1.集群规划
|
服务名称 |
子服务 |
服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
|
HDFS |
NameNode |
√ |
||
|
DataNode |
√ |
√ |
√ |
|
|
SecondaryNameNode |
√ |
|||
|
Yarn |
NodeManager |
√ |
√ |
√ |
|
Resourcemanager |
√ |
|||
|
Zookeeper |
Zookeeper Server |
√ |
√ |
√ |
|
Flume(采集日志) |
Flume |
√ |
√ |
|
|
Kafka |
Kafka |
√ |
√ |
√ |
|
Flume(消费Kafka) |
Flume |
√ |
||
|
Hive |
Hive |
√ |
||
|
MySQL |
MySQL |
√ |
||
|
Sqoop |
Sqoop |
√ |
||
|
Presto |
Coordinator |
√ |
||
|
Worker |
√ |
√ |
||
|
Azkaban |
AzkabanWebServer |
√ |
||
|
AzkabanExecutorServer |
√ |
|||
|
Druid |
Druid |
√ |
√ |
√ |
|
服务数总计 |
13 |
8 |
9 |
2.jdk安装
[hadoop@hadoop103 soft]$ pwd /opt/soft [hadoop@hadoop103 soft]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C ../module/ ... ... [hadoop@hadoop103 jdk1.8.0_144]$ pwd /opt/module/jdk1.8.0_144 [hadoop@hadoop103 jdk1.8.0_144]$ sudo vi /etc/profile [hadoop@hadoop103 jdk1.8.0_144]$ tail -5 /etc/profile unset -f pathmunge JAVA_HOME=/opt/module/jdk1.8.0_144 PATH=$PATH:$JAVA_HOME/bin export JAVA_HOME PATH [hadoop@hadoop103 jdk1.8.0_144]$ source /etc/profile [hadoop@hadoop103 jdk1.8.0_144]$ jps 2548 Jps [hadoop@hadoop103 module]$ pwd /opt/module [hadoop@hadoop103 module]$ xsync jdk1.8.0_144/ ... ... [root@hadoop103 ~]# xsync /etc/profile 要分发的文件目录是:/etc/profile ----------------hadoop102----------------- sending incremental file list profile sent 606 bytes received 49 bytes 1310.00 bytes/sec total size is 1925 speedup is 2.94 ----------------hadoop103----------------- sending incremental file list sent 30 bytes received 12 bytes 84.00 bytes/sec total size is 1925 speedup is 45.83 ----------------hadoop104----------------- sending incremental file list profile sent 606 bytes received 49 bytes 1310.00 bytes/sec total size is 1925 speedup is 2.94 [hadoop@hadoop103 ~]$ xcall jps 要执行的命令是: jps ----------------hadoop102----------------- 5546 Jps ----------------hadoop103----------------- 2777 Jps ----------------hadoop104----------------- 5596 Jps
3.集群日志生成脚本
两种写法都行
java -cp log_collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.eric.applient.AppMain 1000 5
java -jar log_collector-1.0-SNAPSHOT-jar-with-dependencies.jar 1000 5
java -cp log_collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.eric.applient.AppMain 1000 5 >/dev/null 2>&1 &
>/dev/null 不会把正常信息打印出来
2>&1 错误信息也不会打印出来了
[hadoop@hadoop103 bin]$ cat lg #!/bin/bash #分别在hadoop102和hadoop103上启动 for i in hadoop102 hadoop103 do ssh $i java -cp /opt/module/log_collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.eric.appclient.AppMain $1 $2 > /dev/null 2>&1 & done [hadoop@hadoop103 bin]$ pwd /home/hadoop/bin
3.批量修改系统时间脚本
[hadoop@hadoop103 bin]$ pwd /home/hadoop/bin [hadoop@hadoop103 bin]$ ll total 8 -rwxrw-r-- 1 hadoop hadoop 251 Nov 10 2020 dt -rwxrw-r-- 1 hadoop hadoop 225 Nov 10 2020 lg [hadoop@hadoop103 bin]$ cat dt #!/bin/bash #在hadoop102和103上同步时间为指定日期 if(($#==0)) then echo 请传入要修改的时间! exit; fi #执行修改命令 for i in hadoop102 hadoop103 do echo -----正在同步$i的时间------ ssh $i "sudo date -s '$@'" done [hadoop@hadoop103 bin]$
4.同步集群时间为指定服务器
