(1) 相关博文地址:
学习一下 SpringCloud (一)-- 从单体架构到微服务架构、代码拆分(maven 聚合): https://www.cnblogs.com/l-y-h/p/14105682.html 学习一下 SpringCloud (二)-- 服务注册中心 Eureka、Zookeeper、Consul、Nacos :https://www.cnblogs.com/l-y-h/p/14193443.html
(2)代码地址:
https://github.com/lyh-man/SpringCloudDemo
一、引入 服务调用、负载均衡
1、问题 与 解决
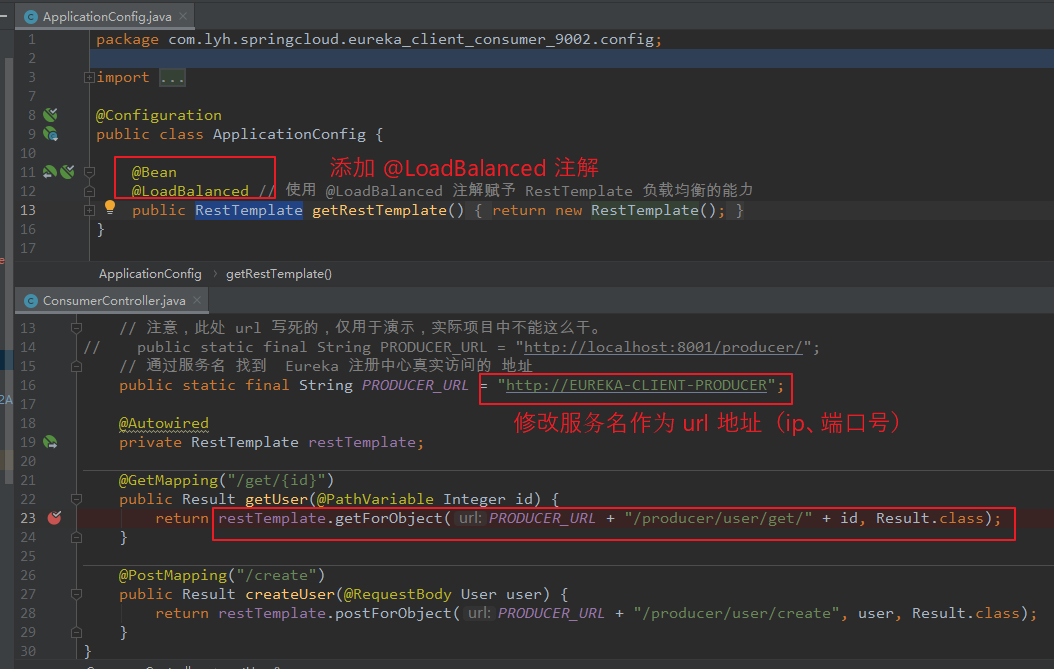
【问题:】 在上一篇中,介绍了 Eureka、Zookeeper、Consul 作为注册中心,并使用 RestTemplate 进行服务调用。 详见:https://www.cnblogs.com/l-y-h/p/14193443.html 那么是如何进行负载均衡的呢? 【解决:】 在 @Bean 声明 RestTemplate 时,添加一个 @LoadBalanced,并使用 注册中心中 的服务名 作为 RestTemplate 的 URL 地址(ip、端口号)。 就这么简单的两步,即可实现了负载均衡。 那么这里面又涉及到什么技术知识呢?能不能更换负载均衡策略?能不能自定义负载均衡策略? 常用技术: Ribbon(维护状态,替代产品为 Loadbalancer) OpenFeign(推荐使用) 【说明:】 此处以 Eureka 伪集群版创建的几个模块作为演示。代码地址:https://github.com/lyh-man/SpringCloudDemo 服务注册中心:eureka_server_7001、eureka_server_7002、eureka_server_7003 服务提供者:eureka_client_producer_8002、eureka_client_producer_8003、eureka_client_producer_8004 服务消费者:eureka_client_consumer_9002 注: 主要还是在 服务消费者 上配置负载均衡策略(可以 Debug 模式启动看看执行流程),其他模块直接启动即可。
二、服务调用、负载均衡 -- Ribbon
1、什么是 Ribbon?
