C++ Concurrency in Action, 2nd /
C++17 并行算法
C++17 之后标准库为绝大部分算法提供了并行计算版本,比如 sort、find、transform 等。并行版方法和老版本函数名相同,如果需要调用并行版本的算法,需要在函数的第一个参数处指明执行方式,例如
std::vector<int> my_data;
// 使用 std::execution::par tag 指明调用并行版本,但运行时根据数据量可能是单线程执行
std::sort(std::execution::par,my_data.begin(),my_data.end());
标准库中 std::accumulate 只支持单线程版本,如果需要多线程版本可以考虑使用 C++17 提供的 std::reduce
execution policy
按照官方文档的说法,如果用户指定算法的执行方式为 std::execution::par,那么系统将“尝试”使用多线程方式进行计算,注意这里系统并不会强制使用多线程版本,为了效率与性能,系统可能依旧使用单线程。根据个人测试,无论数据量的多少, for_each 在 g++10 中一直是单线程执行的;在 visual studio 2022 prev 中数据量少时(10000 左右)是单线程,多于 10000 一般是多线程
标准库暂时提供了四种执行策略(until c++20,如下所示,右侧为缩写)。用户可以扩展相关 tag,比如新增 GPU 版本算法等。policy 详细含义请参考官方文档,后文只给出需要注意的地方
std::execution::sequenced_policy // std::execution::seq
std::execution::parallel_policy // std::execution::par
std::execution::parallel_unsequenced_policy // std::execution::par_unseq
std::execution::unsequenced_policy // std::execution::unseq, C++20
注意事项
seq
可以认为 seq 不会并行处理多条数据(比如使用矢量指令)。sequenced_policy 虽然不会使用多线程方式进行计算,但其行为和纯单线程版本函数不同
-
seq 的异常安全行为和其他 tag 一致(下文有简单说明),与老版函数(C++17 之前)不同。但 seq 保证指令在当前线程内执行
-
多线程场景下不同线程处理不同的数据,线程处理数据的顺序是不定的,seq 处理数据的顺序也是不定的(虽然很多实现是确定的)。如下示例代码,使用 seq,v 中元素取值范围是 1~1000000,但不一定有序
std::vector<int> v(1000000); int count=0; // 老版本没有 tag 的函数可以保证 v 是有序的;但有 tag 的算法不保证 std::for_each(std::execution::seq,v.begin(),v.end(),[&](int& x){ x=++count; }); -
拥有 seq tag 的算法对参加计算的迭代器、数据和 callable 函数有一定要求,但相比其他 tag 而言宽松很多
- 随意使用同步机制,比如 callable (上面
for_each中的 lambda)可以使用 mutex/原子变量 等工具 - 在当前线程内开始的行为(比如函数调用)默认在当前线程内结束,例如 callable 可以认为每次执行线程 ID 值相同
- 不能假设执行顺序,这是多线程算法的基本要求,线程调度是随机的,没法确定顺序
- 随意使用同步机制,比如 callable (上面
par
par tag 相比于 seq 而言更灵活,所以对参加计算的迭代器、数据和 callable 有更多的要求
- 线程内部的执行顺序一般是确定的,一个行为(比如函数调用)一般只在一条线程内执行
- 多线程执行时不能出现 data race,比如上面的 count 变量,使用 par tag 时需要改为 atomic
- 具体执行时,并行算法可能启动一条线程也可能启动多条线程
- 同步机制是允许使用的
par_unseq
par_unseq 最大化利用多线程与硬件(例如使用矢量指令一次处理多个数据),极大提升了计算效率,但也对迭代器、数据和 callable 提出了更多要求
- 线程内部的执行顺序是不确定的,一个行为(比如函数调用)可能在不同的线程中执行
- 同步机制不能使用,callable 中调用的其他函数也不能使用同步机制,线程之间和变量之间不能有任何关联
- 因为函数调用不能保证是在一个线程内完成的,所以mutex 的一次加锁解锁可能跨线程,这一般会造成异常
unseq (C++20)
与 seq tag 相比当前 tag 意味着算法可能使用硬件的矢量指令(矢量命令可能来自 CPU ,也可能是 GPU 等硬件,要看具体实现),所以 unseq 对迭代器、数据和 callable 的要求与 par_unseq 类似,具体细节可参考 cppref
其他资料
10.3.2 中的 counter visitor 是很好的并行算法使用示例
policy 对函数行为的影响
- 因为同步与线程安全等原因,多线程版本算法的时间复杂度可能达不到理论最佳
- 老版非并行算法执行过程中抛出的异常(包括用户自定义异常对象)可以一直向上传递;使用 policy 的新版算法如果发现其不能捕获的异常将直接调用 terminate 中断整个进程
- 函数将自行决定在哪些硬件上执行(CPU、GPU)、什么开始执行
- 并行算法在执行时不一定使用多线程;使用并行算法对迭代器、数据和 callable 提出了一些额外要求
thread & manager
C++ 中线程一般从创建 thread 对象时自动开始运行,当然还需要考虑 OS 的上下文切换开销, thread 对象可移动但不可拷贝
thread fun 参数
传参数给线程的可执行对象时默认以传值的形式,所以要避免线程启动前部分参数已经无效的情况
void f(int i,std::string const& s);
char buffer[9]="123";
// 使用 string 显式转换,避免 t 自行转换前 buffer 被清除
std::thread t(f, 3, std::string(buffer));
调用对象中的方法
class X {
