计算机专科毕业,.net开发已有8年有余,中途断断续续,似懂非懂,积累了一些经验知识,但是不求甚解,属于那种一瓶不满半瓶子晃荡,这么一个状态。
主要从事web开发,涉及一些前端jq等,还有接口开发,搜索,语音识别,支付,加速,等各种第三方调用,还有一些文件监控,分解分发任务。等一些功能的应用程序。
后来公司主要语言从.net改为java,主要原因 招人不方便,主力技术总监以java熟,我也就跟着慢慢学习一些java知识,在语言语法上没有什么大的 障碍,就是在工具开发使用环境上面比较繁琐。
怎么说呢,java这一块算是不是很熟,基本能做的就是改写发布这一套流程。接下来技术总监几经更换,,目前面临往以下方面发展:
1. 大数据底层存储方向:hadoop集群搭建(除原生外,还可关注CDH)、hbase、hdfs
2. 流式计算方向:spark core、spark streaming、spark sql,语言java和python均可,建议python,不推荐scala
3. 人工智能方向:spark MLlib、Kaldi,spark MLlib语言使用python,java也行,Kaldi建议c++, 不推荐c
这是目前的一些要求,选取区中一个方向学习研究,经过分析,java目前我是转java过来最弱的,经过这几年,目前公司转java来的,我这个部门的,目前就我自己。对python来说,起跑线基本持平,
所以选择python没有什么弱势,并且在兴趣上,对计算还比较感兴趣。所以决定学习python 学习spark core、spark streaming、spark sql这些东西,记录一下。
以下搜集的一些资料信息,并不一定完全正确,理解上也是一知半解,还望指正。
一:对于这三者关系的理解
Spark Core :
Spark的基础,底层的最小数据单位是:RDD ; 主要是处理一些离线(可以通过结合Spark Streaming来处理实时的数据流)、非格式化数据。
Spark SQL:
Spark SQL 底层的数据处理单位是:DataFrame(新版本为DataSet<Row>) ; 主要是通过执行标准 SQL 来处理一些离线(可以通过结合Spark Streaming来处理实时的数据流)、格式化数据。
Spark Streaming:
Spark Streaming底层的数据处理单位是:DStream ; 主要是处理流式数据(数据一直不停的在向Spark程序发送),这里可以结合 Spark Core 和 Spark SQL 来处理数据,如果来源数据是非结构化的数据,那么我们这里就可以结合 Spark Core 来处理,如果数据为结构化的数据,那么我们这里就可以结合Spark SQL 来进行处理。
---------------------
来源:https://blog.csdn.net/Han_Lin_/article/details/86669681
二:安装python环境(python 3.X 及以上版本)向下不兼容,开发环境在windows上
1.下载适合自己电脑的最新版本即可 https://www.python.org/downloads/windows/ 30M左右 我下载的是安装版3.7
3.7中安装的时候把环境变量一定要勾选,方便以后使用


画圈的都要装一下pip很重要,就像是java的maven一样,我感觉,像是一个安装库的工具
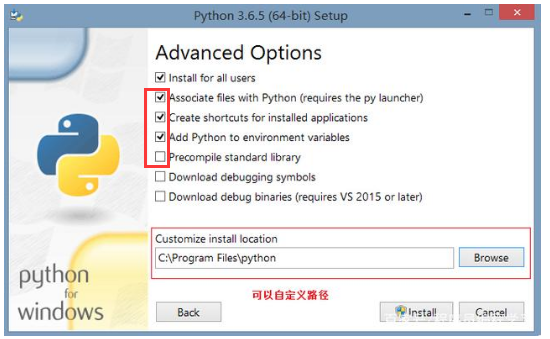
建议2,3,4,5都装一下其他选装。
剩下的一步步安装完成
python安装好之后,我们要检测一下是否安装成功,用系统管理员打开命令行工具cmd,输入“python -V”,然后敲回车,如果出现如下界面,则表示我们安装成功了;
写程序
安装成功之后,当然要写第一个python程序了,按照惯例,我们写一个“hello world”;
还是打开cmd,输入“python”后敲回车,
进入到python程序中,可以直接在里面输入,然后敲回车执行程序,
我们打印一个“hello world”看看,在里面输入 print("hello world"),敲回车,所有程序员都会遇到的第一个程序就出现啦;
基于python的开发环境idle使用不方便,idle算是迷你ide,然后我选择了自认为比较好用的开发工具Pycharm.
下载地址https://www.jetbrains.com/pycharm/download/#section=windows 300M左右注册码什么的自己找,找不到用免费的。
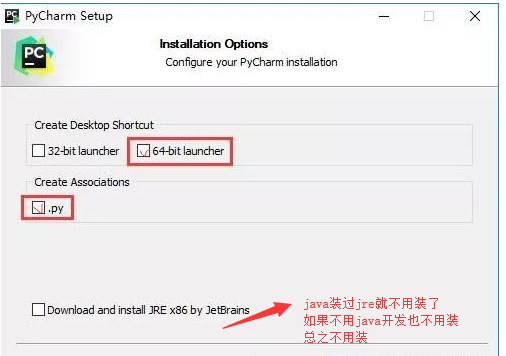
启动的时候选择 不导入配置
具体安装步骤 参见 https://blog.csdn.net/pdcfighting/article/details/80297499
下一节 学习pyspark包导入实现。