【Ribbon:】 Ribbon 是 Netflix 公司实现的一套基于 HTTP、TCP 的客户端负载均衡的工具。 SpringCloud 已将其集成到 spring-cloud-netflix 中,实现 SpringCloud 的服务调用、负载均衡。 Ribbon 提供了多种方式进行负载均衡(默认轮询),也可以自定义负载均衡方法。 注: Ribbon 虽然已进入维护模式,但是一时半会还不容易被完全淘汰,还是可以学习一下基本使用的。 Ribbon 替代产品是 Loadbalancer。 【相关网址:】 https://github.com/Netflix/ribbon http://jvm123.com/doc/springcloud/index.html#spring-cloud-ribbon
2、Ribbon 与 Nginx 负载均衡区别
【负载均衡(Load Balance):】
负载均衡指的是 将工作任务 按照某种规则 平均分摊到 多个操作单元上执行。
注:
Web 项目的负载均衡,可以理解为:将用户请求 平均分摊到 多个服务器上处理,从而提高系统的并发度、可用性。
【负载均衡分类:】
按照软硬件划分:
硬件负载均衡: 一般造价昂贵,但数据传输更加稳定。比如: F5 负载均衡。
软件负载均衡: 一般采用某个代理组件,并使用 某种 负载均衡 算法实现(一种消息队列分发机制)。比如:Nginx、Ribbon。
按照负载均衡位置划分:
集中式负载均衡:提供一个 独立的 负载均衡系统(可以是软件,比如:Nginx,可以是硬件,比如:F5)。
通过此系统,将服务消费者的 请求 通过某种负载均衡策略 转发给 服务提供者。
客户端负载均衡(进程式负载均衡):将负载均衡逻辑整合到 服务消费者中,服务消费者 定时同步获取到 服务提供者信息,并保存在本地。
