四、Pandas
- 简介
- Series
- DataFrame
- 时间对象处理
- 数据分组和聚合
- 其他常用方法
1、简介
pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。

Pandas的主要功能:
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
安装方法:
pip install pandas
引用方法:
import pandas as pd
2、Series
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
1、创建方法
第一种:
pd.Series([4,5,6,7,8])
执行结果:
0 4
1 5
2 6
3 7
4 8
dtype: int64
# 将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取值,跟之前学过的数组和列表一样
-----------------------------------------------
第二种:
pd.Series([4,5,6,7,8],index=['a','b','c','d','e'])
执行结果:
a 4
b 5
c 6
d 7
e 8
dtype: int64
# 自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
-----------------------------------------------
第三种:
pd.Series({"a":1,"b":2})
执行结果:
a 1
b 2
dtype: int64
# 指定索引
-----------------------------------------------
第四种:
pd.Series(0,index=['a','b','c'])
执行结果:
a 0
b 0
c 0
dtype: int64
# 创建一个值都是0的数组
-----------------------------------------------
对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series
缺失数据
- dropna() # 过滤掉值为NaN的行
- fill() # 填充缺失数据
- isnull() # 返回布尔数组,缺失值对应为True
- notnull() # 返回布尔数组,缺失值对应为False
# 第一步,创建一个字典,通过Series方式创建一个Series对象
st = {"sean":18,"yang":19,"bella":20,"cloud":21}
obj = pd.Series(st)
obj
运行结果:
sean 18
yang 19
bella 20
cloud 21
dtype: int64
# 第二步
a = {'sean','yang','cloud','rocky'} # 定义一个索引变量
#第三步
obj1 = pd.Series(st,index=a)
obj1 # 将第二步定义的a变量作为索引传入
# 运行结果:
rocky NaN
cloud 21.0
sean 18.0
yang 19.0
dtype: float64
# 因为rocky没有出现在st的键中,所以返回的是缺失值
通过上面的代码演示,对于缺失值已经有了一个简单的了解,接下来就来看看如何判断缺失值
1、
obj1.isnull() # 是缺失值返回Ture
运行结果:
rocky True
cloud False
sean False
yang False
dtype: bool
2、
obj1.notnull() # 不是缺失值返回Ture
运行结果:
rocky False
cloud True
sean True
yang True
dtype: bool
3、过滤缺失值 # 布尔型索引
obj1[obj1.notnull()]
运行结果:
cloud 21.0
yang 19.0
sean 18.0
dtype: float64

Series特性
- 从ndarray创建Series:Series(arr)
- 与标量(数字):sr * 2
- 两个Series运算
- 通用函数:np.ads(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean()、sum()、cumsum()
支持字典的特性:
- 从字典创建Series:Series(dic),
- In运算:'a'in sr、for x in sr
- 键索引:sr['a'],sr[['a','b','d']]
- 键切片:sr['a':'c']
- 其他函数:get('a',default=0)等
整数索引
pandas当中的整数索引对象可能会让初次接触它的人很懵逼,接下来通过代码演示:
sr = pd.Series(np.arange(10))
sr1 = sr[3:].copy()
sr1
运行结果:
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int32
# 到这里会发现很正常,一点问题都没有,可是当使用整数索引取值的时候就会出现问题了。因为在pandas当中使用整数索引取值是优先以标签解释的,而不是下标
sr1[1]
解决方法:
- loc属性 # 以标签解释
- iloc属性 # 以下标解释
sr1.iloc[1] # 以下标解释
sr1.loc[3] # 以标签解释
Series数据对齐
pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr2 = pd.Series([11,20,10], index=['d','c','a',])
sr1 + sr2
运行结果:
a 33
c 32
d 45
dtype: int64
# 可以通过这种索引对齐直接将两个Series对象进行运算
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1 + sr3
运行结果:
a 33.0
b NaN
c 32.0
d 45.0
dtype: float64
# sr1 和 sr3的索引不一致,所以最终的运行会发现b索引对应的值无法运算,就返回了NaN,一个缺失值
将两个Series对象相加时将缺失值设为0:
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1.add(sr3,fill_value=0)
运行结果:
a 33.0
b 14.0
c 32.0
d 45.0
dtype: float64
# 将缺失值设为0,所以最后算出来b索引对应的结果为14
灵活的算术方法:add,sub,div,mul
3、DataFrame

DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
创建方式:
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来形成DataFrame:
第一种:
pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
# 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列
运行结果:
one two
0 1 4
1 2 3
2 3 2
3 4 1
> 指定列
可以通过columns参数指定顺序排列
data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
pd.DataFrame(data,columns=['one','two'])
# 打印结果会按照columns参数指定顺序
第二种:
pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])})
运行结果:
one two
a 1 2
b 2 1
c 3 3
以上创建方法简单了解就可以,因为在实际应用当中更多是读数据,不需要自己手动创建
查看数据
常用属性和方法:
- index 获取行索引
- columns 获取列索引
- T 转置
- columns 获取列索引
- values 获取值索引
- describe 获取快速统计
one two
a 1 2
b 2 1
c 3 3
# 这样一个数组df
-----------------------------------------------------------------------------
df.index
运行结果:
Index(['a', 'b', 'c'], dtype='object')
----------------------------------------------------------------------------
df.columns
运行结果:
Index(['one', 'two'], dtype='object')
--------------------------------------------------------------------------
df.T
运行结果:
a b c
one 1 2 3
two 2 1 3
-------------------------------------------------------------------------
df.values
运行结果:
array([[1, 2],
[2, 1],
[3, 3]], dtype=int64)
------------------------------------------------------------------------
df.describe()
运行结果:
one two
count 3.0 3.0
mean 2.0 2.0
std 1.0 1.0
min 1.0 1.0
25% 1.5 1.5
50% 2.0 2.0
75% 2.5 2.5
max 3.0 3.0
索引和切片
- DataFrame有行索引和列索引。
- DataFrame同样可以通过标签和位置两种方法进行索引和切片。
DataFrame使用索引切片:
- 方法1:两个中括号,先取列再取行。 df['A'][0]
- 方法2(推荐):使用loc/iloc属性,一个中括号,逗号隔开,先取行再取列。
- loc属性:解释为标签
- iloc属性:解释为下标
- 向DataFrame对象中写入值时只使用方法2
- 行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配。(注意:两部分都是花式索引时结果可能与预料的不同)

