系列介绍|本系列主要是记录学习jvm过程中觉得重要的内容,方便以后复习
在说垃圾收集算法之前,先要说一下垃圾收集,从大的讲,垃圾收集需要考虑三件事情:
1.哪些内存需要回收
2.什么时候回收
3.如何回收
JVM在执行java程序时,把他管理的内存分为多个数据区域:
1.程序计数器(记录程序执行到哪了,各线程之间独立存储, 互不影响)
2.虚拟机栈(这个栈就是我们常说的jvm的“堆”和“栈”中的栈,这里存放的是编译期间可知的各种数据类型(8种基本类型)、对象引用(reference类型,就是一种数据指针,指向对象的起始地址,或者句柄,或者是对象相关的位置)
3.本地方法栈(这个跟虚拟机栈非常相似,只不过虚拟机栈是为虚拟机执行java方法服务的,而本地方法栈是为虚拟机使用Natvie方法服务的,虚拟机规范中没有对本地方法栈做强制规定,HotSpot把虚拟机栈和本地方法栈合二为一了)
4.java堆(这堆是JVM管理内存中最多的一块,几乎所有的对象实例都存放在这里,java虚拟机规范中描述:所有对象的实例以及数据都要在堆上分配,GC就是主要管理这个区域)
5.方法区(在HotSpot中,这个区就是我们常说的“永久代”,这是一个线程共享的区域,它主要用来存储被虚拟机加载的类信息、常量、静态变量、JIT编译后的代码等数据)
其中程序计数器、虚拟机栈、本地方法栈3个区随线程而生,随线程而灭;栈中的栈帧随方法的进入和退出有条不紊的执行出栈和入栈操作,内存的分配是在类结构确定下来时就已知的,内存的分配和回收都具有确定性,因此这几个区域不需要过多考虑回收问题,因为方法结束或线程结束时,内存自然跟着回收了。主要考虑的是JAVA堆和方法区,因为这部分内存分配是动态的,程序在运行时才知道创建哪个对象实例,执行哪个方法。
GC回收前需要考虑对象已经“死”了吗
判断对象是否存活有两种算法,一种是引用计数算法,另一种是可达性算法
1)引用计数算法
引用计数算法就是给对象中添加一个引用计数器,每当有地方引用他时,计算器值加1,当引用失效时,计数器值减1,计算器值为0时,表示对象不再被使用。
引用计数算法实现简单,判定效率高,但是有个致命确定,就是循环引用时无法正常工作。
1 public class CountGC { 2 3 public Object instance = null; 4 5 public static void testGC(String[] args){ 6 //创建了一个CountGC对象,并发把它赋给了countGC1,CountGC的对象引用计数值加1 7 CountGC countGC1 = new CountGC(); 8 //又创建了一个CountGC对象,并发把它赋给了countGC2,另一个CountGC的对象引用计数值加1 9 CountGC countGC2 = new CountGC(); 10 11 //把第一个CountGC对象的instance字段赋值上第二个CountGC对象,第二个CountGC对象引用计数值再加1,这是就变成了2 12 countGC1.instance = countGC2; 13 //把第二个CountGC对象的instance字段赋值上第一个CountGC对象,第一个CountGC对象的引用计数值再加2,这时也变成了2 14 countGC2.instance = countGC1; 15 16 //countGC1赋空值,第一个CountGC对象引用减1 17 countGC1 = null; 18 //countGC2赋空值,第二个CountGC对象引用减1 19 countGC2 = null; 20 21 22 //如果这时候回收,这两个CountGC对象是无法回收的,因为他们的引用计数值不为0 23 System.gc(); 24 } 25 }
