在上节socket编程中,我们介绍了一些TCP/IP方面的必备知识,以及如何通过Python实现一个简单的socket服务端和客户端,并用它来解决“粘包”的问题。本章介绍网络编程中的几个概念:多线程、多进程以及网络编程IO模型
概述
默认应用程序:是单进程、单线程的。
进程是资源分配的最小单位。与程序相比,程序只是一组指令的有序集合,它本身没有任何运行的含义,只是一个静态实体。进程是程序在某个数据集上的执行,是一个动态实体。它因创建而产生,因调度而运行,因等待资源或事件而被处于等待状态,因完成任务而被撤消,反映了一个程序在一定的数据集上运行的全部动态过程。每个正在系统上运行的程序都是一个进程。每个进程包含一到多个线程。进程也可能是整个程序或者是部分程序的动态执行。
线程是轻量级的进程或子进程,是CPU调度的最小单位,所有的线程都存在于相同的进程。所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。通常由操作系统负责多个线程的调度和执行。多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。
由于Python中GIL的存在,GIL 会在进程级别加的一个逻辑锁,这个锁粒度很大,把整个系统资源看做一个整体,所以GIL 不管你有多少CPU核心,都看做一个CPU核心来用,虽然单进程多线程的程序拥有多个线程,但是同一时间之会有一个线程利用到CPU资源。因此为了提高CPU利用率,通常会启用多进程,即启动多个Python进程来提高CPU的利率用,从而提高工作效率。
对比
|
对比维度 |
多进程 |
多线程 |
总结 |
|
数据共享、同步 |
数据共享复杂,需要用IPC;数据是分开的,同步简单 |
因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 |
各有优势 |
|
内存、CPU |
占用内存多,切换复杂,CPU利用率低 |
占用内存少,切换简单,CPU利用率高 |
线程占优 |
|
创建销毁、切换 |
创建销毁、切换复杂,速度慢 |
创建销毁、切换简单,速度很快 |
线程占优 |
|
编程、调试 |
编程简单,调试简单 |
编程复杂,调试复杂 |
进程占优 |
|
可靠性 |
进程间不会互相影响 |
一个线程挂掉将导致整个进程挂掉 |
进程占优 |
|
分布式 |
适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 |
适应于多核分布式 |
进程占优 |
选用
单进程,多线程的程序(io操作不占用CPU):如果是CPU密集型,那么则不能提高效率。如果是IO密集型,那么则能提高效率。
多进程,单线程的程序:CPU密集型的,一般用多进程提高并发效率。
小结:
CPU密集型:多进程
IO密集型:多线程
一个多并发案例


import socketserver class MyServer(socketserver.BaseRequestHandler): def handle(self): pass if __name__ == '__main__': obj = socketserver.ThreadingTCPServer(('127.0.0.1', 8888), MyServer) obj.serve_forever()
如果自己去实现一个支持多并发的socket服务端,无疑是一件非常很繁琐的事情,需要用到select/poll/epoll等知识,但是,上边的代码中,利用了socketserver这个模块就轻松的实现了一个支持多并发的server端,下面来一起分析下这个socket服务端运行起来,到底做了哪些事项:
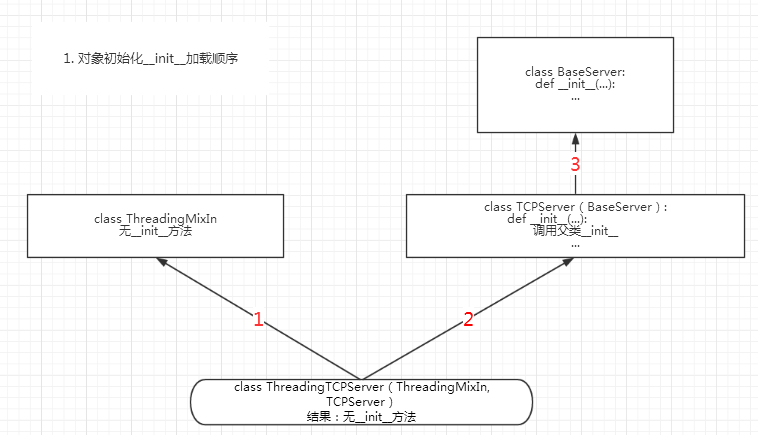
1. 在实例化的时候,会调用socketserver.ThreadingTCPServer(...)的__init__方法,加载顺序如下
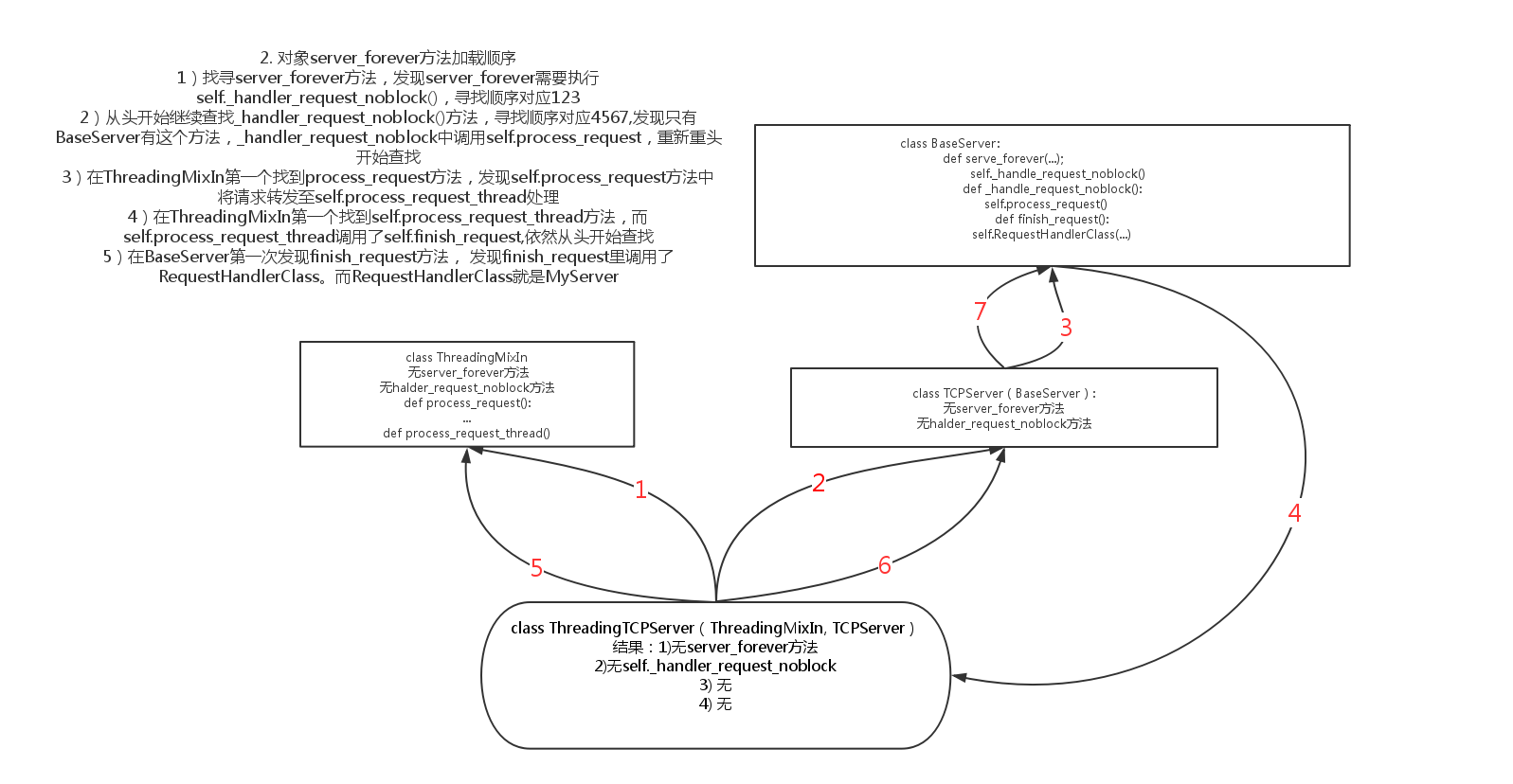
2. 调用对象的serve_forever方法
3. 最终进入自定义的类MyServer处理环节:从第二部最后一步中,执行了self.self.RequestHandlerClass(request, client_address, self),即创建了一个MyServer的实例,那么在实例化的时候,就会执行MyServer类的__init__方法。明显地,MyServer中没有定义__init__方法,那么从父类的__init__方法中继承。
发现在socketserver.BaseRequestHandler类中,__init__包含如下代码
def __init__(self, request, client_address, server): self.request = request self.client_address = client_address self.server = server self.setup() try: self.handle() finally: self.finish()
