本文整理自多材料源,感谢原址分享,请查看末尾Url
I, 汇编语言分类:
汇编语言和CPU息息相关,但是不能把汇编语言完全等同于CPU的机器指令。不同架构的CPU指令并不相同,如x86,powerpc,arm各有各的指令系统;甚至同一种架构的CPU有几套指令集,典型的如arm除了有32位的指令集外,还有一套16位的thumb指令集。但是作为开发语言的汇编,本质上是一套语法规则和助记符的集合,它可以包容不同的指令集。如果从CPU体系来划分,常见的汇编有两种:IBM PC汇编和ARM汇编。
IBM PC汇编也就是Intel的汇编,因为IBM 最早推出PC机,后来的体系很多都要和它兼容,所以也使用了相同的汇编语言。ARM压根没考虑过兼容,它的指令集和x86完全是两个体系,所以汇编语言也独立发展出一套。
CPU只是限定了机器码,作为开发语言的汇编,其实还和编译器息息相关。汇编语言出现的早,没有像C语言一样定义出标准,所以编译器的厂商各搞一套。到现在,最有名的也是两家:MASM和GNU ASM。前者是微软的,只支持x86,用在DOS/Windows平台中;后者是开源产品,主要用在Linux中,基本上支持大部分的CPU架构。这两者的区别在于伪指令的不同,伪指令是用来告诉编译器如何工作的,和编译器相关,和CPU无关。其实汇编的编译相当简单,这两套伪指令只是符号不相同,含义是大同小异,明白了一种,看另一种就很容易了。
从汇编格式分,还有Intel格式和AT&T格式的区别,前者是Intel的,windows平台常见,后者最早由贝尔实验室推出,用于Unix中,GUN汇编器的缺省格式就是AT&T。不过GNU的汇编器和调试器gdb对这两种格式都支持,可以随便切换。MASM只支持Intel格式。Intel格式和AT&T格式的区别只是符号系统的区别,这与x86和arm的区别可不一样,后者是CPU体系的区别。
所谓 内嵌汇编,它是用于C语言和汇编语言混合编程的,所以和编译器也关系紧密,目前也是有两种,GNU的内嵌汇编和MASM的内嵌汇编,它们的语法和普通汇编是有区别的,特别是GNU的内嵌汇编不是很容易看懂,需要专门学习才行。MASM的内嵌汇编和普通汇编的区别则不大。
关于汇编语言的种类,可以说有多少种不同内核的CPU,就有多少种汇编语言。汇编并不是只有8086/8088汇编,还有8051,ARM,Alpha,MIPS汇编等等...
如你所知, 汇编是一种面向机器的编程语言,之所以说面向机器是指它的指令系统与具体的CPU芯片相关联,通常不同CPU硬件有不同的汇编系统。8086&8088分别是Intel公司的16位和准16位的CPU,通常使用它作为教材讲解微机机系统原理,是因为80x86系列CPU应用广泛,具有代表性。
