NNLM
NNLM:Neural Network Language Model,神经网络语言模型。源自Bengio等人于2001年发表在NIPS上的《A Neural Probabilistic Language Model一文。
理论
模型结构
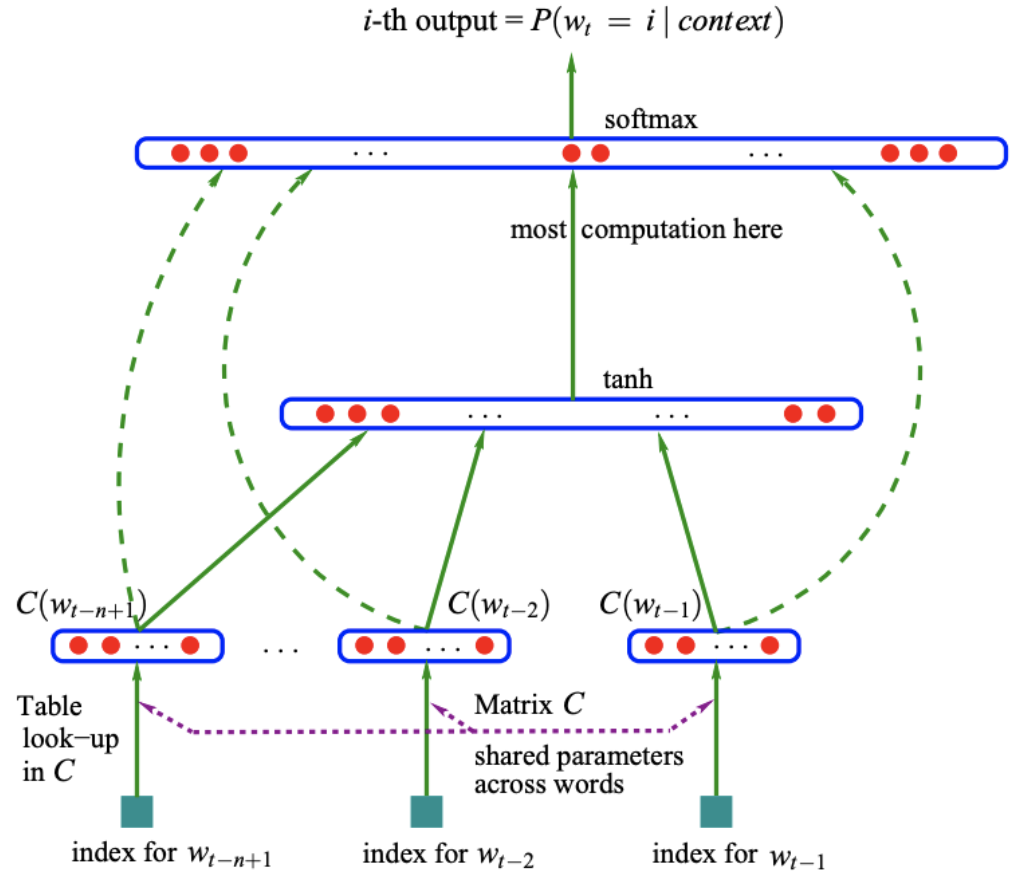
任务
根据(w_{t-n+1}...w_{t-1})来预测(w_t)是什么单词,即用(n-1)个单词来预测第(n)个单词
符号
- (V):词汇的总数,即词汇表的大小
- (m):词向量的长度
- (C):(V)行,m列的矩阵表示词向量词表
- (C(w)):单词w的词向量
- (d):隐藏层的偏置
- (H):隐藏层的权重
- (U):隐藏层到输出层的权重
- (b):输出层的偏置
- (W):输入层到输出层的权重
- (h):隐藏层的神经元个数
Data Flow
- 获取(n-1)个词的词向量,每个词向量的长度是(m)
- 进行这(n-1)个词向量的拼接,形成一个((n-1)*m)长度的向量,记做(X)
- 将(X)送入隐藏层,计算(hidden_{out}=tanh(X*H+d))的到隐藏层的输出
- 将隐藏层的输出和输入的词向量同时送入输出层,计算(y=X*W+hidden_{out}*U+b),得到输出层(|V|)个节点的输出,第(i)个节点的输出代表下一个单词是第(i)个单词的概率。概率最大的单词为预测到的单词。
代码
Import依赖模块
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
from torch.autograd import Variable
dtype = torch.FloatTensor
声明变量
sentences = ["i like dog", "i love coffee", "i hate milk"] # 句子数据集
n_steps = 2 # 用前几个单词来预测下一个单词,e.g. 2个
n_hidden = 2 # 隐藏层的节点个数,e.g. 2个
m = 2 # 词向量的长度
生成词表
word_list = " ".join(sentences).split(" ") # 获取所有的单词
print("未去重词表:", word_list)
word_list = list(set(word_list)) # 去重
print("去重词表:", word_list)
word_dict = {w: i for i, w in enumerate(word_list)} # 单词->索引
print("单词索引:", word_dict)
number_dict = {i: w for i, w in enumerate(word_list)} # 索引->单词
print("索引单词:", number_dict)
num_words = len(word_dict) # 单词总数
print("单词总数:", num_words)
输出
未去重词表: ['i', 'like', 'dog', 'i', 'love', 'coffee', 'i', 'hate', 'milk']
去重词表: ['coffee', 'love', 'dog', 'like', 'milk', 'hate', 'i']
单词索引: {'coffee': 0, 'love': 1, 'dog': 2, 'like': 3, 'milk': 4, 'hate': 5, 'i': 6}
索引单词: {0: 'coffee', 1: 'love', 2: 'dog', 3: 'like', 4: 'milk', 5: 'hate', 6: 'i'}
单词总数: 7
模型结构
class NNLM(nn.Module):
# NNLM model architecture
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(num_embeddings = num_words, embedding_dim = m) # 词表
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype)) # 隐藏层的偏置
self.H = nn.Parameter(torch.randn(n_steps * m, n_hidden).type(dtype)) # 输入层到隐藏层的权重
self.U = nn.Parameter(torch.randn(n_hidden, num_words).type(dtype)) # 隐藏层到输出层的权重
self.b = nn.Parameter(torch.randn(num_words).type(dtype)) # 输出层的偏置
self.W = nn.Parameter(torch.randn(n_steps * m, num_words).type(dtype)) # 输入层到输出层的权重
