如果设置hive.map.aggr为true,hive.groupby.skewindata为true,执行流程如下:
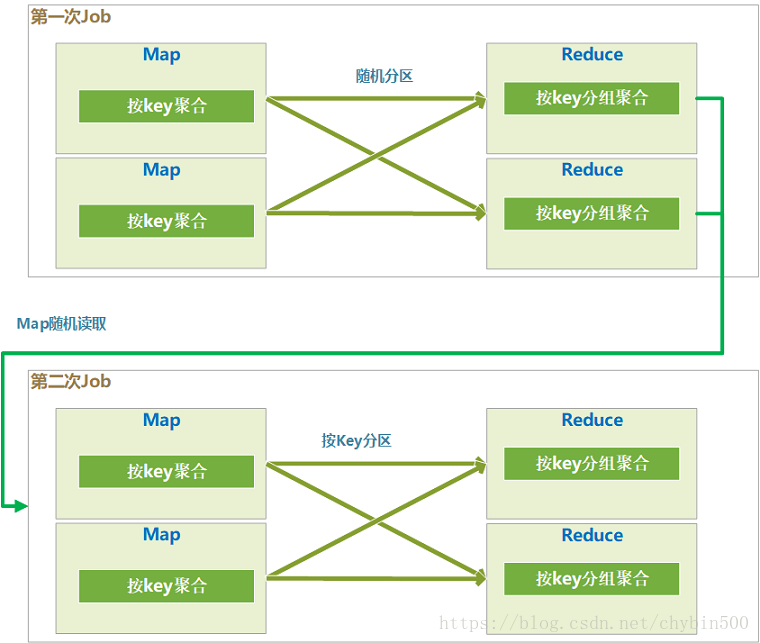
会生成两个job来执行group by,第一个job中,各个map是平均读取分片的,在map阶段对这个分片中的数据根据group by 的key进行局部聚合操作,这里就相当于Combiner操作。
在第一次的job中,map输出的结果随机分区,这样就可以平均分到reduce中
在第一次的job中,reduce中按照group by的key进行分组后聚合,这样就在各个reduce中又进行了一次局部的聚合。
因为第一个job中分区是随机的,所有reduce结果的数据的key也是随机的,所以第二个job的map读取的数据也是随机的key,所以第二个map中不存在数据倾斜的问题。
在第二个job的map中,也会进行一次局部聚合。
第二个job中分区是按照group by的key分区的,这个地方就保证了整体的group by没有问题,相同的key分到了同一个reduce中。
经过前面几个聚合的局部聚合,这个时候的数据量已经大大减少了,在最后一个reduce里进行最后的整体聚合。
————————————————
版权声明:本文为CSDN博主「鸣宇淳」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chybin500/article/details/80988089