8051主要应用在单片机,ARM汇编用于ARM处理器...不需要解释。
8086是INTEL公司推出的最早实际应用到微型个人计算机上CPU芯片型号;80x86是在8086基础上的增强型,包括80286,80386,80486,其后就改称奔腾了。大的区别上:8086和80286是16位的CPU,80386和80486是32位CPU;80486还多了数学辅助处理器,增强了复杂的数学运算能力。小的区别上就比较多了,如频率越来越快,包括寄存器的增加等。
和C语言不同,汇编语言更多的针对特定CPU内核,因此,不同内核的CPU,必须有对应的汇编语言编译器将汇编语言别写的程序编译成对应CPU的机器语言代码,CPU才能正确识别和执行这些代码。
II, 寄存器概念
寄存器是CPU里的东西,内存是挂在CPU外面的数据总线上的,
访问内存时要在CPU的寄存器填上地址,再执行相应的汇编指令,这时CPU会在数据总线上生成读取或写入内存数据的时钟信号,最终内存的内容会被CPU寄存器的内容更新(写入)或被读入CPU的寄存器(读取)
不只是PC上的CPU,所有的嵌入式CPU,单片机都一个样
首先明确一点:
CPU <--- > 寄存器<--- > 缓存<--- >内存
寄存器的工作方式很简单,只有两步:(1)找到相关的位,(2)读取这些位。

内存的工作方式就要复杂得多:
(1)找到数据的指针。(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
(2)将指针送往内存管理单元(MMU),由MMU将虚拟的内存地址翻译成实际的物理地址。
(3)将物理地址送往内存控制器(memory controller),由内存控制器找出该地址在哪一根内存插槽(bank)上。
(4)确定数据在哪一个内存块(chunk)上,从该块读取数据。
(5)数据先送回内存控制器,再送回CPU,然后开始使用。
内存的工作流程比寄存器多出许多步。每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。
为了缓解寄存器与内存之间的巨大速度差异,硬件设计师做出了许多努力,包括在CPU内部设置缓存、优化CPU工作方式,尽量一次性从内存读取指令所要用到的全部数据等等。
寄存器、存储器、内存之间的关系:
存储器 涵盖了所有关于存储的范畴,寄存器和内存都属于该范畴。
寄存器是中央处理器内的组成部份。它跟CPU有关。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和位址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器(ACC)。