发现会调用self.handler()方法,最终又回到了MyServer定义的handler方法中,来处理客户端请求。
至此,socketserver源码简单剖析完毕。
扩展: Threading模块
上边剖析代码的时候,看到了与线程相关的一个模块Threading,是一个非常重要模块,下面对这个模块进行介绍.有两种方式来创建线程:一种是通过继承Thread类,重写它的run方法;另一种是创建一个threading.Thread对象,在它的初始化函数(__init__)中将可调用对象作为参数传入。下面介绍第二种,第一种以后增加:
import threading import time def worker(): time.sleep(2) print("test") for i in range(5): t = threading.Thread(target=worker) t.start()
从上边可以看出,创建一个多线程程序,只需要3步:
1. 创建执行函数
2. 创建threading.Thread对象
def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None): """This constructor should always be called with keyword arguments. Arguments are: *group* should be None; reserved for future extension when a ThreadGroup # 为了将来拓展保留的 class is implemented. *target* is the callable object to be invoked by the run() method. Defaults to None, meaning nothing is called. # 一个可调用程序,在线程启动后执行 *name* is the thread name. By default, a unique name is constructed of the form "Thread-N" where N is a small decimal number. # 线程的名字,默认值为“Thread-N“,N是一个数字 *args* is the argument tuple for the target invocation. Defaults to (). # 参数args表示调用target时的参数列表 *kwargs* is a dictionary of keyword arguments for the target invocation. Defaults to {}. # 参数kwargs表示调用target时的关键字参数。 If a subclass overrides the constructor, it must make sure to invoke the base class constructor (Thread.__init__()) before doing anything else to the thread. """
3. 启动线程
其他几个重要方法
1) threading.Thread.join([timeout])
调用Thread.join将会使主调线程堵塞,直到被调用线程运行结束或超时。参数timeout是一个数值类型,表示最多等待超时时间,如果未提供该参数,那么主调线程将一直堵塞到被调线程结束。
2)threading.Thread.getName() Thread.setName() Thread.name
用于获取和设置线程的名称。
3)threading.Thread.start()
开始一个新的线程
"""Start the thread's activity. It must be called at most once per thread object. It arranges for the object's run() method to be invoked in a separate thread of control. This method will raise a RuntimeError if called more than once on the same thread object. """
4)threading.Thread.run()
通常需要重写,编写代码实现做需要的功能。源码中start方法里调用了 self._start_new_thread(self._bootstrap, ()) , 而self_bootstrap 里边调用了 self._bootstrap_inner(), self._bootstrap_inner()里边又调用了self.run() 。而self.run里边,执行了self._target(*self._args, **self._kwargs),即在初始化的时候__init__中的target变量赋予的函数。最终执行的依然是target变量对应的函数。注:在通过继承Thread类来编写多线程的时候一般通过这个方法调用。