public:
void do_lengthy_work();
};
X my_x;
std::thread t(&X::do_lengthy_work,&my_x);
Thread Pool
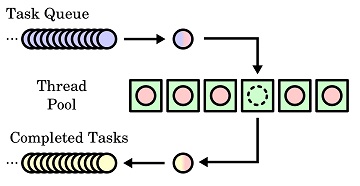
github 上有使用 C++11 条件变量和 future 实现的 ThreadPool ,只有一个头文件,但功能完整,值得学习;github 上还有其他 lockfree 的 threadpool 实现,比如 CTPL 等
contention on the work queue
所有 worker 线程共用一个 task 队列时容易造成竞争,比较好的办法是每个 worker 线程一个 task 队列,或者尽量减少共享 task 队列的 worker 线程数量
Work stealing
不同线程使用自己的 work queue 有个缺点,就是自己所有的 task 可能需要其他任务完成才能执行,所以当前线程有一直等待的风险,为了减少这个风险,当前线程应该有一定的能力从其他线程的 task queue 中窃取 task
Interrupting threads
一些场景下我们需要主动关闭一些正在运行的线程,常见的方法是在运行的线程中设置一个标志位,线程周期性的检查这个标志位
对于有阻塞行为的线程,使用标志位可能达不到理想的效果,因为线程一旦阻塞到某个位置,就不会去检查中断标志。常见的解决办法有两种:
- 需要线程退出时也给条件变量发就绪状态,由线程自行判断是处理事务、退出还是虚假唤醒
- 使用周期性阻塞,例如条件变量的
wait_for
使用 condition_variable_any 可以适当简化相关编码,因为我们可以为 condition_variable_any 提供自定义的 Lock,可以将标志位的检查写在自定义 Lock 中
互斥 & 同步
Race Condition vs. Data Race / Lock-Free Programming Part I / Memory Model / C++ and Beyond 2012- Herb Sutter - atomic Weapons bilibili&youtube /
有若干种方式实现数据的互斥与同步,例如 mutex、原子变量和事务等
Mutex & Condition
使用锁时不能泄露变量的指针或者引用,一切对变量的修改都需要使用指定的函数与方法,不能给用户自定义函数访问裸数据的机会
Lock RAII: std::unique_lock && lock_guard
锁与接口
使用锁保护接口并不意味着完全安全,多个接口之间的组合可能会出现错误
stack<int> s; // 即使 empty 和 pop 都是线程安全的,下面的代码片段也不安全
if(!s.empty()) {
int const value=s.top();
s.pop();
do_something(value);
}
Condition
C++ 提供了两类 Condition 变量,std::condition_variable_any 和 std::condition_variable ,前者可以使用任何满足锁形式的锁对象,后者一般只配置 std::mutex 使用,除非特殊情况,推荐使用后者
// prepare data
data_chunk const data = prepare_data();
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
}
data_cond.notify_one();
// process data
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[]{return !data_queue.empty();}); // 操作系统有虚假唤醒的可能,unlock
data_chunk data = data_queue.front(); data_queue.pop();
lk.unlock(); // unlock before process data, mem pass instead of mem share
process(data);
if(is_last_chunk(data)) break;
One-off Event
条件变量(condition)适合那些需要多次触发的事件,对于一次性事件(One-off Event)而言使用条件变量过于复杂,C++ 标准库提供了一些工具可以很方便的处理一次性事件
std::future和std::shared_future类似 uniqueptr 和 sharedptr 之间的关系std::future<void>表示没有关联任何类型的值- 如果 future 关联的 promise 没有填充数据就被清除或者
packed_task没有执行就被清理,则 future get 抛异常且内部置错误码 - std::future 中的 get 只能执行一次,shared future 可以执行多次且可用于不同线程之中
- 多个 future 需要注意频繁唤醒,可使用
when_all/when_any/ latch 来解决相关问题
packed_task包装一个可执行对象,创建的新可执行对象可以通过get_future接口获得存储执行结果的 futurepromise对象也可以返回一个 future,promise 一旦填充值,其对应的 future 就 ready;promise 有个给 future 设置异常的方法set_exception(std::current_exception())
future && shared future
std::promise<int> p;
std::future<int> f(p.get_future());
assert(f.valid());
std::shared_future<int> sf(std::move(f));
assert(!f.valid());
assert(sf.valid());
auto sf=p.get_future().share();
Latches & barriers/flex_barrier (C++20)
A latch is a synchronization object that becomes ready when its counter is decremented to zero. A latch is thus a lightweight facility for waiting for a series of events to occur