[hadoop@hadoop103 bin]$ ct 要执行的命令是sudo ntpdate -u ntp1.aliyun.com -----正在同步hadoop102的时间------ 10 Nov 21:02:15 ntpdate[17444]: step time server 120.25.115.20 offset 118302.921510 sec -----正在同步hadoop103的时间------ 10 Nov 21:02:15 ntpdate[5129]: step time server 120.25.115.20 offset 118303.007159 sec -----正在同步hadoop104的时间------ 10 Nov 21:02:16 ntpdate[16875]: adjust time server 120.25.115.20 offset 0.004871 sec [hadoop@hadoop103 bin]$ xcall date 要执行的命令是: date ----------------hadoop102----------------- Tue Nov 10 21:02:20 CST 2020 ----------------hadoop103----------------- Tue Nov 10 21:02:20 CST 2020 ----------------hadoop104----------------- Tue Nov 10 21:02:20 CST 2020 [hadoop@hadoop103 bin]$ cat ct #!/bin/bash #同步集群时间为时间服务器的时间 cmd="sudo ntpdate -u ntp1.aliyun.com" echo "要执行的命令是$cmd" for i in hadoop102 hadoop103 hadoop104 do echo -----正在同步$i的时间------ ssh $i $cmd done
5.安装hadoop
5.1解压软件
[hadoop@hadoop103 soft]$ pwd /opt/soft [hadoop@hadoop103 soft]$ tar -zxvf hadoop-2.7.2.tar.gz -C ../module/
5.2配置文件修改
核心配置文件core-site.xml
/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
HDFS配置文件
/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
YARN配置文件 配置日志的聚集
/opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
<!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
MapReduce配置文件 配置历史服务器
/opt/module/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[hadoop@hadoop103 hadoop]$ mv mapred-site.xml.template mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
<!--第三方框架使用yarn计算的日志聚集功能 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
6.hadoop启动
slaves
[hadoop@hadoop103 hadoop]$ pwd /opt/module/hadoop-2.7.2/etc/hadoop [hadoop@hadoop103 hadoop]$ vi slaves [hadoop@hadoop103 hadoop]$ cat slaves hadoop102 hadoop103 hadoop104
环境变量配置,并进行分发
HADOOP_HOME=/opt/module/hadoop-2.7.2 PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME PATH HADOOP_HOME
在102上格式化namenode
[hadoop@hadoop102 logs]$ source /etc/profile [hadoop@hadoop102 logs]$ echo $HADOOP_HOME /opt/module/hadoop-2.7.2 [hadoop@hadoop102 logs]$ [hadoop@hadoop102 logs]$ hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it.
在103上启动hadoop
[hadoop@hadoop103 hadoop-2.7.2]$ start-dfs.sh Starting namenodes on [hadoop102] hadoop102: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-hadoop-namenode-hadoop102.out hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop103.out hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop102.out hadoop104: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop104.out Starting secondary namenodes [hadoop104] hadoop104: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-hadoop-secondarynamenode-hadoop 104.out[hadoop@hadoop103 hadoop-2.7.2]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-hadoop-resourcemanager-hadoop103.out hadoop104: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop104.out hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop102.out hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop103.out [hadoop@hadoop103 hadoop-2.7.2]$ xcall jps 要执行的命令是: jps ----------------hadoop102----------------- 18068 NameNode 18393 Jps 18172 DataNode 18285 NodeManager ----------------hadoop103----------------- 5525 DataNode 6171 Jps 5772 ResourceManager 5885 NodeManager ----------------hadoop104----------------- 17733 Jps 17542 SecondaryNameNode 17625 NodeManager 17434 DataNode [hadoop@hadoop103 hadoop-2.7.2]$
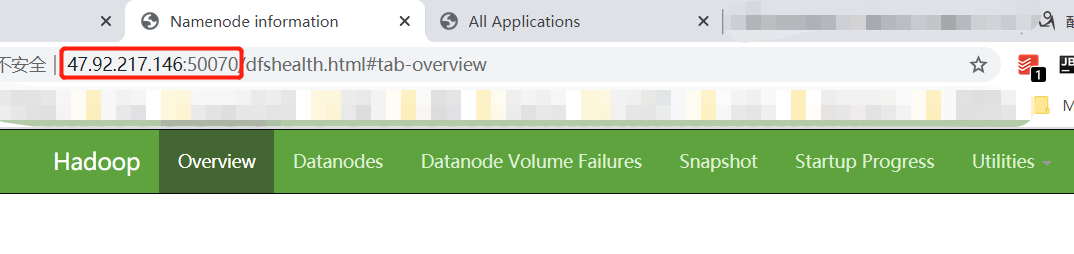
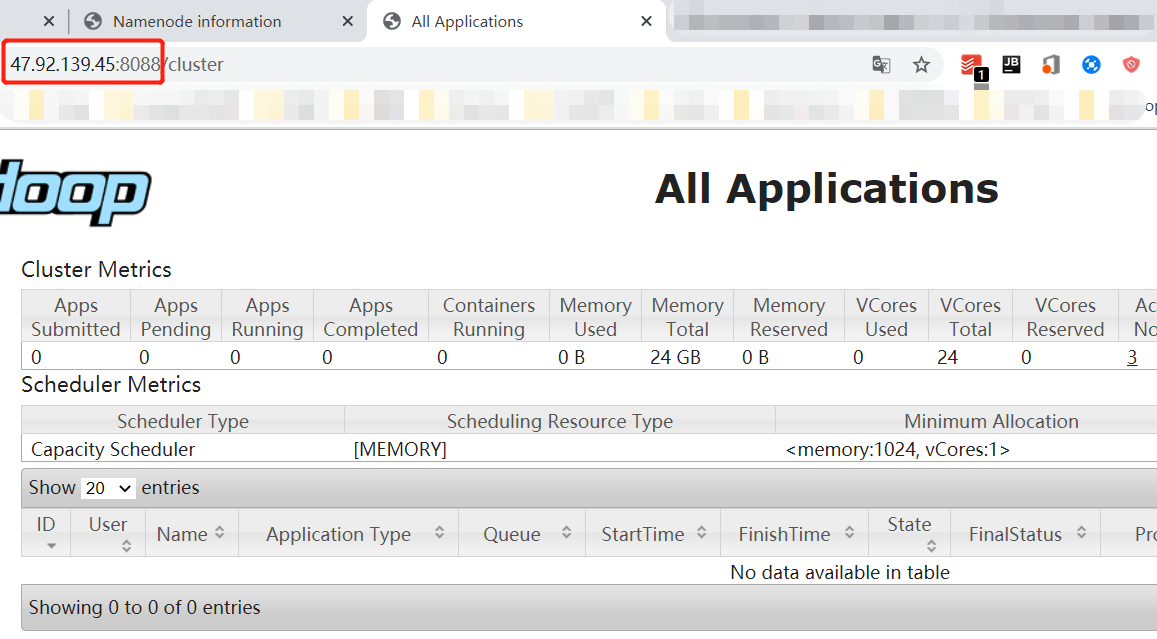