2)可达性算法
可达性算法就是以一个 GC Roots对象向下搜索,能搜索到的对象就说明是存活的,搜索不到的对象说明就是不可用的。
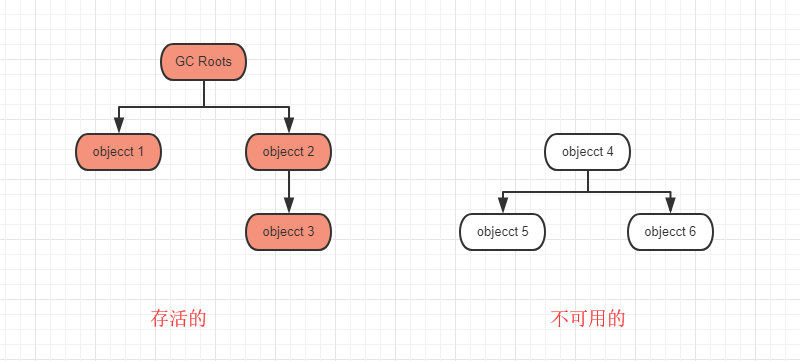
不管是引用计数算法,还是不可达算法,最终判断对象是否存活的关键,是引用。
下面我们正式介绍垃圾收集算法,我们主要介绍下面几种算法:
1.标记 - 清除算法
2.复制算法
3.标记 - 整理算法
4.分代收集算法
1)标记 - 清除算法
标记 - 清除算法就跟他的名字一样,分为“标记”和“清除”两阶段,首选标记出所有可回收的对象,然后统一回收所有被标记的对象。
标记 - 清除算法是最基础的算法,后续的几个算法都是基于这种算法思路对其不足进行改进得到的。
它的不足主要表现在两个方面,一是效率问题,二是空间利用问题
效率不高是因为,它标记是需要遍历所有内存空间,清除时也是一个个清除
空间利用率问题是因为清理后内存空间是零碎的,当需要分配大空间时,没有连续空间,需要再次触发GC
回收前状态:
回收后状态:



2)复制算法
为了解决效率问题,复制算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中一块,当这一块的内存用完时,就将存活的对象复制到另外一块内存上面,然后把使用过的内存空间一次清理掉。
回收前状态:
回收后状态:




复制算法的优点是:实现简单,运行高效
缺点是:浪费内存,从上面算法来看,实际使用只有原来内存的一半,浪费太大了。
现在的商用虚拟机都采用这种算法来回收新生代,IBM公司专门研究表明,新生代中的对象98%都是“朝生夕死”的,所以并不需要按照1:1来划分内存,而是将内存分成一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和一块Survivor,另一个Survivor作为预留空间。(HotSopt中默认分配比例是8:1:1,这样只浪费了10%的空间)。
采用这种内存分配方式的回收过程:
1.每次使用Eden和一块Survivor,另一块Survivor作为预留空间,
2.标记出Eden和一块Survivor空间中存活的对象,并复制到另一块Survivor空间中
3.清理掉使用过的Eden和一块Survivor空间。
这种做法有一个不足之处,就是当Eden和一块Survivor空间中存活的对象(对象存活率较高)大于另一块Survivor空间时,需要老年代担保分配,这时候效率非常低(因为存活对象是一个个复制到预留内存空间的,对象存活率特别高时,对象数也会非常多),而且还浪费空间(这时候预留空间就起不到作用了,浪费了预留空间的内存)。
因为当发现Eden和一块Survivor空间中存活的对象大于另一块Survivor空间时,这时候会把存活对象直接分配到老年代。
3)标记 - 整理算法
标记 - 整理算法就是把标记 - 清除算法中的清除替换成整理,整理时不直接对回收对象清理,而是让所有存活对象向一端移动,然后直接清理掉边界以外的内存。
回收前状态:
回收后状态:
这个算法是根据老年代的特点设计出来的,因为老年代中对象存活率较高,并且没有额外的空间对它进行分配担保,就必须采用“标记 - 清楚” 或者 “标记 - 整理”算法来进行回收。
4)分代收集
当前商业虚拟机都是采用“分代收集”算法,这种算法并没有什么新的思想,只是按照对象存活周期不同将内存划分为几个区域,就像java堆中的新生代和老年代一样,这样做的好处是,可以根据各个年代的特点采用适当的收集算法。