The class template
std::barrierprovides a thread-coordination mechanism that allows at most an expected number of threads to block until the expected number of threads arrive at the barrier. Unlikestd::latch, barriers are reusable
常见的多线程编程模式
函数式编程
- 这里的函数是纯函数,相同的入参,任何时候调用函数,其返回值都相同
- C++ 中可以使用 future 实现函数式编程
CSP (msg passing)
- CSP,Communicating Sequential Processes
- 基于状态机,不同线程有不同的职能,前置线程如果需要,会将数据传输给后续线程进行处理,最大限度减少了数据的共享
Continuation-style
- 基于回调,比如可以给
std::future添加一个回调函数接口:fu.then(continuation)。包含 then 接口的 future 未来可能会进入标准库
Chaining continuations
连续使用 then
std::experimental::future<void> process_login(std::string const& username,
std::string const& password) {
return spawn_async([=]() { return backend.authenticate_user(username, password); })
.then([](std::experimental::future<user_id> id) {
return backend.request_current_info(id.get());
})
.then([](std::experimental::future<user_data> info_to_display) {
try {
update_display(info_to_display.get());
} catch (std::exception& e) {
display_error(e);
}
});
}
Lock-based Data Structure
线程安全 DS(Data Structure) 有一些特性:
- 尽可能使用标准库或者第三方库(例如 concurrentqueue/libcds/Junction ),不要手写线程安全 DS(特别是 lock-free ),把复杂性交给专家
- 无论怎么设计接口,只要有调用用户自定义方法的方法,整个 DS 就有死锁的风险
- 向容器内填充数据的时候需要调用相关的 assign/move 方法,这些方法有死锁的可能
为了尽可能提高系统性能,锁的粒度应该尽可能小:
- 将耗时操作移出临界区
- 不要在临界区内进行内存相关操作,比如临界区内不要构造容器,不使用 new 等
- 使用更小粒度的锁,比如 list 相关操作只对需要的节点加锁而不是对整个容器加锁
- 使用一定的技巧(例如 list 中的 dummy tail),可以实现数据结构的同时操作,比如两个线程同时对一个 list 进行 push back 与 pop front 操作。这个技巧是为 list 添加条件变量的基础,详细信息请参考原文
- 对每一个节点使用一个锁
atomic type
is_lock_free / C++ 17 static constexpr X::is_always_lock_free /
atomic vs mutex
Mutex locks are typically implemented as a read-modify-write atomic operation on a memory location within the mutex to try to acquire the mutex, followed by a call to the operating system kernel if the mutex is already locked (eg. thread switch)
使用 mutex、condition、future 的算法与数据结构一般被称为 blocking 算法与数据结构,因为代码执行到对应位置时有被 block 的可能(OS 一般让出当前线程的时间片)。不使用这些工具的方法与数据结构被称为 noblocking,比如 lock-free 等。blocking 方法的特点是全局排他性,同一时刻只有一个线程能访问变量,即使所有线程只读也一样
从硬件角度讲,原子变量也不是完全没有“锁”,只是这个锁的硬件粒度比 mutex 要小,所以使用原子变量依旧有饥饿问题(某一个原子操作一直无法完成)。使用 mutex,其他线程的读写都被限制,而使用原子变量所有线程可同时读数据。这就造成在某些场景下原子变量比锁的性能高。原子变量比锁轻量的原因如下:
- 原子变量非 block,线程不用上下文切换
- 原子变量可以多线程同时读,减少了线程间某些场景下的排队,提高了系统吞吐量
- 原子变量“锁”的粒度比 mutex 小,Cache 数据同步量比锁少,性能损耗也会小一些
- 原子变量没有线程获得锁未释放前被切换出去后其他线程无法执行的风险,这也是原子变量原子性的优点
- 原子变量没有死锁的风险(这里不考虑多个 SpinLock 造成的死锁)
虽然原子变量在某些场景下比锁性能高,但并不意味着原子变量适用所有场景,尽量只将原子变量用于计数场景。下文 Lock-Free 章节将介绍原子变量比 mutex 性能差的相关原因
std::atomic_flag
std::atomic_flag is an atomic boolean type. Unlike all specializations of std::atomic, it is guaranteed to be lock-free. Unlike
std::atomic<bool>,std::atomic_flagdoes not provide load or store operations.