验证:
7.hadoop群起脚本的编写
[hadoop@hadoop103 bin]$ cat hd #!/bin/bash #判断只有一个参数 if(($#!=1)) then echo "请输入start|stop参数!" exit; fi #执行群起任务 if [ $1=start ]||[ $1=stop ] then #启动hdfs $1-dfs.sh #启动yarn $1-yarn.sh #启动历史日志服务 ssh hadoop102 mr-jobhistory-daemon.sh $1 historyserver else echo "请输入start|stop参数!" fi [hadoop@hadoop103 bin]$ hd start
8.为Hadoop集群安装LZO压缩
复制文件并分发
hadoop@hadoop103 ~]$ cp /opt/soft/hadoop-lzo-0.4.20.jar /opt/module/hadoop-2.7.2/share/hadoop/common/ [hadoop@hadoop103 ~]$ xsync /opt/module/hadoop-2.7.2/share/hadoop/common/ hadoop-common-2.7.2.jar hadoop-nfs-2.7.2.jar sources/ hadoop-common-2.7.2-tests.jar jdiff/ templates/ hadoop-lzo-0.4.20.jar lib/ [hadoop@hadoop103 ~]$ xsync /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar 要分发的文件目录是:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar ----------------hadoop102----------------- sending incremental file list hadoop-lzo-0.4.20.jar sent 193938 bytes received 31 bytes 387938.00 bytes/sec total size is 193831 speedup is 1.00 ----------------hadoop103----------------- sending incremental file list sent 44 bytes received 12 bytes 112.00 bytes/sec total size is 193831 speedup is 3461.27 ----------------hadoop104----------------- sending incremental file list hadoop-lzo-0.4.20.jar sent 193938 bytes received 31 bytes 387938.00 bytes/sec total size is 193831 speedup is 1.00
core-site.xml增加配置支持LZO压缩
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
分发
[hadoop@hadoop103 hadoop]$ xsync core-site.xml 要分发的文件目录是:/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml ----------------hadoop102----------------- sending incremental file list core-site.xml sent 861 bytes received 43 bytes 1808.00 bytes/sec total size is 1478 speedup is 1.63 ----------------hadoop103----------------- sending incremental file list sent 36 bytes received 12 bytes 96.00 bytes/sec total size is 1478 speedup is 30.79 ----------------hadoop104----------------- sending incremental file list core-site.xml sent 861 bytes received 43 bytes 1808.00 bytes/sec total size is 1478 speedup is 1.63
重启集群,进行测试
hd stop
hd start
测试准备
[hadoop@hadoop103 ~]$ pwd /home/hadoop [hadoop@hadoop103 ~]$ vi hello [hadoop@hadoop103 ~]$ ll total 8 drwxrwxr-x 2 hadoop hadoop 4096 Nov 10 22:14 bin -rw-rw-r-- 1 hadoop hadoop 15 Nov 11 11:42 hello [hadoop@hadoop103 ~]$ cat hello hello hi hello [hadoop@hadoop103 ~]$ hadoop fs -mkdir /input [hadoop@hadoop103 ~]$ hadoop fs -put hello /input
开始测试,报错Error: java.lang.RuntimeException: native-lzo library not available
[hadoop@hadoop103 ~]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar w ordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output20/11/11 11:46:31 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/172.24.67.126:8032 20/11/11 11:46:32 INFO input.FileInputFormat: Total input paths to process : 1 20/11/11 11:46:32 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 20/11/11 11:46:32 WARN lzo.LzoCompressor: java.lang.UnsatisfiedLinkError: Cannot load liblzo2.so.2 (liblzo2.so.2: cann ot open shared object file: No such file or directory)!20/11/11 11:46:32 ERROR lzo.LzoCodec: Failed to load/initialize native-lzo library 20/11/11 11:46:33 INFO mapreduce.JobSubmitter: number of splits:1 20/11/11 