每次均从本地缓存中取得 服务提供者信息,并根据 某种负载均衡策略 将请求发给 服务提供者。
注:
使用集中式负载均衡时,服务消费者 不知道 任何一个服务提供者的信息,只知道独立负载均衡设备的信息。
使用客户端负载均衡时,服务消费者 知道 所有服务提供者的信息。
【Nginx 负载均衡:】
Nginx 实现的是 集中式负载均衡,Nginx 接收 客户端所有请求,并将请求转发到不同的服务器进行处理。
【Ribbon 负载均衡:】
Ribbon 实现的是 客户端负载均衡,从注册中心获得服务信息并缓存在本地,在本地进行 负载均衡。
3、更换 Ribbon 负载均衡规则(两种方式)
(1)引入依赖
【依赖:】
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
一般使用 Ribbon 时需要引入上述依赖,但是对于 eureka 来说,其 eureka-client 依赖中已经集成了 ribbon 依赖,所以无需再次引入。

(2)Ribbon 提供的几种负载均衡算法
Ribbon 提供了 IRule 接口,通过其可以设置并更换负载均衡规则。
IRule 实质就是 根据某种负载均衡规则,从服务列表中选取一个需要访问的服务。
一般默认使用 ZoneAvoidanceRule + RoundRobinRule。
【IRule 子类如下:】 RoundRobinRule 轮询,按照服务列表顺序 循环选择服务。 RandomRule 随机,随机的从服务列表中选取服务。 RetryRule 重试,先按照轮询策略获取服务,若获取失败,则在指定时间进行重试,重新获取可用服务。 WeightedResponseTimeRule 加权响应时间,响应时间越低(即响应时间快),权重越高,越容易被选择。刚开始启动时,使用轮询策略。 