- 尽量用其他原子变量替换
atomic_flag,即尽量不要使用atomic_flag - C++ 标准强制要求当前类型 lock-free
- 特殊的初始化方式:
std::atomic_flag f=ATOMIC_FLAG_INIT;,c++20 之后可以使用默认构造函数,当前初始化方式被弃用 atomic_flag不支持同类型的相互赋值,即不支持flag_a = flag_b- 单个原子变量可以保证原子性,多个原子变量的操作暂时没法保证原子性
使用 atomic flag 实现的自旋锁:
class spinlock_mutex {
std::atomic_flag flag;
public:
spinlock_mutex() : flag(ATOMIC_FLAG_INIT) {}
void lock() {
// read-modify-write (RMW) 操作,系统保证多线程场景下的 sync-with
while (flag.test_and_set(std::memory_order_acquire));
}
void unlock() { flag.clear(std::memory_order_release); }
};
std::atomic<bool>
std::atomic<bool> b;
bool x = b.load(std::memory_order_acquire);
b.store(true);
x = b.exchange(false,std::memory_order_acq_rel); // RMW
compare_exchange weak vs strong
部分硬件平台没有单一的类 CAS 指令,系统不能保证 compare_exchange 命令能一次性原子的执行成功,所以系统提供了两个不同的方法用于不同的场景
-
compare_exchange_weak,执行成功返回 true,失败返回 false(spurious failure)或者 expected 与当前值不匹配返回 false。所以一般需要结合循环来使用 weak 方法bool expected=false; extern atomic<bool> b; // set somewhere else while(!b.compare_exchange_weak(expected,true) && !expected); -
compare_exchange_strong,只有在 expected 不相等的时候才会返回 false。相当于其内部自行实现了 weak 使用中的 while 循环。所以 strong 的性能比 weak 要低,但有更严格的保证
注意事项
- 非 spurious failure 场景下,
compare_exchange_*会修改 expected 的值为原子变量当前值,expected 是 pass-by-ref。因此,如果需要强制修改变量的值,只需要加个死循环,此时无论 expected 是否满足要求,最终都会修改成功 - 上面两个函数都可以设置两个内存序,分别对应成功与失败,修改失败一般没有 store 操作,即没有改变原子变量的值,有些内存序无法使用
- 其他
template atomic<>
C++ 提供了一个模板方法 atomic<>,可用于实现用户自定义的原子类型,但编译器的实现不一定和内置原子变量保持一致
- 使用 atomic 模板的类型需要有 trivial copy-assignment operator
- 编译器可能使用锁实现相关操作
- 不同平台对不同变量的实现可能不同,有些平台支持双字变量的 CAS 操作,有些平台不支持
- atomic 模板成员方法与
atomic<bool>大致相同
其他原子类型 & Free function
其他内置原子类型可参考 cppreference
一些比较特殊的原子类型例如 std::atomic<std::shared_ptr<T>> 是 C++20 引入的(常规实现,sharedptr 对象内部有两个指针)
为了与 C 兼容,C++ 引入了一些用于原子变量操作的 Free function ,比如 C++20 之前用于智能指针的操作:
std::shared_ptr<my_data> p;
auto local=std::atomic_load(&p); // atomic read
...