5)threading.Thread.setDaemon([True|False])
默认为Flase,参数设置为True的话会将线程声明为守护线程,必须在start() 方法之前设置
6) threading.Thread.isDaemon()
判断线程属于守护线程(True表示是),是否随主线程一起结束(True表示不随主线程一起结束,False表示一起结束)。
7)threading.Thread.isAlive()
检查线程是否在运行中
IO多路复用
I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
IO多路复用适用如下场合:
(1)当客户处理多个描述符时(一般是交互式输入和网络套接口),必须使用I/O复用。
(2)当一个客户同时处理多个套接口时,而这种情况是可能的,但很少出现。
(3)如果一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用。
(4)如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用。
(5)如果一个服务器要处理多个服务或多个协议,一般要使用I/O复用。
注:IO多路复用不支持文件操作,支持其他IO操作,监控内部是否发生变化
与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
http://www.zhihu.com/question/32163005 这个链接里深入的介绍了IO多路复用的起源以及核心原理,这里不再赘述。
其中重要的三项复用技术就是:select,poll,epoll
select,poll,epoll简介
|
Select |
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是: 1 单个进程可监视的fd数量被限制 2 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大 3 对socket进行扫描时是线性扫描 |
|
Poll |
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。 它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。 |
|
Epoll |
epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。 在前面说到的复制问题上,epoll使用mmap减少复制开销。 还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知 |
注:水平触发(level-triggered)——只要满足条件,就触发一个事件(只要有数据没有被获取,内核就不断通知你)
边缘触发(edge-triggered)——每当状态变化时,触发一个事件。
|
Select |
Poll |
Epoll |
|
|
支持最大连接数 |
1024 |
无上限 |
无上限 |
|
IO效率 |
每次调用进行线性遍历,时间复杂度为O(N) |
每次调用进行线性遍历,时间复杂度为O(N) |
使用“事件”通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到rdllist里面,这样epoll_wait返回的时候我们就拿到了就绪的fd。时间发复杂度O(1) |
|
fd拷贝 |
每次select都拷贝 |
每次poll都拷贝 |
调用epoll_ctl时拷贝进内核并由内核保存,之后每次epoll_wait不拷贝 |
Python中用select模块实现伪并发
版本1:简单的伪并发
import socket import select sk = socket.socket() sk.bind(('127.0.0.01', 9999)) sk.listen(5) inputs = [sk, ] while True: rlist, wlist, e, = select.select(inputs, [], [], 1) # 监听sk对象,如果sk对象发生变化,表示有客户端连接来了,此时rlist为[sk,] # 监听conn对象,如果conn发生变化,表示客户端有新消息发送过来了,此时rlist为【客户端】 # 1 表示检测间隔 print(len(inputs), len(rlist)) # rlist中是socket对象列表 for r in rlist: if r == sk: # 新客户端来连接 conn, address = r.accept() # conn是什么? 其实socket对象 inputs.append(conn) conn.sendall(bytes('hello',encoding='utf8')) else: # 有人给我发消息了 try: # 捕捉客户端断开连接异常 ret = r.recv(1024) r.sendall(ret) # 这里也可以给客户端发送消息,但是不推荐,这样读写混淆到一起了。推荐使用读写分离的写法 if not ret: # 捕捉不同系统的客户端断开连接 raise Exception except Exception as e: inputs.remove(r)