BestAvailableRule 高可用,先过滤掉不可用服务(多次访问故障而处于断路器跳闸的服务),选择一个并发量最小的服务。 AvailabilityFilteringRule 可用筛选,先过滤掉不可用服务 以及 并发量超过阈值的服务,对剩余服务按轮询策略访问。 ZoneAvoidanceRule 区域回避,默认规则,综合判断服务所在区域的性能 以及 服务的可用性,过滤结果后采用轮询的方式选择结果。 【IRule:】 package com.netflix.loadbalancer; public interface IRule { Server choose(Object var1); void setLoadBalancer(ILoadBalancer var1); ILoadBalancer getLoadBalancer(); }
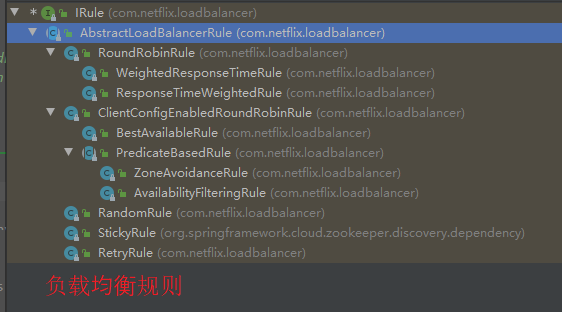
以 Dubug 模式 启动 eureka_client_consumer_9002,并在 IRule 接口 实现类的 choose() 方法上打上断点,发送请求时,将会进入断点,此时可以看到执行的 负载均衡规则。
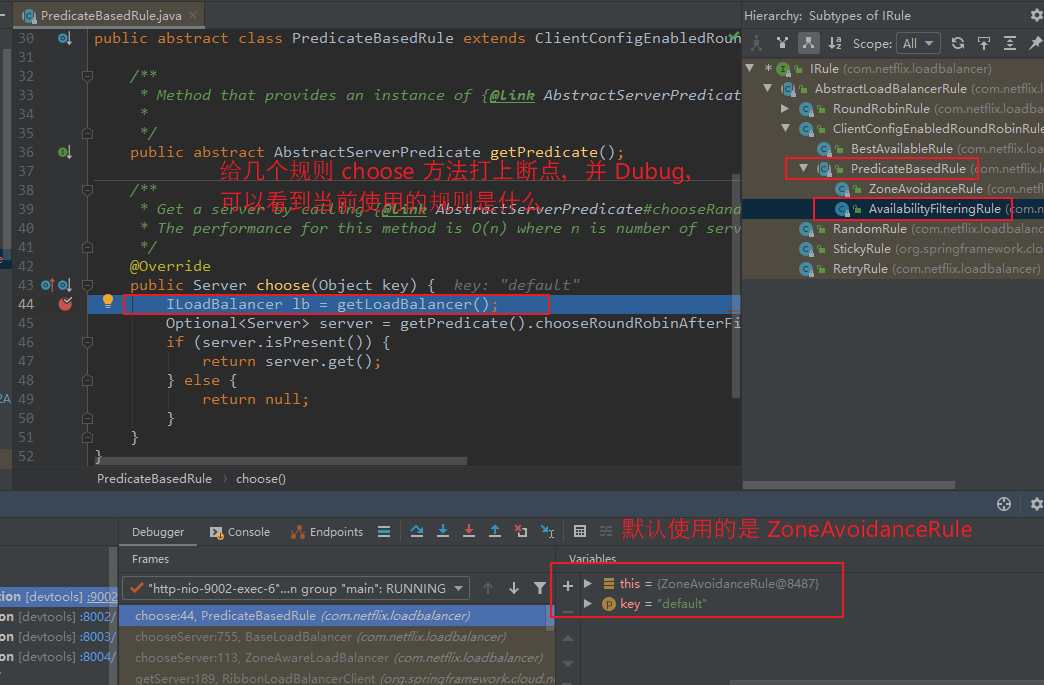
不停的刷新页面,可以看到请求以轮询的方式被 服务提供者 处理。

(3)替换负载均衡规则(方式一:新建配置类)
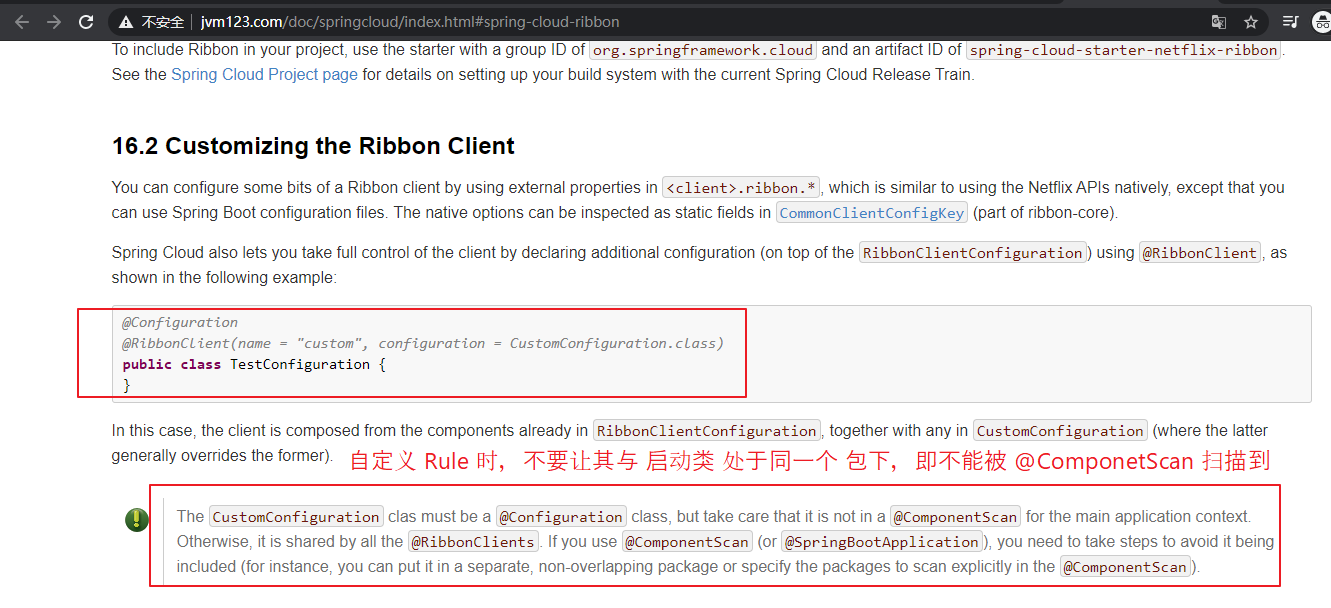
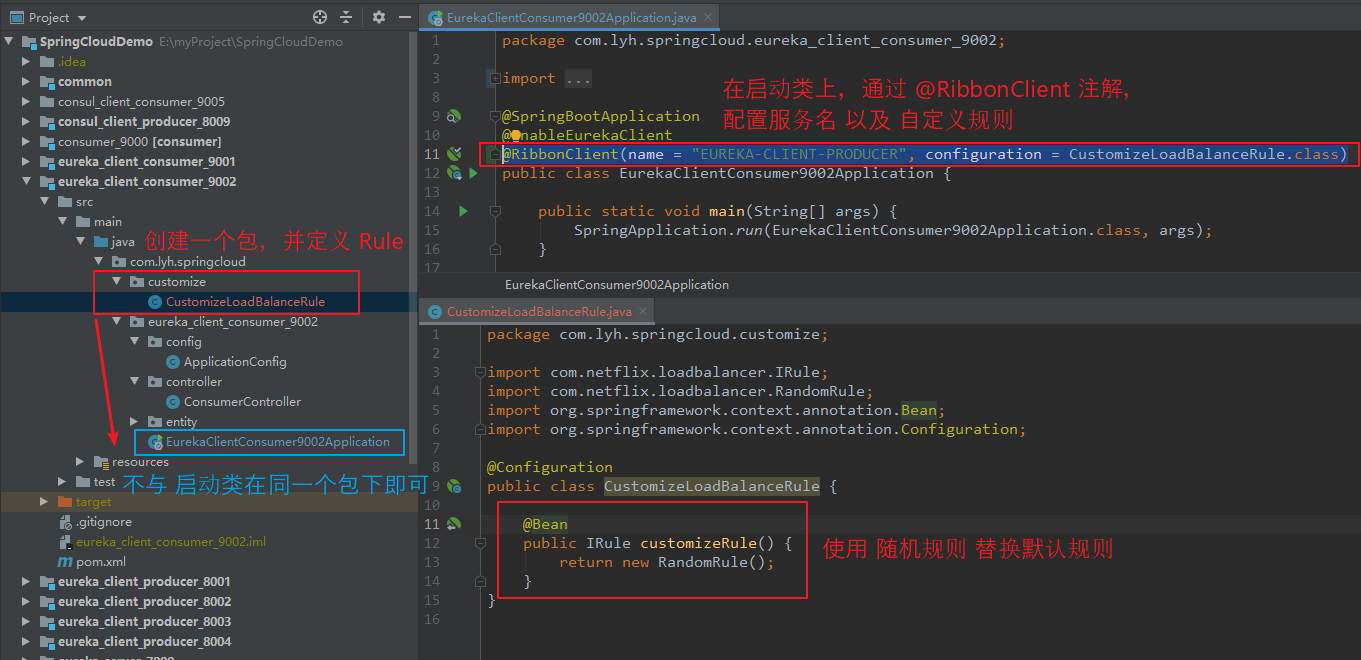