11:46:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1605065599335_0001 20/11/11 11:46:33 INFO impl.YarnClientImpl: Submitted application application_1605065599335_0001 20/11/11 11:46:33 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1605065599335_ 0001/20/11/11 11:46:33 INFO mapreduce.Job: Running job: job_1605065599335_0001 20/11/11 11:46:42 INFO mapreduce.Job: Job job_1605065599335_0001 running in uber mode : false 20/11/11 11:46:42 INFO mapreduce.Job: map 0% reduce 0% 20/11/11 11:46:53 INFO mapreduce.Job: map 100% reduce 0% 20/11/11 11:46:58 INFO mapreduce.Job: Task Id : attempt_1605065599335_0001_r_000000_0, Status : FAILED Error: java.lang.RuntimeException: native-lzo library not available at com.hadoop.compression.lzo.LzoCodec.getCompressorType(LzoCodec.java:155) at org.apache.hadoop.io.compress.CodecPool.getCompressor(CodecPool.java:150) at com.hadoop.compression.lzo.LzopCodec.getCompressor(LzopCodec.java:171) at com.hadoop.compression.lzo.LzopCodec.createOutputStream(LzopCodec.java:72) at org.apache.hadoop.mapreduce.lib.output.TextOutputFormat.getRecordWriter(TextOutputFormat.java:136) at org.apache.hadoop.mapred.ReduceTask$NewTrackingRecordWriter.<init>(ReduceTask.java:540) at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:614) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:389) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
处理:yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool
再次测试
[hadoop@hadoop103 ~]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar w ordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output220/11/11 14:18:43 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/172.24.67.126:8032 20/11/11 14:18:44 INFO input.FileInputFormat: Total input paths to process : 1 20/11/11 14:18:44 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 20/11/11 14:18:44 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 52decc77982b 58949890770d22720a91adce0c3f]20/11/11 14:18:44 INFO mapreduce.JobSubmitter: number of splits:1 20/11/11 14:18:44 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1605065599335_0003 20/11/11 14:18:46 INFO impl.YarnClientImpl: Submitted application application_1605065599335_0003 20/11/11 14:18:46 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1605065599335_ 0003/20/11/11 14:18:46 INFO mapreduce.Job: Running job: job_1605065599335_0003 20/11/11 14:18:58 INFO mapreduce.Job: Job job_1605065599335_0003 running in uber mode : false 20/11/11 14:18:58 INFO mapreduce.Job: map 0% reduce 0% 20/11/11 14:19:07 INFO mapreduce.Job: map 100% reduce 0% 20/11/11 14:19:13 INFO mapreduce.Job: map 100% reduce 100% 20/11/11 14:19:13 INFO mapreduce.Job: Job job_1605065599335_0003 completed successfully 20/11/11 14:19:14 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=27 FILE: Number of bytes written=236339 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=113 HDFS: Number of bytes written=63 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=5963 Total time spent by all reduces in occupied slots (ms)=3917 Total time spent by all map tasks (ms)=5963 Total time spent by all reduce tasks (ms)=3917 Total vcore-milliseconds taken by all map tasks=5963 Total vcore-milliseconds taken by all reduce tasks=3917 Total megabyte-milliseconds taken