def forward(self, input):
'''
input: [batchsize, n_steps]
x: [batchsize, n_steps*m]
hidden_layer: [batchsize, n_hidden]
output: [batchsize, num_words]
'''
x = self.C(input) # 获得一个batch的词向量的词表
x = x.view(-1, n_steps * m)
hidden_out = torch.tanh(torch.mm(x, self.H) + self.d) # 获取隐藏层输出
output = torch.mm(x, self.W) + torch.mm(hidden_out, self.U) + self.b # 获得输出层输出
return output
格式化输入
def make_batch(sentences):
'''
input_batch:一组batch中前n_steps个单词的索引
target_batch:一组batch中每句话待预测单词的索引
'''
input_batch = []
target_batch = []
for sentence in sentences:
word = sentence.split()
input = [word_dict[w] for w in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
input_batch, target_batch = make_batch(sentences)
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
print("input_batch:", input_batch)
print("target_batch:", target_batch)
输出
input_batch: tensor([[6, 3],
[6, 1],
[6, 5]])
target_batch: tensor([2, 0, 4])
训练
model = NNLM()
criterion = nn.CrossEntropyLoss() # 使用cross entropy作为loss function
optimizer = optim.Adam(model.parameters(), lr = 0.001) # 使用Adam作为optimizer
for epoch in range(2000):
# 梯度清零
optimizer.zero_grad()
# 计算predication
output = model(input_batch)
# 计算loss
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print("Epoch:{}".format(epoch+1), "Loss:{:.3f}".format(loss))
# 反向传播
loss.backward()
# 更新权重参数
optimizer.step()
输出
Epoch:100 Loss:1.945
Epoch:200 Loss:1.367
Epoch:300 Loss:0.937
Epoch:400 Loss:0.675
Epoch:500 Loss:0.537
Epoch:600 Loss:0.435
Epoch:700 Loss:0.335
Epoch:800 Loss:0.234
Epoch:900 Loss:0.147
Epoch:1000 Loss:0.094
Epoch:1100 Loss:0.065
Epoch:1200 Loss:0.047
Epoch:1300 Loss:0.036
Epoch:1400 Loss:0.029
Epoch:1500 Loss:0.023
Epoch:1600 Loss:0.019
Epoch:1700 Loss:0.016
Epoch:1800 Loss:0.014
Epoch:1900 Loss:0.012
Epoch:2000 Loss:0.011
推理
pred = model(input_batch).data.max(1, keepdim=True)[1] # 找出概率最大的下标
print("Predict:", pred)
print([sentence.split()[:2] for sentence in sentences], "---->", [number_dict[n.item()] for n in pred.squeeze()])
输出
Predict: tensor([[2],
[0],
[4]])
[['i', 'like'], ['i', 'love'], ['i', 'hate']] ----> ['dog', 'coffee', 'milk']
可以和我们的数据集做对比预测准确的。