【步骤一:】 新建一个配置类(该类不能被 @ComponentScan 扫描到,即不能与 启动类 在同一个包下),并定义规则。 比如: package com.lyh.springcloud.customize; import com.netflix.loadbalancer.IRule; import com.netflix.loadbalancer.RandomRule; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class CustomizeLoadBalanceRule { @Bean public IRule customizeRule() { return new RandomRule(); } } 【步骤二:】 在启动类上添加 @RibbonClient 注解,并指定服务名 以及 规则。 比如: @RibbonClient(name = "EUREKA-CLIENT-PRODUCER", configuration = CustomizeLoadBalanceRule.class)
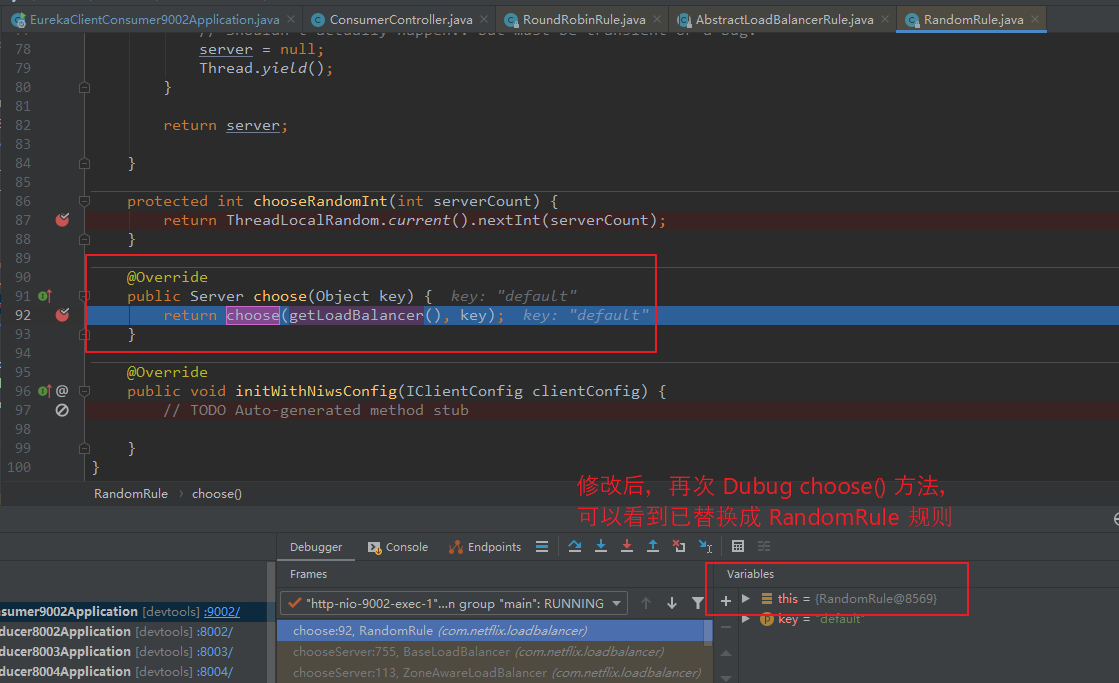
不停的刷新页面,可以看到请求以随机的方式被 服务提供者 处理,而非轮询。

(4)替换负载均衡规则(方式二:修改配置文件)
在服务消费者 配置文件中 根据 服务提供者 服务名,
通过 ribbon.NFLoadBalancerRuleClassName 指定负载均衡策略。
注:
在后面的 OpenFeign 的使用中进行演示。
【举例:】 EUREKA-CLIENT-PRODUCER: # 服务提供者的服务名 ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
4、轮询原理(RoundRobinRule)
(1)相关源码
主要就是 choose()、incrementAndGetModulo() 这两个方法。
choose() 用于选择 server 服务。