by all map tasks=6106112 Total megabyte-milliseconds taken by all reduce tasks=4011008 Map-Reduce Framework Map input records=3 Map output records=3 Map output bytes=27 Map output materialized bytes=27 Input split bytes=98 Combine input records=3 Combine output records=2 Reduce input groups=2 Reduce shuffle bytes=27 Reduce input records=2 Reduce output records=2 Spilled Records=4 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=280 CPU time spent (ms)=3200 Physical memory (bytes) snapshot=433188864 Virtual memory (bytes) snapshot=4185616384 Total committed heap usage (bytes)=314048512 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=15 File Output Format Counters Bytes Written=63
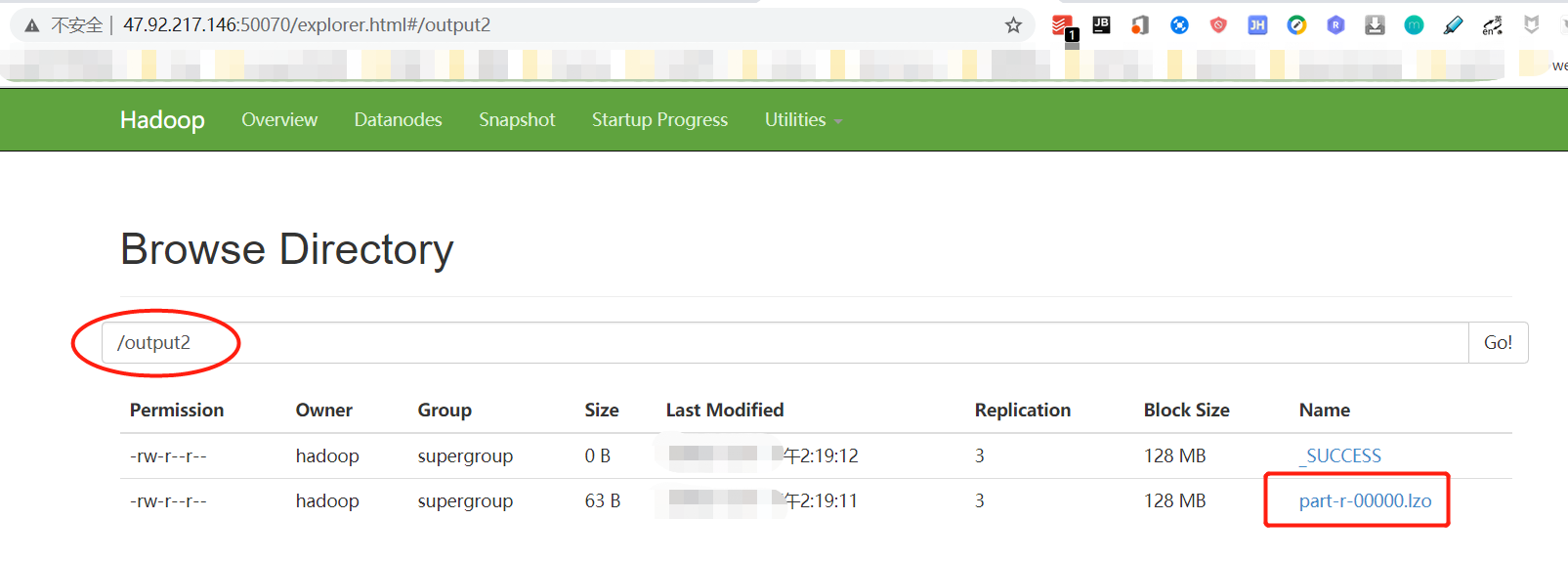
9.Hadoop集群LZO压缩建索引
lzo压缩默认不支持切片,需要建索引之后才可以
建索引
[hadoop@hadoop102 ~]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compre ssion.lzo.DistributedLzoIndexer /output220/11/12 17:41:54 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 20/11/12 17:41:54 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 52decc77982b 58949890770d22720a91adce0c3f]20/11/12 17:41:57 INFO lzo.DistributedLzoIndexer: Adding LZO file hdfs://hadoop102:9000/output2/part-r-00000.lzo to in dexing list (no index currently exists)20/11/12 17:41:57 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use m apreduce.map.speculative20/11/12 17:41:57 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/172.24.67.126:8032 20/11/12 17:41:59 INFO input.FileInputFormat: Total input paths to process : 1 20/11/12 17:41:59 INFO mapreduce.JobSubmitter: number of splits:1 20/11/12 17:41:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1605065599335_0006 20/11/12 17:42:00 INFO impl.YarnClientImpl: Submitted application application_1605065599335_0006 20/11/12 17:42:00 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1605065599335_ 0006/20/11/12 17:42:00 INFO lzo.DistributedLzoIndexer: Started DistributedIndexer job_1605065599335_0006 with 1 splits for [/output2]20/11/12 17:42:00 INFO mapreduce.Job: Running job: job_1605065599335_0006 20/11/12 17:42:10 INFO mapreduce.Job: Job job_1605065599335_0006 running in uber mode : false 20/11/12 17:42:10 INFO mapreduce.Job: map 0% reduce 0% 20/11/12 17:42:19 INFO mapreduce.Job: map 100% reduce 0% 20/11/12 17:42:19 INFO mapreduce.Job: Job job_1605065599335_0006 completed successfully 20/11/12 17:42:19 INFO mapreduce.Job: Counters: 31 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=117817 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=161 HDFS: Number of bytes written=8 HDFS: Number of read operations=2 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Job Counters Launched map tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=6947 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=6947 Total vcore-milliseconds taken by all map tasks=6947 Total megabyte-milliseconds taken by all map tasks=7113728 Map-Reduce Framework Map input records=1 Map output records=1 Input split bytes=111 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=204 CPU time spent (ms)=770 Physical memory (bytes) snapshot=160301056 Virtual memory (bytes) snapshot=2092244992 Total committed heap usage (bytes)=108003328 com.hadoop.mapreduce.LzoSplitRecordReader$Counters READ_SUCCESS=1 File Input Format Counters Bytes Read=50 File Output Format Counters Bytes Written=0

