前言
我自己是个python小白,工作也不是软件行业,但是日常没事时喜欢捣鼓一些小玩意,自身有点C语言基础。
听说python很火,可以做出爬虫去爬一些数据图片视频之类的东东,我的兴趣一下子就来了。然后,开始了不归路,各种百度,各种实验。。。
最终的代码环境是安装了python 3.7,安装了PyCharm代码工具,别问我为啥选PyCharm,我也不知道,用着非常顺手不是吗。
当我开始写代码时,找了好多帖子去借鉴尝试,发现python2.0和3.0语法,所用模块等不一样,所以先说好,这个随笔的python版本是3.7的,不属于2.0版本。
这次爬虫的网站是百度贴吧,壁纸吧里的图片,可以打开下面的网址,然后随意选个帖子。
https://tieba.baidu.com/f?ie=utf-8&kw=%E5%A3%81%E7%BA%B8&fr=search
先说下写爬虫的步骤:1.发送网页请求 2.获取响应内容 3.解析网页内容 4.保存数据
第一步是发送请求和响应内容这两个最基本的操作:
要用到urllib.request这个模块,直接开头import就好,python自带的,上代码:
1 #! /usr/bin/env python 2 # -*- coding: utf-8 -*- 3 import re,os,urllib.request,datetime 4 5 #url='https://tieba.baidu.com/p/6091256278' 6 def open_url(url): 7 req=urllib.request.Request(url) 8 req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) 9 Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") 10 response=urllib.request.urlopen(req).read() 11 return response 12 #print(open_url(url))
请忽略import的其他模块,下面再讲。这个请求非常标准了,模拟用户的请求,所有的爬虫都适用。add.header函数模拟了用户,防止服务器拒绝请求。
复制这段,去掉第5,第12行的#号,可以运行处结果。结果如下:
恩,没错就是这一堆乱码“源代码”。这是跟你在浏览器右键然后查看源代码的结果是一样的,只是这个更原始,没有转码,转码后会有汉字,稍微认识几个,但是也看不懂。
第二步说解析内容,这个比较重要,又非常复杂难懂的操作,上代码:
这里用到了re,os模块,之前import过的,文件操作模块,有兴趣百度多了解下,我也只是用能用到的几个函数。
1 def find_img(url): 2 html=open_url(url).decode('utf-8') 3 p=r'<img class="BDE_Image" src="([^"]+.jpg)"' 4 img_addrs=re.findall(p,html) 5 6 7 for each in img_addrs: 8 print(each) 9 for each in img_addrs: 10 file=each.split("/")[-1] 11 with open(file,"wb") as f: 12 img=open_url(each) 13 f.write(img)
第2行是源代码utf-8解码,结果是会有汉字,没有符号乱码了。
第3行是正则表达式,这是复杂的关键点,这个正则也是网络里找到的,用来匹配图片的地址,不多说,也说不出来,百度一下会教你如何放弃学习它,除非你是大神。
接着finall函数,在html的源代码里找符合正则表达式图片的网络地址,然后就是遍历下载下来。
最后一步使用with..open..as模式下载图片,放到文件夹里。
这里用到了datetime模块,用来获得系统的时间,然后我稍作处理一下,来以时间命名文件夹的名字,
1 def get_img(): 2 t1 = str(datetime.datetime.now()) 3 t = t1.replace(":", "-").replace(" ", "-")[0:19] 4 p = "D:TieBaPic-" + t 5 os.mkdir(p) 6 os.chdir(p) 7 find_img(url)
单独运行第2,3,4行,得到结果是:在D盘生成一个名字如下的文件夹,里面就是上一步下载的图片,名字会根据时间来定,不会重复。
D:TieBaPic-2019-04-11-16-50-33
第5,6行用到了os模块的两个函数,用来组合建立文件夹。
最后加上启动语句,就可以尝试爬虫了。
1 if __name__ =="__main__": 2 url='https://tieba.baidu.com/p/6091256278' 3 get_img()
这个双下划线的name函数,是一个变量,用来执行本程序的main,区别于import的模块,只有主程序是main,其他的都是导入的名字,并且
main是调用其他模块的关系,理解就行,没那么多讲究。
把所有的代码串起来就是完整的代码,运行结果如下:

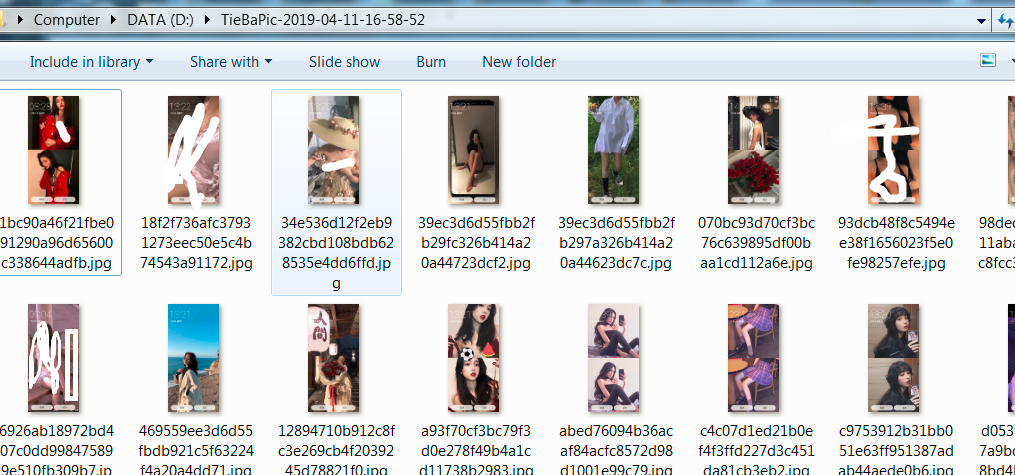
有些图片不太适合我们好学的氛围就P掉了。
以上就是我第一次的爬虫全过程,成功的爬出了图片,心里还是美滋滋的。
现在正在着手给python加个界面运行,等好了,发个随笔记录一下。