incrementAndGetModulo() 用来决定 选择哪个服务,返回服务下标。
public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { log.warn("no load balancer"); return null; } Server server = null; int count = 0; while (server == null && count++ < 10) { List<Server> reachableServers = lb.getReachableServers(); List<Server> allServers = lb.getAllServers(); int upCount = reachableServers.size(); int serverCount = allServers.size(); if ((upCount == 0) || (serverCount == 0)) { log.warn("No up servers available from load balancer: " + lb); return null; } int nextServerIndex = incrementAndGetModulo(serverCount); server = allServers.get(nextServerIndex); if (server == null) { /* Transient. */ Thread.yield(); continue; } if (server.isAlive() && (server.isReadyToServe())) { return (server); } // Next. server = null; } if (count >= 10) { log.warn("No available alive servers after 10 tries from load balancer: " + lb); } return server; } private AtomicInteger nextServerCyclicCounter; private int incrementAndGetModulo(int modulo) { for (;;) { int current = nextServerCyclicCounter.get(); int next = (current + 1) % modulo; if (nextServerCyclicCounter.compareAndSet(current, next)) return next; } }
(2)代码分析
【choose():】 初始进入 choose() 方法,server 为 null 表示服务不存在,count 为 0 表示属于尝试第一次获取服务。 进入 while 循环后,退出条件为 server 不为 null(即找到服务) 或者 count 大于等于 10 (即尝试了 10 次仍未找到服务)。 而 获取 server 的核心在于获取 服务的下标,即 int nextServerIndex = incrementAndGetModulo(serverCount); 【incrementAndGetModulo()】 核心就是 自旋 CAS 并取模。 modulo 表示服务器总数,current 表示当前服务下标,next 表示下一个服务下标。 compareAndSet() 即 CAS 实现,如果 内存中的值 与 current 相同,那么将内存中值改为 next,并返回 true,否则返回 false。 即 compareAndSet 失败后,会不停的执行循环 以获取 最新的 current。 注: 自旋、CAS 后面会讲到。CAS 保证原子性。 其实就是一个公式: 第几次请求 % 服务器总数量 = 实际调用服务器下标位置