10.Hadoop集群HDFS性能测试
测试内容:向HDFS集群写10个256M的文件
[hadoop@hadoop102 ~]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7 .2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 256MB20/11/12 17:52:22 INFO fs.TestDFSIO: TestDFSIO.1.8 20/11/12 17:52:22 INFO fs.TestDFSIO: nrFiles = 10 20/11/12 17:52:22 INFO fs.TestDFSIO: nrBytes (MB) = 256.0 20/11/12 17:52:22 INFO fs.TestDFSIO: bufferSize = 1000000 20/11/12 17:52:22 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO 20/11/12 17:52:24 INFO fs.TestDFSIO: creating control file: 268435456 bytes, 10 files 20/11/12 17:52:25 INFO fs.TestDFSIO: created control files for: 10 files 20/11/12 17:52:26 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/172.24.67.126:8032 20/11/12 17:52:26 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/172.24.67.126:8032 20/11/12 17:52:27 INFO mapred.FileInputFormat: Total input paths to process : 10 20/11/12 17:52:27 INFO mapreduce.JobSubmitter: number of splits:10 20/11/12 17:52:27 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1605065599335_0007 20/11/12 17:52:28 INFO impl.YarnClientImpl: Submitted application application_1605065599335_0007 20/11/12 17:52:28 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1605065599335_ 0007/20/11/12 17:52:28 INFO mapreduce.Job: Running job: job_1605065599335_0007 20/11/12 17:52:41 INFO mapreduce.Job: Job job_1605065599335_0007 running in uber mode : false 20/11/12 17:52:41 INFO mapreduce.Job: map 0% reduce 0% 20/11/12 17:53:10 INFO mapreduce.Job: map 7% reduce 0% 20/11/12 17:53:12 INFO mapreduce.Job: map 13% reduce 0% 20/11/12 17:53:13 INFO mapreduce.Job: map 20% reduce 0% 20/11/12 17:53:14 INFO mapreduce.Job: map 27% reduce 0% 20/11/12 17:53:15 INFO mapreduce.Job: map 33% reduce 0% 20/11/12 17:53:16 INFO mapreduce.Job: map 47% reduce 0% 20/11/12 17:53:18 INFO mapreduce.Job: map 53% reduce 0% 20/11/12 17:53:19 INFO mapreduce.Job: map 60% reduce 0% 20/11/12 17:53:20 INFO mapreduce.Job: map 67% reduce 0% 20/11/12 17:53:53 INFO mapreduce.Job: map 70% reduce 0% 20/11/12 17:53:56 INFO mapreduce.Job: map 73% reduce 0% 20/11/12 17:53:58 INFO mapreduce.Job: map 80% reduce 0% 20/11/12 17:53:59 INFO mapreduce.Job: map 83% reduce 0% 20/11/12 17:54:00 INFO mapreduce.Job: map 93% reduce 0% 20/11/12 17:54:01 INFO mapreduce.Job: map 97% reduce 0% 20/11/12 17:54:02 INFO mapreduce.Job: map 100% reduce 0% 20/11/12 17:54:08 INFO mapreduce.Job: map 100% reduce 100% 20/11/12 17:54:08 INFO mapreduce.Job: Job job_1605065599335_0007 completed successfully 20/11/12 17:54:08 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=856 FILE: Number of bytes written=1306520 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2350 HDFS: Number of bytes written=2684354639 HDFS: Number of read operations=43 HDFS: Number of large read operations=0 HDFS: Number of write operations=12 Job Counters Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=10 Total time spent by all maps in occupied slots (ms)=747703 Total time spent by all reduces in occupied slots (ms)=12371 Total time spent by all map tasks (ms)=747703 Total time spent by all reduce tasks (ms)=12371 Total vcore-milliseconds taken by