内存,即 内部存储器 ,一般分为只读存储器和随即存储器,以及最强悍的高速缓冲存储器(CACHE),只读存储器应用广泛,它通常是一块在硬件上集成的可读芯片,作用是识别与控制硬件,它的特点是只可读取,不能写入。随机存储器的特点是可读可写,断电后一切数据都消失,我们所说的内存条就是指它了。
CACHE是在CPU中速度非常块,而容量却很小的一种存储器,它是计算机存储器中最强悍的存储器。由于技术限制,容量很难提升,一般都不过兆。
因此,堆栈概念不应与寄存器混淆,堆Heap 栈 Stack 概念存在于程序的内存分配环节
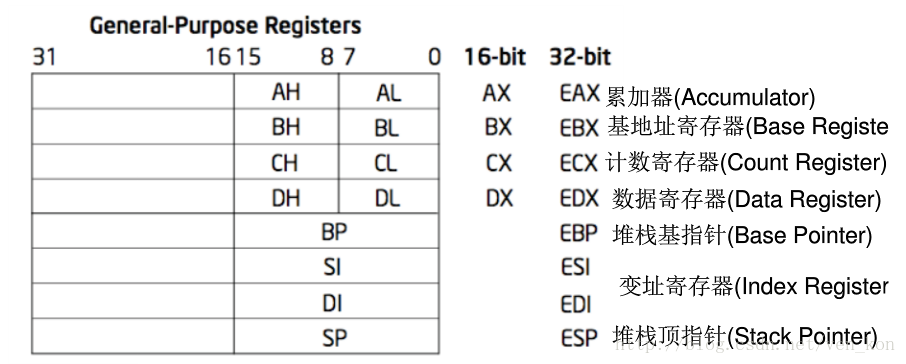
主要寄存器如下图所示:

X86处理器中有8个32位的通用寄存器。由于历史的原因,EAX通常用于计算,ECX通常用于循环变量计数。ESP和EBP有专门用途,ESP指示栈指针(用于指示栈顶位置),而EBP则是基址指针(用于指示子程序或函数调用的基址指针)。如图中所示,EAX、EBX、ECX和EDX的前两个高位字节和后两个低位字节可以独立使用,其中两位低字节又被独立分为H和L部分,这样做的原因主要是考虑兼容16位的程序,具体兼容匹配细节请查阅相关文献。
应用寄存器时,其名称大小写是不敏感的,如EAX和eax没有区别。
更详细一些的介绍图:
下面通过一个具体的C代码反汇编的汇编代码分析加深对这些常用代码的理解,实验环境是实验楼32位Linux虚拟机。
具体C代码如下:
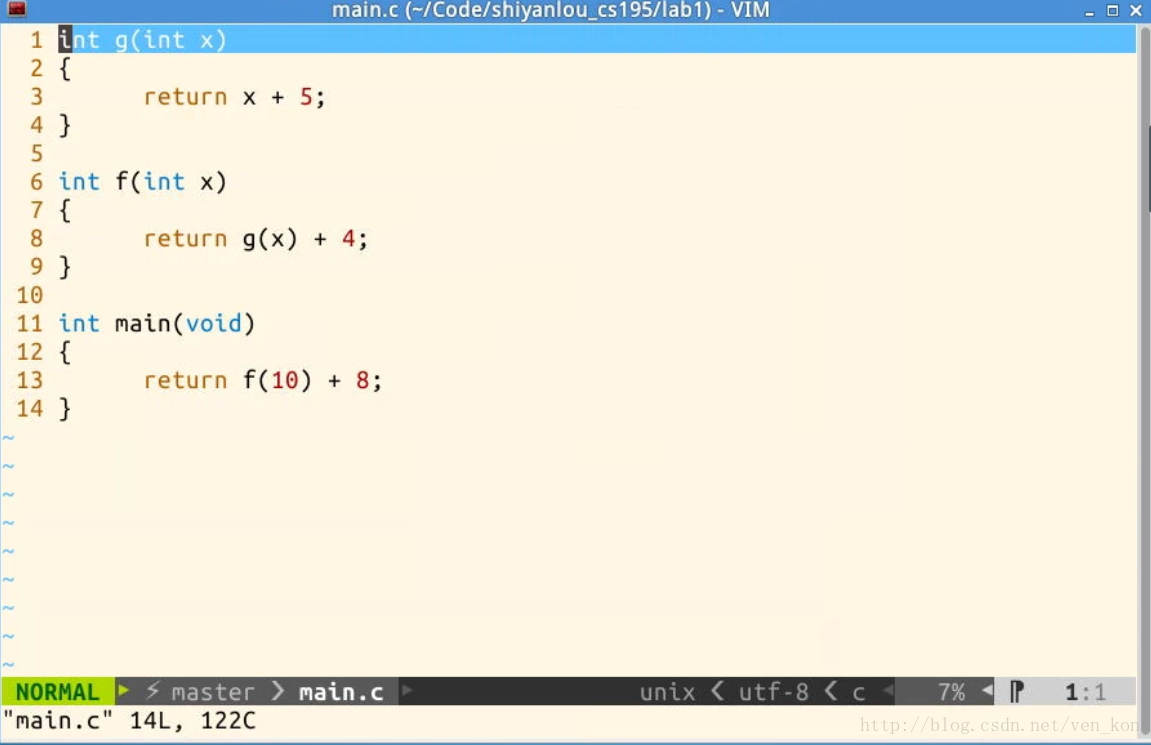
通过 gcc –S –o main.s main.c -m32 指令将代码编译成汇编代码,精简后的汇编代码如下:
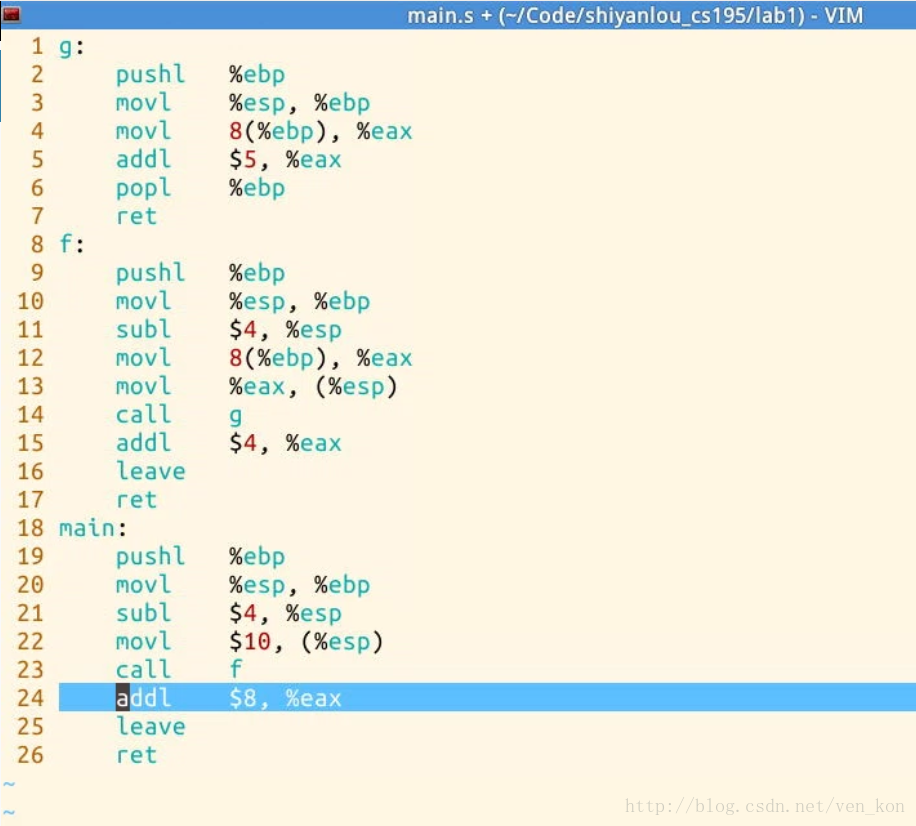
下面将着重分析上面这段代码。首先,汇编代码也是从main开始执行,首先将ebp寄存器值入栈,然后ebp指向esp位置,esp值减4之后将数字10存在esp指向的位置,最后调将eip入栈,同时eip指向函数f的起始位置。
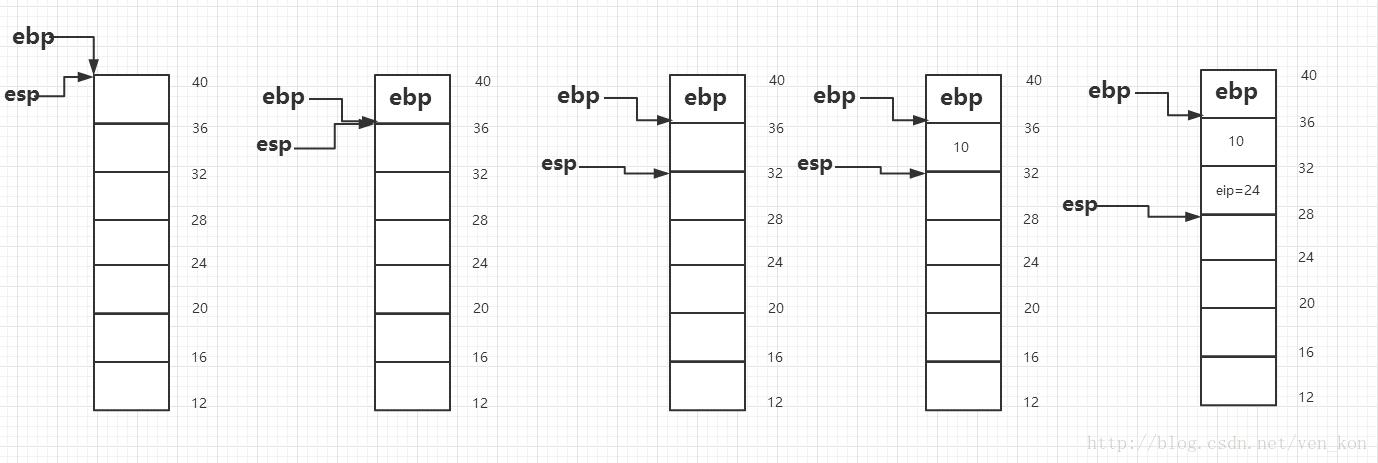
f函数首先也是ebp入栈,然后ebp指向esp位置,esp值减4之后将ebp位置加8位置的值,也就是数字10保存到eax寄存器中,然后将eax中的值也就是10保存到esp中,最后将eip入栈,调用函数g。
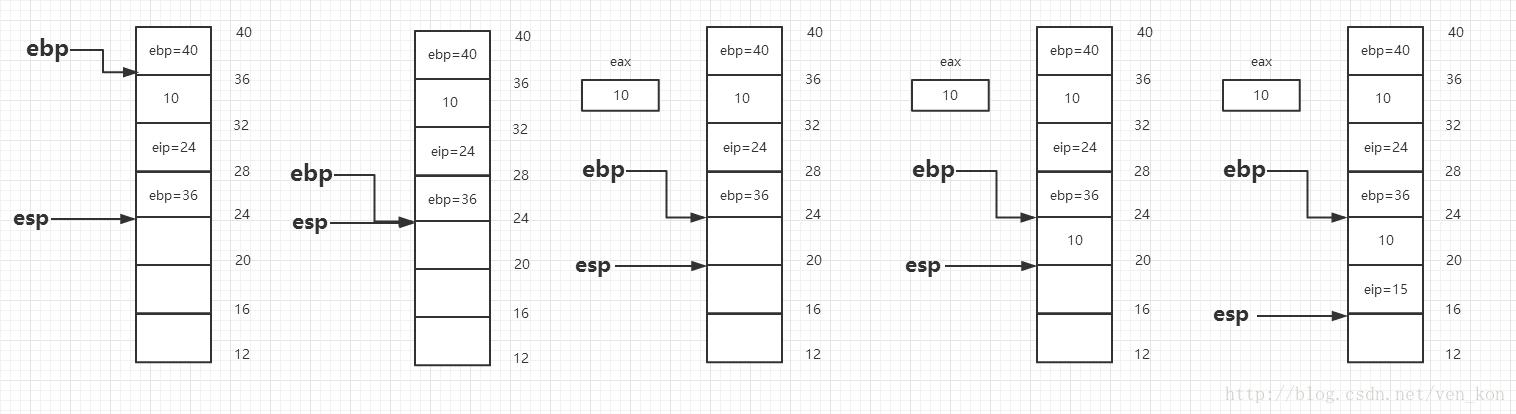
g函数也是相同的操作,ebp入栈,ebp指向esp位置,ebp地址减8处的值10放进eax,然后eax中的数值增加5,然后出栈到ebp,ebp只想24地址处。然后ret,也就是esp处值出栈到eip,eip=15。