std::shared_ptr<my_data> local(new my_data);
std::atomic_store(&p,local); // atomic set
C++ Memory model
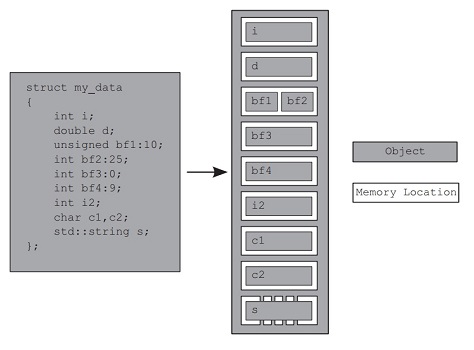
内存模型分为两大部分:结构(structural)与并发(concurrency),前者表示数据的内存布局
Memory Location
If two threads access separate memory locations, there’s no problem: everything works fine. On the other hand, if two threads access the same memory location, then you have to be careful. If neither thread is updating the memory location, you’re fine; read-only data doesn’t need protection or synchronization. If either thread is modifying the data, there’s a potential for a race condition
C++ 中所有变量(包含空对象与成员变量)在内存中都有自己的内存位置(若干连续的字节),内置类型(如 char、int 等)占据一个位置,相邻的位域可能共享内存位置
Modification orders
In the absence of other ordering constraints, the only requirement is that all threads agree on the modification order of each individual variable
编译器可以保证线程场景下前置代码对变量的修改对当前线程后续代码是直接且明显的,但多线程场景下(inter-threads)不能保证
系统无法在多线程场景下保证 modification order 主要有两个原因,一个是编译器与 CPU 的乱序,另一个是当代硬件为解决 CPU 和 Memory 在执行速度上差距过大而引入的多级缓存,可以参考其他资料了解相关知识。每个线程有自己的局部缓存,线程在修改局部缓存时并不一定强制(除非使用锁或者特定内存序的原子变量)与其他线程进行同步,所以即使是全局变量,同一时刻不同线程看到的“值”也可能不一样
happens-before & sync-with
// global data
std::vector<int> data;
std::atomic<bool> data_ready(false);
// thread 1
void reader_thread() {
while (!data_ready.load()) {
std::this_thread::sleep(std::chrono::milliseconds(1));
}
std::cout <<”The answer =”<< data[0] <<”
”;
}
// thread 2
void writer_thread() {
data.push_back(42);
data_ready = true;
}
- synchronizes-with:在合适(默认即可)的内存序下
data_ready的写保证在不同线程之间是实时可见的(强制不同线程同步当前变量),编译器保证原子变量在不同线程间(inter-threads)的 modification order- 默认内存序下(
memory_order_seq_cst)原子变量提供多线程场景下的 synchronizes-with 保证 - 任何内存序下(即使是
memory_order_relaxed),连续的 RMW 操作(例如fetch_add/compare_exchange_weak)可以保证原子变量多线程场景下的 sync-with
- 默认内存序下(
- happens-before:
- 单线程内,比如
writer_thread中,data 的写入在 data ready 之前,这个是可以保证的 - 同一个函数多个参数的求值顺序标准并没有规范
- 单线程内,比如
- Inter-thread happens-before:在原子变量内存序的帮助下 happens-before 关系可以跨线程。上述代码片段因为使用了默认最严格内存序,所以在
reader_thread中 data 的写入也在 data ready 之前
Atomic Memory Orders
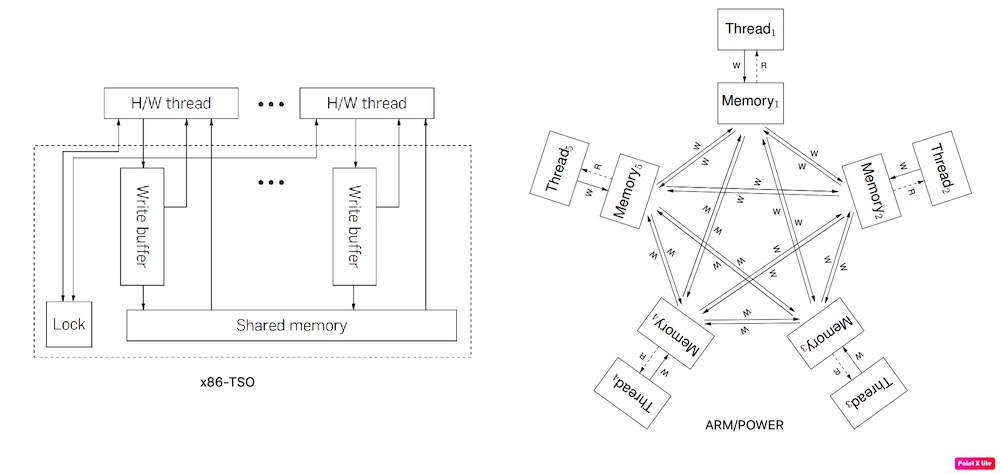
内存序可以分为 3 大类 6 种,如下文所示。提供不同类型的内存序是为了方便专家在不同平台选择最佳的方式,不同平台下不同的同步方式有非常大的性能差距。x86/x64 环境下下面不同内存序的性能接近,但 ARM/POWER 就不一定了。x86 硬件内存序(x86/TSO)比 ARM/POWER 要强,如下图所示(H/W, Hardware Thread)。具体细节可参考:Memory Models for C/C++ Programmers / A Primer on Memory Consistency and Cache Coherence, 2nd
下面示例代码均来自 C++ Concurrency in Action, 2nd,在 x86 架构机器上可能不能复现,如果需要测试请使用弱内存序 CPU,比如 ARM
sequentially consistent(最严格)
memory_order_seq_cst /
顺序一致性保证原子变量在多线程场景下的 modification order 与单线程一致,当前 order 是最严格/最耗时内存序
在 ARM 这类弱内存序硬件上,当前 order 有可能造成性能损害。顺序一致性下原子变量的写操作将实时触发 CPU cache 的同步,CPU 核心数越多造成的性能损耗就越多。X86 是强内存序,所以性能损耗不明显(UMA 架构下)
std::atomic<bool> x,y;
std::atomic<int> z;
// thread 1
void write_x_then_y() {
// store x happen-before storing y in this thread and sync-with with thread 2