all map tasks=747703 Total vcore-milliseconds taken by all reduce tasks=12371 Total megabyte-milliseconds taken by all map tasks=765647872 Total megabyte-milliseconds taken by all reduce tasks=12667904 Map-Reduce Framework Map input records=10 Map output records=50 Map output bytes=750 Map output materialized bytes=910 Input split bytes=1230 Combine input records=0 Combine output records=0 Reduce input groups=5 Reduce shuffle bytes=910 Reduce input records=50 Reduce output records=5 Spilled Records=100 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=14278 CPU time spent (ms)=60920 Physical memory (bytes) snapshot=3132203008 Virtual memory (bytes) snapshot=23218429952 Total committed heap usage (bytes)=2073559040 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1120 File Output Format Counters Bytes Written=79 20/11/12 17:54:09 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write 20/11/12 17:54:09 INFO fs.TestDFSIO: Date & time: Thu Nov 12 17:54:09 CST 2020 20/11/12 17:54:09 INFO fs.TestDFSIO: Number of files: 10 20/11/12 17:54:09 INFO fs.TestDFSIO: Total MBytes processed: 2560.0 20/11/12 17:54:09 INFO fs.TestDFSIO: Throughput mb/sec: 5.534596633841032 20/11/12 17:54:09 INFO fs.TestDFSIO: Average IO rate mb/sec: 5.544580459594727 20/11/12 17:54:09 INFO fs.TestDFSIO: IO rate std deviation: 0.22970203553126334 20/11/12 17:54:09 INFO fs.TestDFSIO: Test exec time sec: 102.987 20/11/12 17:54:09 INFO fs.TestDFSIO:
测试内容:向HDFS集群读10个256M的文件 把-write 改为 -read就行
11.安装zookeeper
1.解压后配置环境变量,分发
[atguigu@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/ [hadoop@hadoop103 bin]$ cat /etc/profile KAFKA_HOME=/opt/module/kafka FLUME_HOME=/opt/module/flume ZK_HOME=/opt/module/zookeeper-3.4.10 PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$KAFKA_HOME/bin:$FLUME_HOME/bin:$ZK_HOME/bin export JAVA_HOME PATH HADOOP_HOME KAFKA_HOME FLUME_HOME ZK_HOME
2.配置服务器编号
1)在/opt/module/zookeeper-3.4.10/这个目录下创建datas
[hadoop@hadoop103 zookeeper-3.4.10]$ mkdir datas
2)在/opt/module/zookeeper-3.4.10/datas目录下创建一个myid的文件,编辑myid文件
在文件中添加与server对应的编号:
102
3)修改配置文件
dataDir=/opt/module/zookeeper-3.4.10/datas # the port at which the clients will connect clientPort=2181 server.102=hadoop102:2888:3888 server.103=hadoop103:2888:3888 server.104=hadoop104:2888:3888
4)同步
xsync /opt/module/zookeeper-3.4.10
在其他节点修改myid文件
3.编辑启动脚本
[hadoop@hadoop103 bin]$ cat zk #!/bin/bash if(($#!=1)) then echo "请输入正确的命令start|stop|status" exit; fi if [ $1 = start ] || [ $1 = stop ] || [ $1 = status ] then xcall zkServer.sh $1 else echo "请输入正确的命令start|stop|status" exit; fi
注意: $1 = start 中间必须有空格,“所有的符号两侧都有空格”
zookeeper启动失败检查办法:./zkServer.sh start-foreground 把错误信息会打印出来
12.安装flume
分发
[hadoop@hadoop103 module]$ xsync flume/
验证
[hadoop@hadoop103 module]$ xcall flume-ng version
要执行的命令是: flume-ng version
----------------hadoop102-----------------
Flume 1.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707
Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016
From source with checksum 0d21b3ffdc55a07e1d08875872c00523
----------------hadoop103-----------------
Flume 1.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707
Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016
From source with checksum 0d21b3ffdc55a07e1d08875872c00523
