一、原理:
聚合表存储预先计算的结果,这些结果是在一系列维度属性基础之上被聚合的。在决策支持系统中,使用聚合表是一个提高查询响应时间的比较流行的技术。该技术减少了运算的运行时间,以更快的速度将结果传递给用户。该技术将结果事前运算,并且将结果存储在表中。聚合表通常比非聚合表有更少的行,因此处理速度会更加快。
二、过程:
1、 首先在要使用聚合的维表上建立层次(是否必须建层,有待验证)
2、 构建聚合维表、聚合事实表
3、 物理层中将聚合维表、聚合事实表建立关联
4、 将物理层中聚合维表的列拖至业务逻辑层中原先维表的逻辑列上;聚合事实表的列拖至业务逻辑层中事实表对应的逻辑列上。

将下面的列从D1 Time Quarter Grain中拖向D1 Time中对应的列。
D1 Time Quarter Grain
D1 Time
CAL_HALF
Cal Half
CAL_QTR
Cal Qtr
CAL_YEAR
Cal Year
DAYS_IN_QTR
Days in Qtr
JULIAN_QTR_NUM
Julian Qtr Num
PER_NAME_HALF
Per Name Half
PER_NAME_QTR
Per Name Qtr
PER_NAME_YEAR
Per Name Year
上述操作创建了一个新的D1 Time Quarter Grain逻辑表源。
同理,

将下面的逻辑列从F2 Revenue Aggregate中拖至F1 Revenue中对应的列上。注意不要添加新的列。
F2 Revenue Aggregate
F1 Revenue
UNITS
Units
REVENUE
Revenue
5、 选中新添加的维表的逻辑表源、事实表的逻辑表源,分别在“内容”tab里面设置逻辑维和逻辑级别。 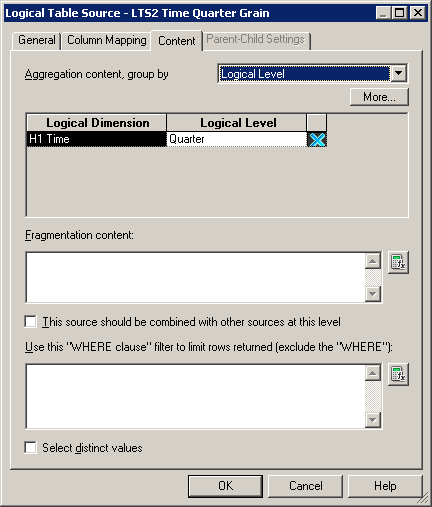
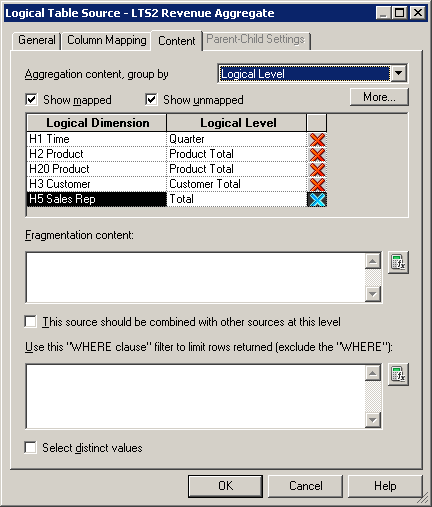
如果用户基于product、quarter来查询total sales,服务器将会选择F2 Revenue Aggregate事实表和对应的聚合维表D1 Time Quarter Grain。如果用户选择了一个比这里指定的级别更低的列,例如Month而不是Quarter,那么服务器将会选择明细表(F1 Revenue和D1 Time)。如果用户基于一个更加高的级别(年而不是季节)查询,那么聚合表将会被选择。
6、保存资料库,检查全局一致性。
7、关闭资料库,离开管理工具窗口。注意你没有必要该表表现层,你在业务模型中做的变化只是影响了查询怎样被处理,数据源的选择问题。然而用户的接口是没有变化的,所以没必要改变表现层。当用户查询时,Oracle BI Server将会自动选择合适的数据源。