4、时间对象处理
时间序列类型
- 时间戳:特定时刻
- 固定时期:如2019年1月
- 时间间隔:起始时间-结束时间
Python库:datatime
- date、time、datetime、timedelta
- dt.strftime()
- strptime()
灵活处理时间对象:dateutil包
- dateutil.parser.parse()
import dateutil
dateutil.parser.parse("2019 Jan 2nd") # 这中间的时间格式一定要是英文格式
运行结果:
datetime.datetime(2019, 1, 2, 0, 0)
成组处理时间对象:pandas
- pd.to_datetime(['2018-01-01', '2019-02-02'])
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
运行结果:
DatetimeIndex(['2018-03-01', '2019-02-03', '2019-08-12'], dtype='datetime64[ns]', freq=None) # 产生一个DatetimeIndex对象
# 转换时间索引
ind = pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
sr = pd.Series([1,2,3],index=ind)
sr
运行结果:
2018-03-01 1
2019-02-03 2
2019-08-12 3
dtype: int64
通过以上方式就可以将索引转换为时间
补充:
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019']).to_pydatetime()
运行结果:
array([datetime.datetime(2018, 3, 1, 0, 0),
datetime.datetime(2019, 2, 3, 0, 0),
datetime.datetime(2019, 8, 12, 0, 0)], dtype=object)
# 通过to_pydatetime()方法将其转换为array数组
产生时间对象数组:data_range
- start 开始时间
- end 结束时间
- periods 时间长度
- freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…
pd.date_range("2019-1-1","2019-2-2")
运行结果:
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07', '2019-01-08',
'2019-01-09', '2019-01-10', '2019-01-11', '2019-01-12',
'2019-01-13', '2019-01-14', '2019-01-15', '2019-01-16',
'2019-01-17', '2019-01-18', '2019-01-19', '2019-01-20',
'2019-01-21', '2019-01-22', '2019-01-23', '2019-01-24',
'2019-01-25', '2019-01-26', '2019-01-27', '2019-01-28',
'2019-01-29', '2019-01-30', '2019-01-31', '2019-02-01',
'2019-02-02'],
dtype='datetime64[ns]', freq='D')
时间序列
时间序列就是以时间对象为索引的Series或DataFrame。datetime对象作为索引时是存储在DatetimeIndex对象中的。
# 转换时间索引
dt = pd.date_range("2019-01-01","2019-02-02")
a = pd.DataFrame({"num":pd.Series(random.randint(-100,100) for _ in range(30)),"date":dt})
# 先生成一个带有时间数据的DataFrame数组
a.index = pd.to_datetime(a["date"])
# 再通过index修改索引
特殊功能:
- 传入“年”或“年月”作为切片方式
- 传入日期范围作为切片方式
- 丰富的函数支持:resample(), strftime(), ……
- 批量转换为datetime对象:to_pydatetime()
a.resample("3D").mean() # 计算每三天的均值
a.resample("3D").sum() # 计算每三天的和
...
5、数据分组和聚合
在数据分析当中,我们有时需要将数据拆分,然后在每一个特定的组里进行运算,这些操作通常也是数据分析工作中的重要环节。
本章学习内容:
- 分组(GroupBY机制)
- 聚合(组内应用某个函数)
- apply
- 透视表和交叉表
5.1、分组(GroupBY机制)
插图:恶搞图03

pandas对象(无论Series、DataFrame还是其他的什么)当中的数据会根据提供的一个或者多个键被拆分为多组,拆分操作实在对象的特定轴上执行的。就比如DataFrame可以在他的行上或者列上进行分组,然后将一个函数应用到各个分组上并产生一个新的值。最后将所有的执行结果合并到最终的结果对象中。
分组键的形式:
- 列表或者数组,长度与待分组的轴一样
- 表示DataFrame某个列名的值。
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或者索引中的各个标签吗
后三种只是快捷方式,最终仍然是为了产生一组用于拆分对象的值。
首先,通过一个很简单的DataFrame数组尝试一下:
df = pd.DataFrame({'key1':['x','x','y','y','x',
'key2':['one','two','one',',two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
运行结果:
key1 key2 data1 data2
0 x one 0.951762 1.632336
1 x two -0.369843 0.602261
2 y one 1.512005 1.331759
3 y ,two 1.383214 1.025692
4 x one -0.475737 -1.182826
访问data1,并根据key1调用groupby:
f1 = df['data1'].groupby(df['key1'])
f1
运行结果:
<pandas.core.groupby.groupby.SeriesGroupBy object at 0x00000275906596D8>
上述运行是没有进行任何计算的,但是我们想要的中间数据已经拿到了,接下来,就可以调用groupby进行任何计算
f1.mean() # 调用mean函数求出平均值
运行结果:
key1
x 0.106183
y 2.895220
Name: data1, dtype: float64
以上数据经过分组键(一个Series数组)进行了聚合,产生了一个新的Series,索引就是key1列中的唯一值。这些索引的名称就为key1。接下来就尝试一次将多个数组的列表传进来
f2 = df['data1'].groupby([df['key1'],df['key2']])
f2.mean()
运行结果:
key1 key2
x one 0.083878
two 0.872437
y one -0.665888
two -0.144310
Name: data1, dtype: float64
传入多个数据之后会发现,得到的数据具有一个层次化的索引,key1对应的xy;key2对应的one wo.
f2.mean().unstack()
运行结果:
key2 one two
key1
x 0.083878 0.872437
y -0.665888 -0.144310
# 通过unstack方法就可以让索引不堆叠在一起了
补充:
- 1、分组键可以是任意长度的数组
- 2、分组时,对于不是数组数据的列会从结果中排除,例如key1、key2这样的列
- 3、GroupBy的size方法,返回一个含有分组大小的Series
# 以上面的f2测试
f2.size()
运行结果:
key1 key2
x one 2
two 1
y one 1
two 1
Name: data1, dtype: int64
5.2、聚合(组内应用某个函数)
插图:恶搞图04