----------------hadoop104-----------------
Flume 1.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707
Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016
From source with checksum 0d21b3ffdc55a07e1d08875872c00523
12.安装kafaka
1.配置
1)brokeid配置
2)允许删除topic
3)文件配置
4)zookeepr配置
[hadoop@hadoop103 config]$ vi server.properties
[hadoop@hadoop103 config]$ pwd
/opt/module/kafka/config
21 broker.id=103 24 delete.topic.enable=true 63 log.dirs=/opt/module/kafka/datas 126 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
2.分发:
[hadoop@hadoop103 module]$ xsync kafka/
3.启动脚本编写
[hadoop@hadoop103 bin]$ pwd /home/hadoop/bin [hadoop@hadoop103 bin]$ cat kf #!/bin/bash if(($#!=1)) then echo "请输入start|stop命令" exit; fi if [ $1 = start ] then xcall kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties elif [ $1 = stop ] then xcall kafka-server-stop.sh else echo "请输入start|stop命令" fi
4.kafka性能测试
Kafka Producer压力测试,
写入的平均延迟为XX毫秒,最大的延迟为XX毫秒。
Kafka Consumer压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能
[hadoop@hadoop103 ~]$ kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 10 00 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:90925001 records sent, 1000.0 records/sec (0.10 MB/sec), 7.0 ms avg latency, 486.0 max latency. 5004 records sent, 1000.8 records/sec (0.10 MB/sec), 1.0 ms avg latency, 25.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 1.0 ms avg latency, 29.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.9 ms avg latency, 19.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 1.3 ms avg latency, 63.0 max latency. 5002 records sent, 1000.2 records/sec (0.10 MB/sec), 0.7 ms avg latency, 23.0 max latency. 5003 records sent, 1000.4 records/sec (0.10 MB/sec), 0.6 ms avg latency, 14.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 29.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.5 ms avg latency, 19.0 max latency. 5002 records sent, 1000.0 records/sec (0.10 MB/sec), 0.5 ms avg latency, 12.0 max latency. 5002 records sent, 1000.2 records/sec (0.10 MB/sec), 0.6 ms avg latency, 19.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 30.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.6 ms avg latency, 16.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 1.1 ms avg latency, 54.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 25.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 30.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 38.0 max latency. 5002 records sent, 1000.2 records/sec (0.10 MB/sec), 0.6 ms avg latency, 16.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.6 ms avg latency, 19.0 max latency. 100000 records sent, 999.920006 records/sec (0.10 MB/sec), 1.07 ms avg latency, 486.00 ms max latency, 1 ms 50th, 2 ms 95th, 16 ms 99th, 71 ms 99.9th.[hadoop@hadoop103 ~]$ kafka-consumer-perf-test.sh --zookeeper hadoop102:2181 --topic test --fetch-size 10000 --message s 10000000 --threads 1start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec Killed [hadoop@hadoop103 ~]$ kafka-consumer-perf-test.sh --zookeeper hadoop102:2181 --topic test --fetch-size 10000 --message s 10000000 --threads 1start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2020-11-16 10:30:36:069, 2020-11-16 10:30:38:891, 12.6267, 4.4744, 132401, 46917.4344