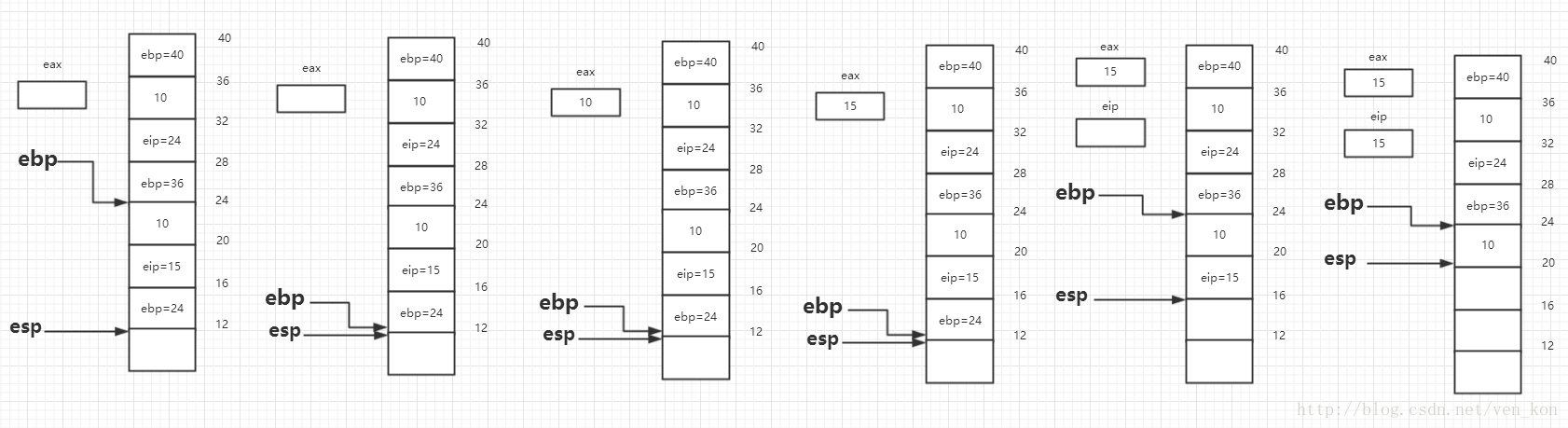
然后又回到f函数的15指令处执行,eax寄存器的值增加4,变成19,然后执行leave指令,也就是esp指向ebp处,然后esp处值出栈到ebp,然后esp处值出栈到eip,程序下面跳转至24行指令。
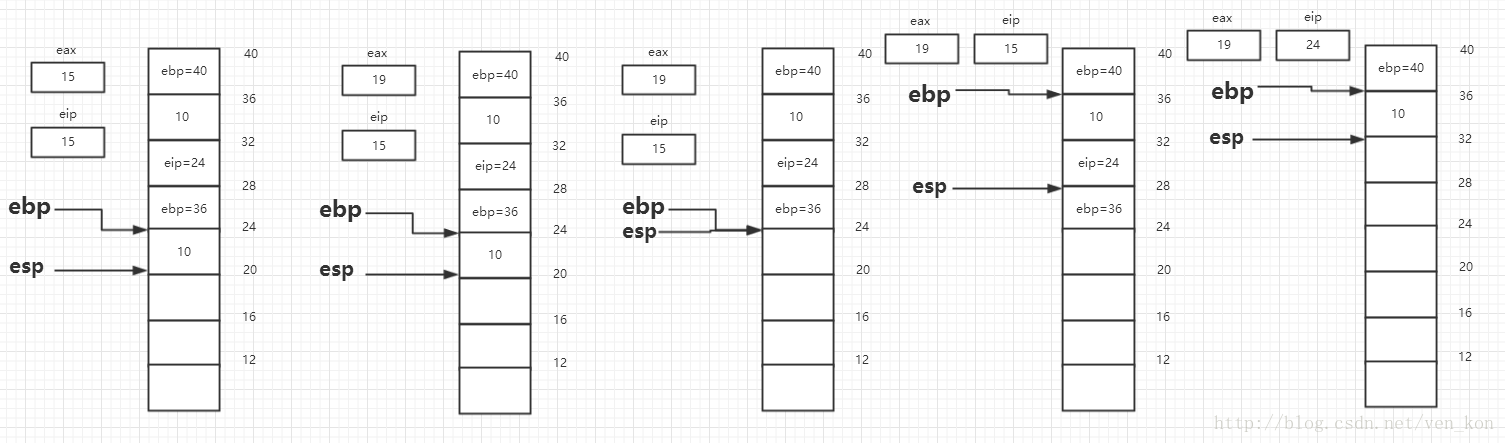
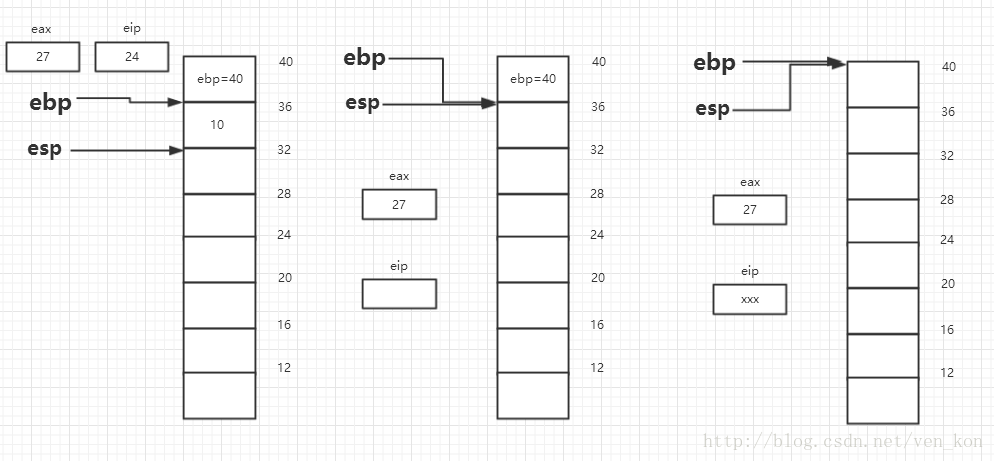
指令又回到main函数执行,首先eax值加8,变成27,然后执行leave指令,也就是esp指向ebp处,然后esp处值出栈到ebp,然后esp处值出栈到eip,程序下面跳转至main函数开始前的地方继续执行。
III, 内存和寻址模式
III.1声明静态数据区
可以在X86汇编语言中用汇编指令.DATA声明静态数据区(类似于全局变量),数据以单字节、双字节、或双字(4字节)的方式存放,分别用DB,DW, DD指令表示声明内存的长度。在汇编语言中,相邻定义的标签在内存中是连续存放的。
| .DATA | |||
| var | DB 64 | ;声明一个字节,并将数值64放入此字节中 | |
| var2 | DB ? | ; 声明一个为初始化的字节. | |
| DB 10 | ; 声明一个没有label的字节,其值为10. | ||
| X | DW ? | ; 声明一个双字节,未初始化. | |
| Y | DD 30000 | ; 声明一个4字节,其值为30000. |
还可以声明连续的数据和数组,声明数组时使用DUP关键字
| Z | DD 1, 2, 3 | ; Declare three 4-byte values, initialized to 1, 2, and 3. The value of location Z + 8 will be 3. |
| bytes | DB 10 DUP(?) | ; Declare 10 uninitialized bytes starting at location bytes. |
| arr | DD 100 DUP(0) | ; Declare 100 4-byte words starting at location arr, all initialized to 0 |
| str | DB 'hello',0 | ; Declare 6 bytes starting at the address str, initialized to the ASCII character values for hello and the null (0) byte. |