聚合是指任何能够从数组产生标量值的数据转换过程。刚才上面的操作会发现使用GroupBy并不会直接得到一个显性的结果,而是一个中间数据,可以通过执行类似mean、count、min等计算得出结果,常见的还有一些:
| 函数名 | 描述 | |
|---|---|---|
| sum | 非NA值的和 | |
| median | 非NA值的算术中位数 | |
| std、var | 无偏(分母为n-1)标准差和方差 | |
| prod | 非NA值的积 | |
| first、last | 第一个和最后一个非NA值 |
自定义聚合函数
不仅可以使用这些常用的聚合运算,还可以自己自定义。
# 使用自定义的聚合函数,需要将其传入aggregate或者agg方法当中
def peak_to_peak(arr):
return arr.max() - arr.min()
f1.aggregate(peak_to_peak)
运行结果:
key1
x 3.378482
y 1.951752
Name: data1, dtype: float64
多函数聚合:
f1.agg(['mean','std'])
运行结果:
mean std
key1
x -0.856065 0.554386
y -0.412916 0.214939
最终得到的列就会以相应的函数命名生成一个DataFrame数组
5.3、apply

GroupBy当中自由度最高的方法就是apply,它会将待处理的对象拆分为多个片段,然后各个片段分别调用传入的函数,最后将它们组合到一起。
df.apply(
['func', 'axis=0', 'broadcast=None', 'raw=False', 'reduce=None', 'result_type=None', 'args=()', '**kwds']
func:传入一个自定义函数
axis:函数传入参数当axis=1就会把一行数据作为Series的数据
# 分析欧洲杯和欧洲冠军联赛决赛名单
import pandas as pd
url="https://en.wikipedia.org/wiki/List_of_European_Cup_and_UEFA_Champions_League_finals"
eu_champions=pd.read_html(url) # 获取数据
a1 = eu_champions[2] # 取出决赛名单
a1.columns = a1.loc[0] # 使用第一行的数据替换默认的横向索引
a1.drop(0,inplace=True) # 将第一行的数据删除
a1.drop('#',axis=1,inplace=True) # 将以#为列名的那一列删除
a1.columns=['Season', 'Nation', 'Winners', 'Score', 'Runners_up', 'Runners_up_Nation', 'Venue','Attendance'] # 设置列名
a1.tail() # 查看后五行数据
a1.drop([64,65],inplace=True) # 删除其中的缺失行以及无用行
a1
运行结果:

现在想根据分组选出Attendance列中值最高的三个。
# 先自定义一个函数
def top(df,n=3,column='Attendance'):
return df.sort_values(by=column)[-n:]
top(a1,n=3)
运行结果:

接下来,就对a1分组并且使用apply调用该函数:
a1.groupby('Nation').apply(top)
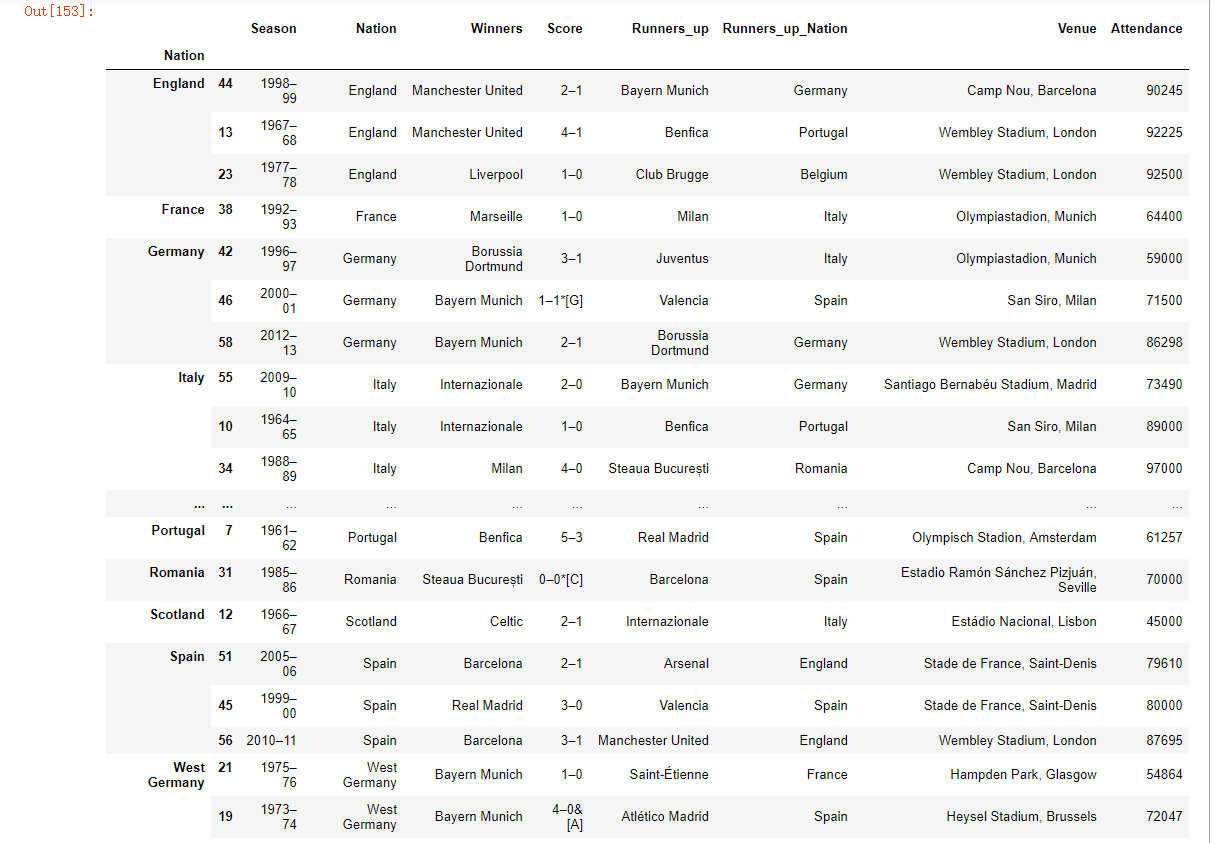
运行之后会发现,我们通过这个操作将每个国家各个年份时段出席的人数的前三名进行了一个提取。
以上top函数是在DataFrame的各个片段上调用,然后结果又通过pandas.concat组装到一起,并且以分组名称进行了标记。
以上只是基本用法,apply的强大之处就在于传入函数能做什么都由自己说了算,它只是返回一个pandas对象或者标量值就行

6、其他常用方法
pandas常用方法(适用Series和DataFrame)
- mean(axis=0,skipna=False)
- sum(axis=1)
- sort_index(axis, …, ascending) # 按行或列索引排序
- sort_values(by, axis, ascending) # 按值排序
- apply(func, axis=0) # 将自定义函数应用在各行或者各列上,func可返回标量或者Series
- applymap(func) # 将函数应用在DataFrame各个元素上
- map(func) # 将函数应用在Series各个元素上