// so x store happen-before storing of y in thread 2
x.store(true, std::memory_order_seq_cst);
y.store(true, std::memory_order_seq_cst);
}
// thread 2
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst));
// z could not be zero
if (x.load(std::memory_order_seq_cst)) ++z;
}
relaxed(最宽松)
memory_order_relaxed /
relaxed order 只保证当前线程中对应原子变量之后的操作不会读到原子变量更旧的值,没有多线程之间的 synchronizes-with 与 happen-before ,只保证单线程中的 happens-before。尽量不要使用当前 order
从 cache 的角度来看,当前 order 没有强制同步不同 CPU 核心的 cache,所以性能是所有 order 中最好的
std::atomic<bool> x,y;
std::atomic<int> z;
// thread 1
void write_x_then_y() {
// happen-before in this thread but no sync-with with thread 2
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_relaxed);
}
// thread 2
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed));
// z could be zero. in this thread, it could be y true and x false
if (x.load(std::memory_order_relaxed)) ++z;
}
acquire-release
memory_order_consume / memory_order_acquire / memory_order_release / memory_order_acq_rel /
acquire-release 在使用时内存序需要成对使用,比如 release/acquire。尽量不要使用 memory_order_consume
acquire-release 相比于 relaxed 而言,acquire-release 保证了多线程之间 happen-before,但不保证实时的 sync-with。从 cache 的角度上来看,acquire-release 同步不同 CPU core cache 不是实时的且全局的,但一旦同步,happens-before 是可以保证的
不同的行为要选择合适的内存序 tag,对 load 方法使用 memory_order_release 内存序是无效的
std::atomic<bool> x,y;
std::atomic<int> z;
// thread 1
void write_x_then_y() {
// store x happen-before storing y in this thread and thread 2
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_release);
}
// thread 2
void read_y_then_x() {
// this thread may read old value from thread 1 but happen-before is the same
// the change of y may not visiable for thread 2 ASAP like memory_order_seq_cst
while (!y.load(std::memory_order_acquire));
// z could not be zero
if (x.load(std::memory_order_relaxed)) ++z;
}
dependency-ordered-before and carries-a-dependency-to
The concept of a data dependency is relatively straightforward: there is a data dependency between two operations if the second one operates on the result of the first
memory_order_consume 没有跨线程 happens-before 的职能,但引入了 dependency order 概念,如下代码片段
下面代码使用了 memory_order_consume 内存序,与 p 相依赖(有关系)的变量会随着 p 在线程间进行同步,与 p 无关的变量不保证与 p 同时同步。所以下面第三个 assert 有可能被触发
struct X {
int i;
std::string s;
};
std::atomic<X*> p;
std::atomic<int> a;
// thread 1
void create_x() {
X* x = new X;
x->i = 42;
x->s =”hello”;
a.store(99, std::memory_order_relaxed);
p.store(x, std::memory_order_release);
}
// thread 2
void use_x() {
X* x;
while (!(x = p.load(std::memory_order_consume)))
std::this_thread::sleep(std::chrono::microseconds(1));
assert(x->i == 42); // guaranteed not to fire
assert(x->s ==”hello”); // guaranteed not to fire
assert(a.load(std::memory_order_relaxed) == 99); // may or may not fire
}
如果不想每次都同步缓存,可以使用 std::kill_dependency 告知编译器切断依赖链