III,2 寻址模式
现代X86处理器具有232字节的寻址空间。在上面的例子中,我们用标签(label)表示内存区域,这些标签在实际汇编时,均被32位的实际地址代替。除了支持这种直接的内存区域描述,X86还提供了一种灵活的内存寻址方式,即利用最多两个32位的寄存器和一个32位的有符号常数相加计算一个内存地址,其中一个寄存器可以左移1、2或3位以表述更大的空间。下面例子是汇编程序中常见的方式
mov eax, [ebx] ; 将ebx值指示的内存地址中的4个字节传送到eax中 mov [var], ebx ; 将ebx的内容传送到var的值指示的内存地址中. mov eax, [esi-4] ; 将esi-4值指示的内存地址中的4个字节传送到eax中 mov [esi+eax], cl ; 将cl的值传送到esi+eax的值指示的内存地址中 mov edx, [esi+4*ebx] ; 将esi+4*ebx值指示的内存中的4个字节传送到edx
下面是违反规则的例子:
| mov eax, [ebx-ecx] | ; 只能用加法 |
| mov [eax+esi+edi], ebx | ; 最多只能有两个寄存器参与运算 |
III,3 长度规定
在声明内存大小时,在汇编语言中,一般用DB,DW,DD均可声明的内存空间大小,这种现实声明能够很好地指导汇编器分配内存空间,但是,对于
mov [ebx], 2
如果没有特殊的标识,则不确定常数2是单字节、双字节,还是双字。对于这种情况,X86提供了三个指示规则标记,分别为BYTE PTR, WORD PTR, and DWORD PTR,如上面例子写成:mov BYTE PTR [ebx], 2, mov WORD PTR [ebx], 2, mov DWORD PTR [ebx], 2,则意思非常清晰。
IV. 汇编指令
汇编指令通常可以分为数据传送指令、逻辑计算指令和控制流指令。本节将讲述其中最重要的指令,以下标记分别表示寄存器、内存和常数。
| <reg32> | 32位寄存器 (EAX, EBX, ECX, EDX, ESI, EDI, ESP, or EBP) |
| <reg16> | 16位寄存器 (AX, BX, CX, or DX) |
| <reg8> | 8位寄存器(AH, BH, CH, DH, AL, BL, CL, or DL) |
| <reg> | 任何寄存器 |
| <mem> | 内存地址 (e.g., [eax], [var + 4], or dword ptr [eax+ebx]) |