import socket import select sk = socket.socket() sk.bind(('127.0.0.01', 9999)) sk.listen(5) inputs = [sk, ] outputs = [] # 包含了所有给我发消息的人 while True: # rlist, w, e, = select.select([sk,], [], [],) rlist, wlist, e, = select.select(inputs, outputs, [], 1) # 监听sk对象,如果sk对象发生变化,表示有客户端连接来了,此时rlist为[sk,] # 监听conn对象,如果conn发生变化,表示客户端有新消息发送过来了,此时rlist为【客户端】 # 1 表示检测间隔 print(len(inputs), len(rlist), len(wlist), len(outputs)) # rlist中是socket对象列表 for r in rlist: if r == sk: # 新客户端来连接 conn, address = r.accept() # conn是什么? 其实socket对象 inputs.append(conn) conn.sendall(bytes('hello',encoding='utf8')) else: # 有人给我发消息了 print("=========") try: # 捕捉客户端断开连接异常 ret = r.recv(1024) if not ret: # 捕捉不同系统的客户端断开连接 raise Exception("断开连接") else: outputs.append(r) except Exception as e: inputs.remove(r) # 循环所有给我发消息的人 for w in wlist: w.sendall(bytes('response', encoding='utf8')) outputs.remove(w)
import socket import select sk = socket.socket() sk.bind(('127.0.0.01', 9999)) sk.listen(5) inputs = [sk, ] outputs = [] # 包含了所有给我发消息的人 messages = {} # 消息队列 # messages = { sk1:[], sk2: [], sk3: [].....} while True: # rlist, w, e, = select.select([sk,], [], [],) rlist, wlist, e, = select.select(inputs, outputs, [], 1) # 监听sk对象,如果sk对象发生变化,表示有客户端连接来了,此时rlist为[sk,] # 监听conn对象,如果conn发生变化,表示客户端有新消息发送过来了,此时rlist为【客户端】 # 1 表示检测间隔 print(len(inputs), len(rlist), len(wlist), len(outputs)) # rlist中是socket对象列表 for r in rlist: if r == sk: # 新客户端来连接 conn, address = r.accept() # conn是什么? 其实socket对象 inputs.append(conn) messages[conn] = [] conn.sendall(bytes('hello',encoding='utf8')) else: # 有人给我发消息了 print("=========") try: # 捕捉客户端断开连接异常 ret = r.recv(1024) if not ret: # 捕捉不同系统的客户端断开连接 raise Exception("断开连接") else: outputs.append(r) messages[r].append(ret) except Exception as e: inputs.remove(r) # 记住: 要如果断开,要清空message对应对象的key del messages[r] # 循环所有给我发消息的人 for w in wlist: msg = messages[w].pop() msg += bytes('response', encoding='utf8') w.sendall(msg) outputs.remove(w)