int global_data[]={ ... }; // 当前数组只读
std::atomic<int> index;
void f(){
int i=index.load(std::memory_order_consume);
// 虽然使用了 consume 内存序且 i 与 index 关联
// 但因为 kill_dependency,global_data 不会同步
do_something_with(global_data[std::kill_dependency(i)]);
}
Standard for Programming Language C++
C++ 标准(如 n4892) 对原子变量的一些行为有明确规定,例如第 31.4 节中第 10 与第 11 条规定了 RMW 行为的特殊性与非顺序一致性(memory_order_seq_cst)原子操作在同步上的一些要求
......
10 Atomic RMW operations shall always read the last value (in the modification order) written
before the write associated with the RMW operation.11 Implementations should make atomic stores visible to atomic loads within a reasonable amount of time.
......
第 10 条是上文使用 atomic_flag 实现自旋锁的基础;第 11 条是 acquire-release 作为线程同步机制的基础
Fences
Fences are also commonlycalled memory barriers, and they get their name because they put a line in the code thatcertain operations can’t cross
Establishes memory synchronization ordering of non-atomic and relaxed atomic accesses, as instructed by
order, without an associated atomic operation
Fences 是原子变量内存序的基础,细节可参考 cppreference ,使用示例如下:
bool x = false;
std::atomic<bool> y;
std::atomic<int> z;
// thread 1
void write_x_then_y() {
x = true;
std::atomic_thread_fence(std::memory_order_release);
y.store(true, std::memory_order_relaxed);
}
// thread 2
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed));
std::atomic_thread_fence(std::memory_order_acquire);
if (x) ++z; // z is not zero
}
Ordering non-atomic operations
Ordering of non-atomic operations through the use of atomic operations is where these quenced-before part of happens-before becomes so important. If a non-atomic operation is sequenced before an atomic operation, and that atomic operation happens-before an operation in another thread, the non-atomic operation also happensbefore that operation in the other thread
从上文介绍可知原子变量的 happens-before & sync-with 关系同样适用于非原子变量,这是上文中使用 atomic_flag 实现自旋锁的基础,这也是 mutex、promise&future、packaged_task&future、async&future、latch、barrier、condition 同步的基础
Lock-free Data Structure
尽量使用第三方库而不是自己手写 Lock/Wait-Free 代码
和 mutex 等 blocking 方法相比,原子变量的排他性粒度更小、可同时读、是原子的、排他时间严格可控
noblocking(线程不会因为其他线程的挂起而挂起,可参考上文对 blocking 的介绍)可以分为以下三种:
- Obstruction-Free(非全局排他),其他线程被阻塞,余下的一个线程可以在有限时间内执行完对应操作,比如所有线程都需要对原子变量执行 RMW 操作,此时线程需要“排队”来操作原子变量,但任何线程不会因阻塞而被 OS 切出,更不会因为某个线程的挂起而造成其他线程的挂起
- Lock-Free(非全局排他),多条线程操作同一个数据对象,在有限时间内一定有一条线程执行成功。Obstruction-Free 是 Lock-Free 的特殊情况。如果多个线程访问同一个原子变量且不全部是 RMW 操作,那么多条读线程可以同时访问变量(比如同时读)
- Wait-Free,同时操作同一对象的多条线程都可以在有限时间内执行完成。以全局只读对象为例,所有线程在有限时间内可以完成对象读取,不用阻塞也不用“排队”。Wati-Free 相比于 Lock-Free 而言没有 retry(CAS 指令有失败的可能)与等待(RMW 的排他性)的过程
Lock-Free 代码并不一定比使用锁相关的代码更高效:
- Lock-Free 代码块可能比 no-atomic 代码更复杂,相同操作编译器可能需要多指令
- Lock-Free 代码一般需要 Cache 同步(cache ping-pong),同样会造成性能损失
- 在一些平台中除
atomic_flag外,其他原子变量内部可能使用锁实现
Lock-Free Stack
- 保证异常安全
- 避免内存泄漏,检查 nullptr 指针
- 其他
略...