| <con32> | 32为常数 |
| <con16> | 16位常数 |
| <con8> | 8位常数 |
| <con> | 任何8位、16位或32位常数 |
IV. 1 数据传送指令
mov — Move (Opcodes: 88, 89, 8A, 8B, 8C, 8E, ...)
mov指令将第二个操作数(可以是寄存器的内容、内存中的内容或值)复制到第一个操作数(寄存器或内存)。mov不能用于直接从内存复制到内存,其语法如下所示:
mov <reg>,<reg>
mov <reg>,<mem>
mov <mem>,<reg>
mov <reg>,<const>
mov <mem>,<const>
Examples
mov eax, ebx — 将ebx的值拷贝到eax
mov byte ptr [var], 5 — 将5保存找var指示内存中的一个字节中
push— Push stack (Opcodes: FF, 89, 8A, 8B, 8C, 8E, ...)
push指令将操作数压入内存的栈中,栈是程序设计中一种非常重要的数据结构,其主要用于函数调用过程中,其中ESP只是栈顶。在压栈前,首先将ESP值减4(X86栈增长方向与内存地址编号增长方向相反),然后将操作数内容压入ESP指示的位置。其语法如下所示:
push <reg32>
push <mem>
push <con32>
Examples
push eax — 将eax内容压栈
push [var] — 将var指示的4直接内容压栈
pop— Pop stack
pop指令与push指令相反,它执行的是出栈的工作。它首先将ESP指示的地址中的内容出栈,然后将ESP值加4. 其语法如下所示:
pop <reg32>
pop <mem>
Examples
pop edi — pop the top element of the stack into EDI.
pop [ebx] — pop the top element of the
stack into memory at the four bytes starting at location EBX.
lea— Load effective address
lea实际上是一个载入有效地址指令,将第二个操作数表示的地址载入到第一个操作数(寄存器)中。其语法如下所示:
Syntax
lea <reg32>,<mem>
Examples
lea eax, [var] — var指示的地址载入eax中.
lea edi, [ebx+4*esi] — ebx+4*esi表示的地址载入到edi中,这实际是上面所说的寻址模式的一种表示方式.
