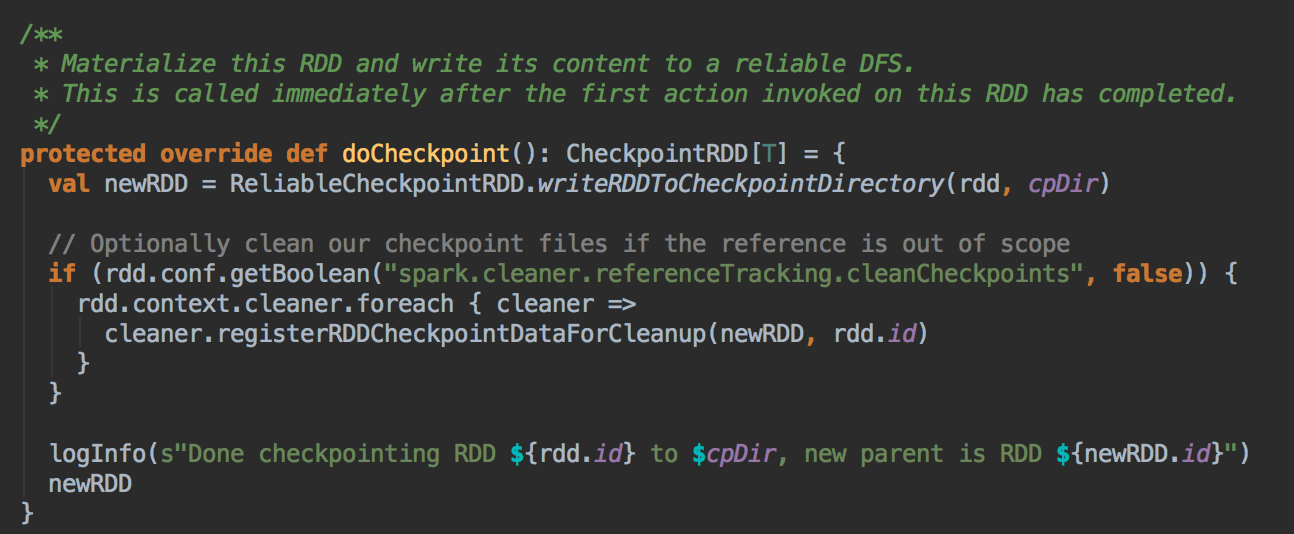
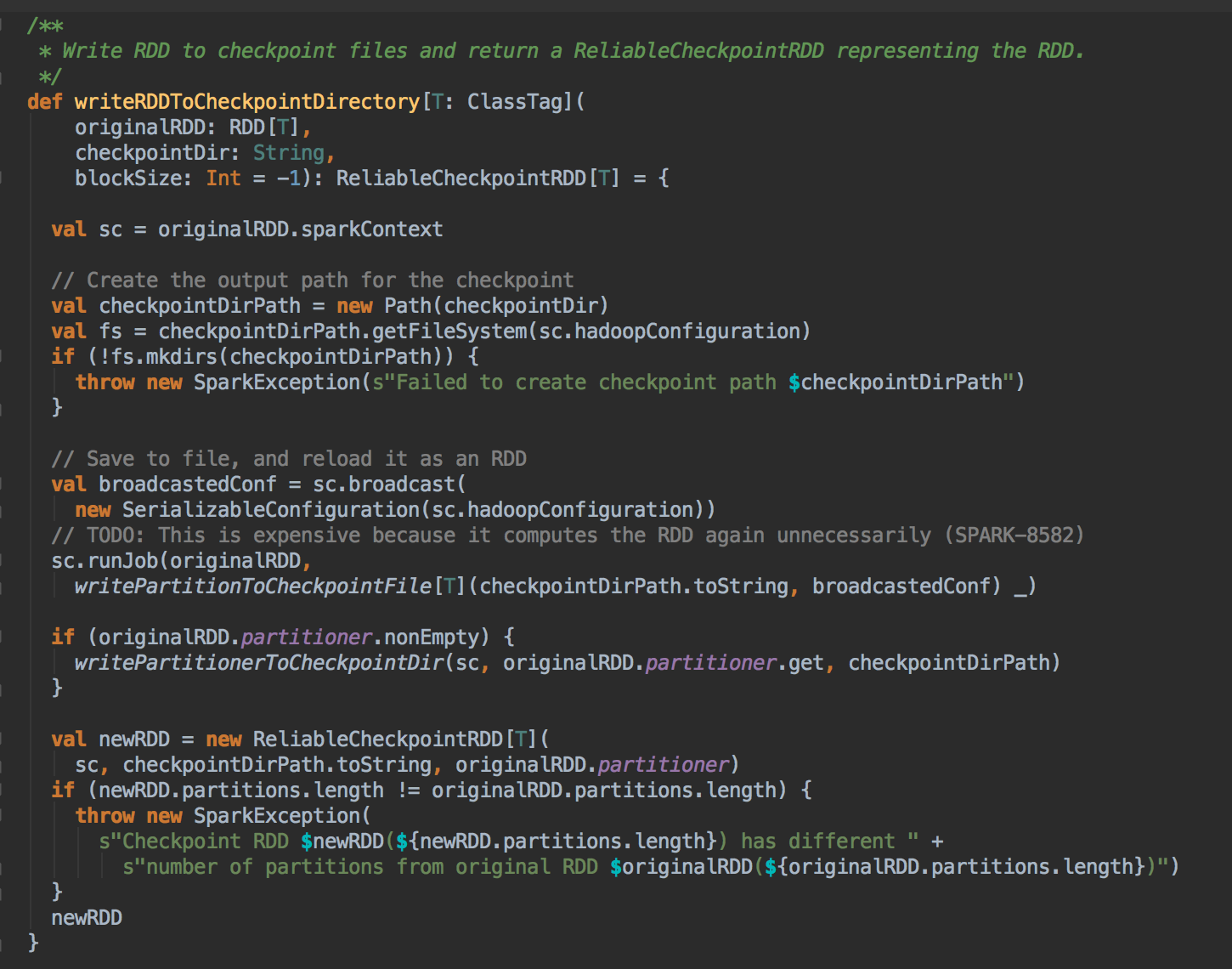
- 在生产环境下会导致 ReliableRDDCheckpointData 的 writeRDDToCheckpointDirectory 的调用,而在 writeRDDToCheckpointDirectory 方法内部会触发runJob 来执行当前的RDD 中的数据写到Checkpoint 的目录中,同时会产生ReliableCheckpointRDD 实例
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第41课:Checkpoint彻底解密:Checkpoint的运行原理和源码实现彻底详解
Spark源码图片取自于 Spark 1.6.0版本