concurrent code
Dividing data
使用多线程处理数据常用的方法就是将数据分配给不同的线程进行处理,分配的方式多种多样,例如均分、递归分配等。数据分配处理的前提是保证正确的内存序 ,比如 thread 对象在创建与销毁(join)时都会同步数据、future 的 get 操作也会同步数据...
常用技巧
- data based:container +
promise & future+ thread pool +hardware_concurrency()-1- 原书 list 8.1 使用 stack +
promise & future+ thread pool + 递归实现了链表的快排算法 - 线程不能有任何阻塞操作,否则线程池有耗尽的风险
- 有需要可以主动调用 yield 切出当前线程
- 当前线程也可以作为 worker 线程,所以线程池的大小是
hardware_concurrency() - 1
- 原书 list 8.1 使用 stack +
- task based:container + thread pool + pipeline
- 不同线程有不同职能线程之间使用无锁队列实现通信
- 事件 + 队列 + worker fun + 线程池 可以简化多线程模型
影响多线程性能的因素
- 线程的数量,过多过少都是问题
- high contention / cache ping-pong,修改原子变量时 cache 的同步造成了线程的等待,如果此种情况非常频繁,则称之为 high contention,反之则称之为 low contention
- 尽量减少不同线程间共享的数据
- False sharing,CPU 每次缓存的是一块连续的内存空间,多条线程可能同时缓存相同的块,特别是同 cache 缓存了不同线程需要访问的数据,某一条线程对数据的修改会强制其他线程同步 cache,这是硬件的同步机制
- 多线程场景下对于需要修改原数据的计算,每次批量元素的个数最好是 cache 空间的整数倍。不过不太容易实现
- 不同线程需要访问的不同数据尽量不要相邻,可以使用下面的代码做隔离
char padding[std::hardware_destructive_interference_size],clang & gcc 有可能没有实现(20211004),具体请参考 stackoverflow 。此时可以使用一个合理的整数
- mutex contention。常见的 mutex 实现使用了原子变量,比如 futex。原子变量的 RMW 操作会强制同步 cache。如果 mutex 对象和线程所使用的数据在同一个 cache line 中,且当前锁已经被线程 A 获取,其他线程对锁的 lock 操作会影响到 A 的执行,因为线程 A 使的包含 mutex 的 cache 有被强制更新的可能或者 cache 被 CPU 临时锁定以保证缓存的一致性。如果允许,尽量保证 mutex 对象占用单独的 cache
- task switching & data proximity,编码时为避免 False sharing 所采用的一些手段,比如在相邻数据间填充无效数据,会降低缓存命中率,从而降低单线程性能
- 同一线程需要访问的数据尽量相邻,以提高缓存命中率
- 少量数据的查找,使用数据结构 map((O(logn))) 并不一定比 vector((O(n))) 快,因为 map 的元素相隔大部分请情况下比 vec 远,在数据变化不频繁的前提下,
vector + sort/binary_search或者 heap 是不错的选择;数据分布合理的情况下hash_map比 map 性能要优秀
以矩阵计算为例,如果两个参加计算的矩阵都比较大,那么使用分块矩阵法进行计算是比较好的。直接使用常规的计算方法,右侧矩阵有 data proximity 的问题,右侧参加矩阵计算的元素在内存中不相邻,Cache 命中率非常低
多线程算法示例
多线程算法可参考:TBB / C++17 标准库 /
- 并行
for_each,不同线程处理不同数据元素,线程间没有明确的顺序 - 并行
find,利用done_flag减少无用的搜索 partial_sum,暂略