IV. 2 算术和逻辑指令
add— Integer Addition
add指令将两个操作数相加,且将相加后的结果保存到第一个操作数中。其语法如下所示:
add <reg>,<reg>
add <reg>,<mem>
add <mem>,<reg>
add <reg>,<con>
add <mem>,<con>
Examples
add eax, 10 — EAX ← EAX + 10
add BYTE PTR [var], 10 — 10与var指示的内存中的一个byte的值相加,并将结果保存在var指示的内存中
sub— Integer Subtraction
sub指令指示第一个操作数减去第二个操作数,并将相减后的值保存在第一个操作数,其语法如下所示:
sub <reg>,<reg>
sub <reg>,<mem>
sub <mem>,<reg>
sub <reg>,<con>
sub <mem>,<con>
Examples
sub al, ah — AL ← AL - AH
sub eax, 216 — eax中的值减26,并将计算值保存在eax中
inc, dec— Increment, Decrement
inc,dec分别表示将操作数自加1,自减1,其语法如下所示:
inc <reg>
inc <mem>
dec <reg>
dec <mem>
Examples
dec eax — eax中的值自减1.
inc DWORD PTR [var] — var指示内存中的一个4-byte值自加1
imul— Integer Multiplication
整数相乘指令,它有两种指令格式,一种为两个操作数,将两个操作数的值相乘,并将结果保存在第一个操作数中,第一个操作数必须为寄存器;第二种格式为三个操作数,其语义为:将第二个和第三个操作数相乘,并将结果保存在第一个操作数中,第一个操作数必须为寄存器。其语法如下所示:
imul <reg32>,<reg32>
imul <reg32>,<mem>
imul <reg32>,<reg32>,<con>
imul <reg32>,<mem>,<con>
Examples
idiv— Integer Division
idiv指令完成整数除法操作,idiv只有一个操作数,此操作数为除数,而被除数则为EDX:EAX中的内容(一个64位的整数),操作的结果有两部分:商和余数,其中商放在eax寄存器中,而余数则放在edx寄存器中。其语法如下所示:
Syntax
idiv <reg32>
idiv <mem>
Examples
idiv ebx
idiv DWORD PTR [var]
and <reg>,<reg>
and <reg>,<mem>
and <mem>,<reg>
and <reg>,<con>
and <mem>,<con>
or <reg>,<reg>
or <reg>,<mem>
or <mem>,<reg>
or <reg>,<con>
or <mem>,<con>
xor <reg>,<reg>
xor <reg>,<mem>
xor <mem>,<reg>
xor <reg>,<con>
xor <mem>,<con>
Examples
and eax, 0fH — 将eax中的钱28位全部置为0,最后4位保持不变.
xor edx, edx — 设置edx中的内容为0.
not— Bitwise Logical Not
位翻转指令,将操作数中的每一位翻转,即0->1, 1->0。其语法如下所示:
not <reg>
not <mem>
Example
not BYTE PTR [var] — 将var指示的一个字节中的所有位翻转.
neg— Negate
取负指令。语法为:
neg <reg>
neg <mem>
Example
neg eax — EAX → - EAX
shl, shr— Shift Left, Shift Right
位移指令,有两个操作数,第一个操作数表示被操作数,第二个操作数指示位移的数量。其语法如下所示:
shl <reg>,<con8>
shl <mem>,<con8>
shl <reg>,<cl>
shl <mem>,<cl>
shr <reg>,<con8>
shr <mem>,<con8>
shr <reg>,<cl>
shr <mem>,<cl>
Examples
shl eax, 1 — Multiply the value of EAX by 2 (if the most significant bit is 0),左移1位,相当于乘以2
shr ebx, cl — Store in EBX the floor of result of dividing the value of EBX by 2n where n is the value in CL.
mov esi, [ebp+8]
begin: xor ecx, ecx
mov eax, [esi]
如第二条指令用begin指示,这种标签的方法在某种程度上简化了汇编程序设计,控制流指令通过标签实现程序指令跳转。
jmp — Jump
控制转移到label所指示的地址,(从label中取出执行执行),如下所示:
jmp <label>
Example
jmp begin — Jump to the instruction labeled begin.
jcondition— Conditional Jump
条件转移指令,条件转移指令依据机器状态字中的一些列条件状态转移。机器状态字中包括指示最后一个算数运算结果是否为0,运算结果是否为负数等。机器状态字具体解释请见微机原理、计算机组成等课程。语法如下所示:
je <label> (jump when equal)
jne <label> (jump when not equal)
jz <label> (jump when last result was zero)
jg <label> (jump when greater than)
jge <label> (jump when greater than or equal to)
jl <label> (jump when less than)
jle <label>(jump when less than or equal to)
Example
cmp eax, ebx
jle done , 如果eax中的值小于ebx中的值,跳转到done指示的区域执行,否则,执行下一条指令。
cmp <reg>,<reg>
cmp <reg>,<mem>
cmp <mem>,<reg>
cmp <reg>,<con>
Example
cmp DWORD PTR [var], 10
jeq loop,

在X86中,栈增长方向与内存编号增长方向相反。
Caller Rules
调用者规则包括一系列操作,描述如下:
1)在调用子程序之前,调用者应该保存一系列被设计为调用者保存的寄存器的值。调用者保存寄存器有eax,ecx,edx。由于被调用的子程序会修改这些寄存器,所以为了在调用子程序完成之后能正确执行,调用者必须在调用子程序之前将这些寄存器的值入栈。
2)在调用子程序之前,将参数入栈。参数入栈的顺序应该是从最后一个参数开始,如上图中parameter3先入栈。
3)利用call指令调用子程序。这条指令将返回地址放置在参数的上面,并进入子程序的指令执行。(子程序的执行将按照被调用者的规则执行)
当子程序返回时,调用者期望找到子程序保存在eax中的返回地址。为了恢复调用子程序执行之前的状态,调用者应该执行以下操作:
1)清除栈中的参数;
2)将栈中保存的eax值、ecx值以及edx值出栈,恢复eax、ecx、edx的值(当然,如果其它寄存器在调用之前需要保存,也需要完成类似入栈和出栈操作)
Example
如下代码展示了一个调用子程序的调用者应该执行的操作。此汇编程序调用一个具有三个参数的函数_myFunc,其中第一个参数为eax,第二个参数为常数216,第三个参数为var指示的内存中的值。
push [var] ; Push last parameter first
push 216 ; Push the second parameter
push eax ; Push first parameter last
call _myFunc ; Call the function (assume C naming)
add esp, 12
在调用返回时,调用者必须清除栈中的相应内容,在上例中,参数占有12个字节,为了消除这些参数,只需将ESP加12即可。
_myFunc的值保存在eax中,ecx和edx中的值也许已经被改变,调用者还必须在调用之前保存在栈中,并在调用结束之后,出栈恢复ecx和edx的值。
VI, 被调用者规则
被调用者应该遵循如下规则:
1)将ebp入栈,并将esp中的值拷贝到ebp中,其汇编代码如下:
push ebp
mov ebp, esp
上述代码的目的是保存调用子程序之前的基址指针,基址指针用于寻找栈上的参数和局部变量。当一个子程序开始执行时,基址指针保存栈指针指示子程序的执行。为了在子程序完成之后调用者能正确定位调用者的参数和局部变量,ebp的值需要返回。
2)在栈上为局部变量分配空间。
3)保存callee-saved寄存器的值,callee-saved寄存器包括ebx,edi和esi,将ebx,edi和esi压栈。
4)在上述三个步骤完成之后,子程序开始执行,当子程序返回时,必须完成如下工作:
4.1)将返回的执行结果保存在eax中
4.2)弹出栈中保存的callee-saved寄存器值,恢复callee-saved寄存器的值(ESI和EDI)
4.3)收回局部变量的内存空间。实际处理时,通过改变EBP的值即可:mov esp, ebp。
4.4)通过弹出栈中保存的ebp值恢复调用者的基址寄存器值。
4.5)执行ret指令返回到调用者程序。
After these three actions are performed, the body of the subroutine may proceed. When the subroutine is returns, it must follow these steps:
- Leave the return value in EAX.
Example
.486
.MODEL FLAT
.CODE
PUBLIC _myFunc
_myFunc PROC
; Subroutine Prologue
push ebp ; Save the old base pointer value.
mov ebp, esp ; Set the new base pointer value.
sub esp, 4 ; Make room for one 4-byte local variable.
push edi ; Save the values of registers that the function
push esi ; will modify. This function uses EDI and ESI.
; (no need to save EBX, EBP, or ESP)
; Subroutine Body
mov eax, [ebp+8] ; Move value of parameter 1 into EAX
mov esi, [ebp+12] ; Move value of parameter 2 into ESI
mov edi, [ebp+16] ; Move value of parameter 3 into EDI
mov [ebp-4], edi ; Move EDI into the local variable
add [ebp-4], esi ; Add ESI into the local variable
add eax, [ebp-4] ; Add the contents of the local variable
; into EAX (final result)
; Subroutine Epilogue
pop esi ; Recover register values
pop edi
mov esp, ebp ; Deallocate local variables
pop ebp ; Restore the caller's base pointer value
ret
_myFunc ENDP
END
子程序首先通过入栈的手段保存ebp,分配局部变量,保存寄存器的值。
在子程序体中,参数和局部变量均是通过ebp进行计算。由于参数传递在子程序被调用之前,所以参数总是在ebp指示的地址的下方(在栈中),因此,上例中的第一个参数的地址是ebp+8,第二个参数的地址是ebp+12,第三个参数的地址是ebp+16;而局部变量在ebp指示的地址的上方,所有第一个局部变量的地址是ebp-4,而第二个这是ebp-8.
具体的CPU-Register-Cache关系请看链接
参考文献: 1. MIPS编程入门 https://www.cnblogs.com/thoupin/p/4018455.html
2.Linux系统分析入门--简单汇编代码分析 https://blog.csdn.net/ven_kon/article/details/57080849
3 .X86汇编快速入门 https://www.cnblogs.com/YukiJohnson/archive/2012/10/27/2741836.html
4. 内存、栈、堆的一点小总结 https://blog.csdn.net/hust_sheng/article/details/47947037
5.寄存器、存储器、内存的区别 https://blog.csdn.net/u012137644/article/details/21864955?locationNum=3
6. Linux 2.x 内核对内存的管理 https://blog.csdn.net/yang_yulei/article/details/24385573
7.计算机中内存、cache和寄存器之间的关系及区别 https://blog.csdn.net/hellojoy/article/details/54744231
8. 堆,栈区别理解 https://www.cnblogs.com/pomp/archive/2007/10/19/930145.html