5、手写一个轮询算法
(1)说明
【说明:】
创建一个与 eureka_client_consumer_9002 模块类似的模块 eureka_client_consumer_9005。
修改配置文件,并去除 @LoadBalanced 注解(避免引起误解)。
自己实现一个轮询算法(与 RoundRobinRule 类似)。
注:
此处在 controller 中定义一个接口,用于测试 轮询的功能(仅供参考,可以继承 AbstractLoadBalancerRule,自行构造一个负载均衡类)。
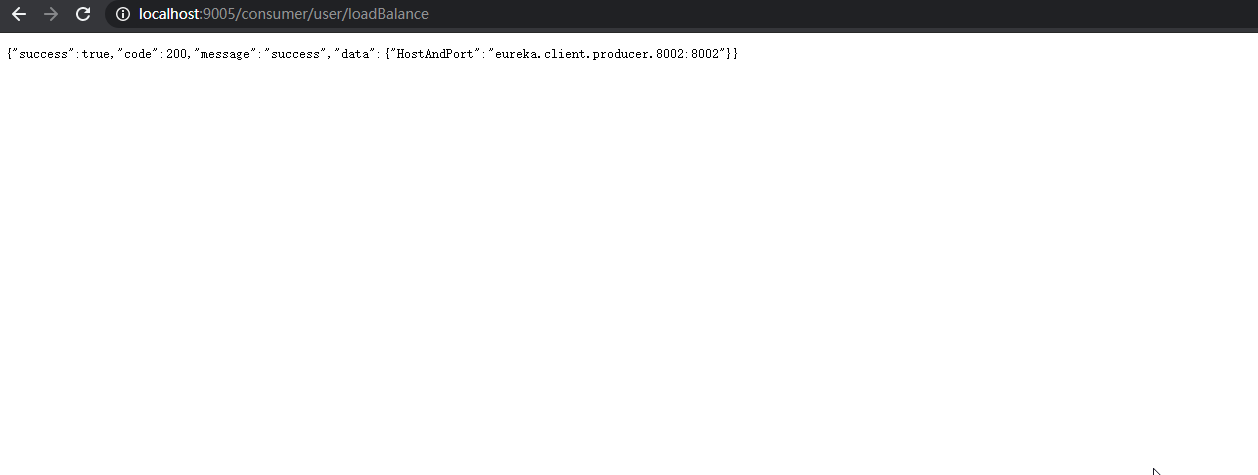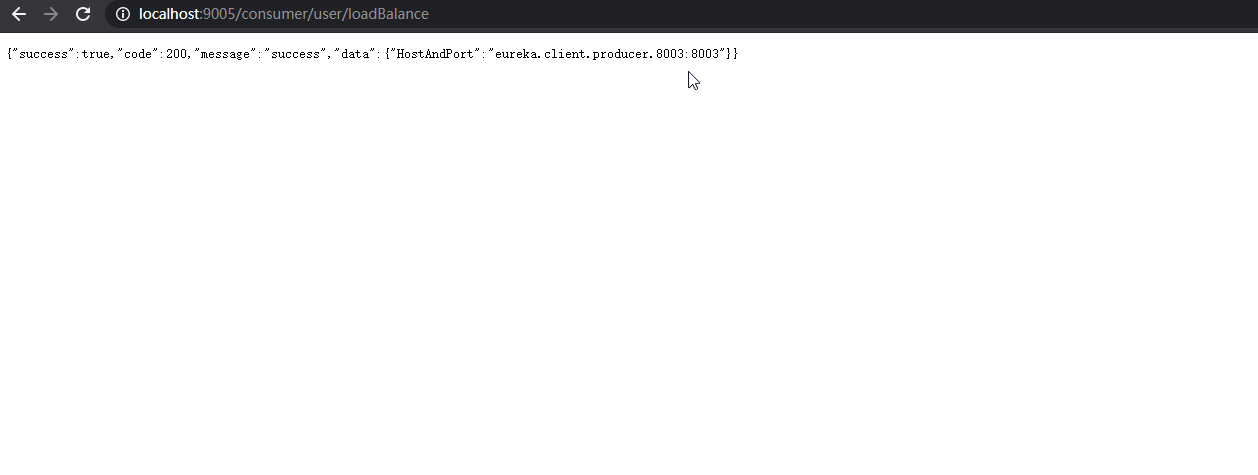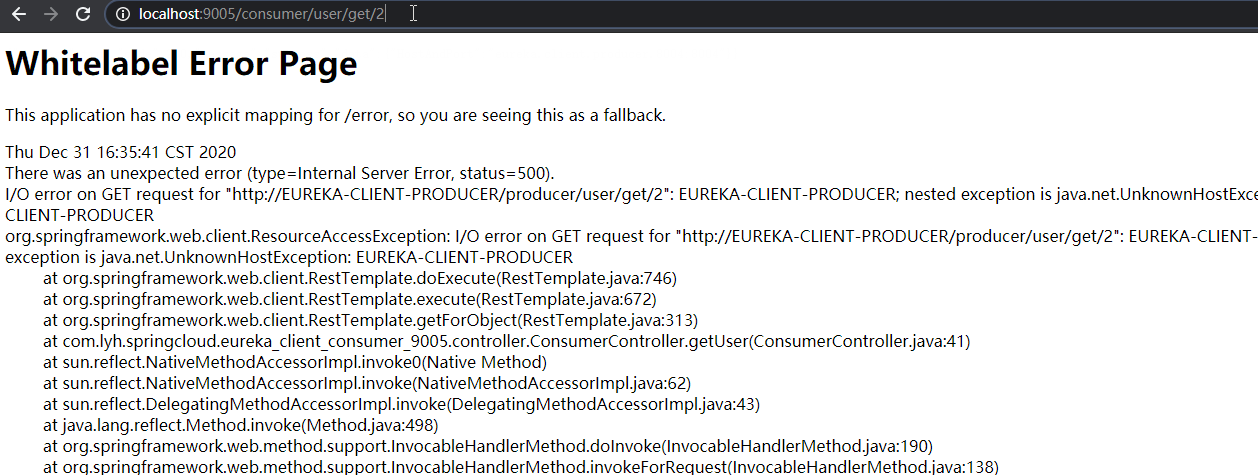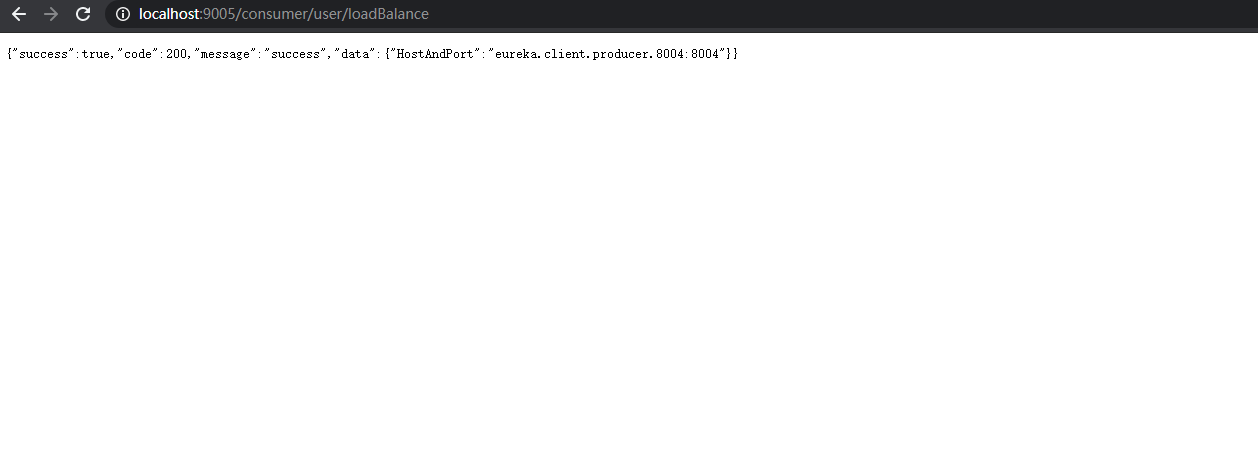
去除 @LoadBalanced 注解后,访问调用 RestTemplate 请求的接口时会报错(用于区分)。
(2)相关代码
模块创建此处省略(需要修改 pom.xml,配置文件)。
详情请见上篇博客:https://www.cnblogs.com/l-y-h/p/14193443.html#_label2_3
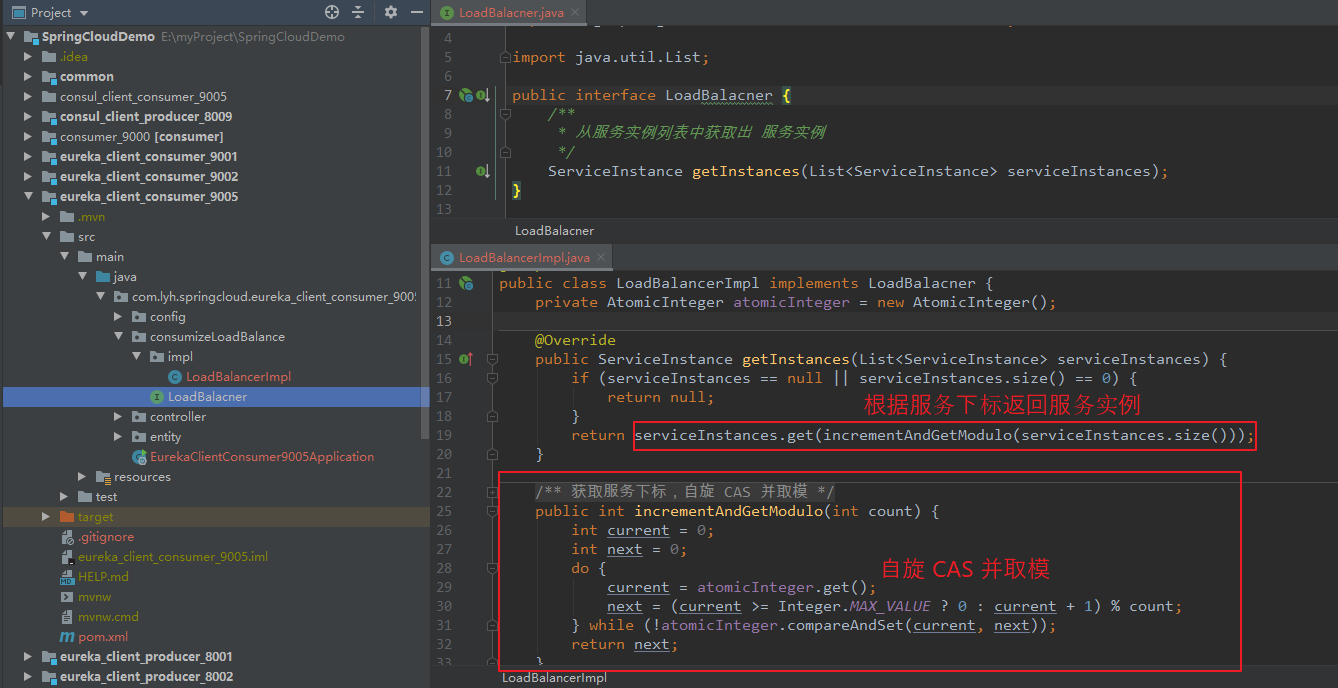
面向接口编程,此处新建一个 LoadBalacner 接口,用于定义抽象方法(返回服务信息)。
并定义一个 LoadBalacner 接口的实现类 LoadBalancerImpl。
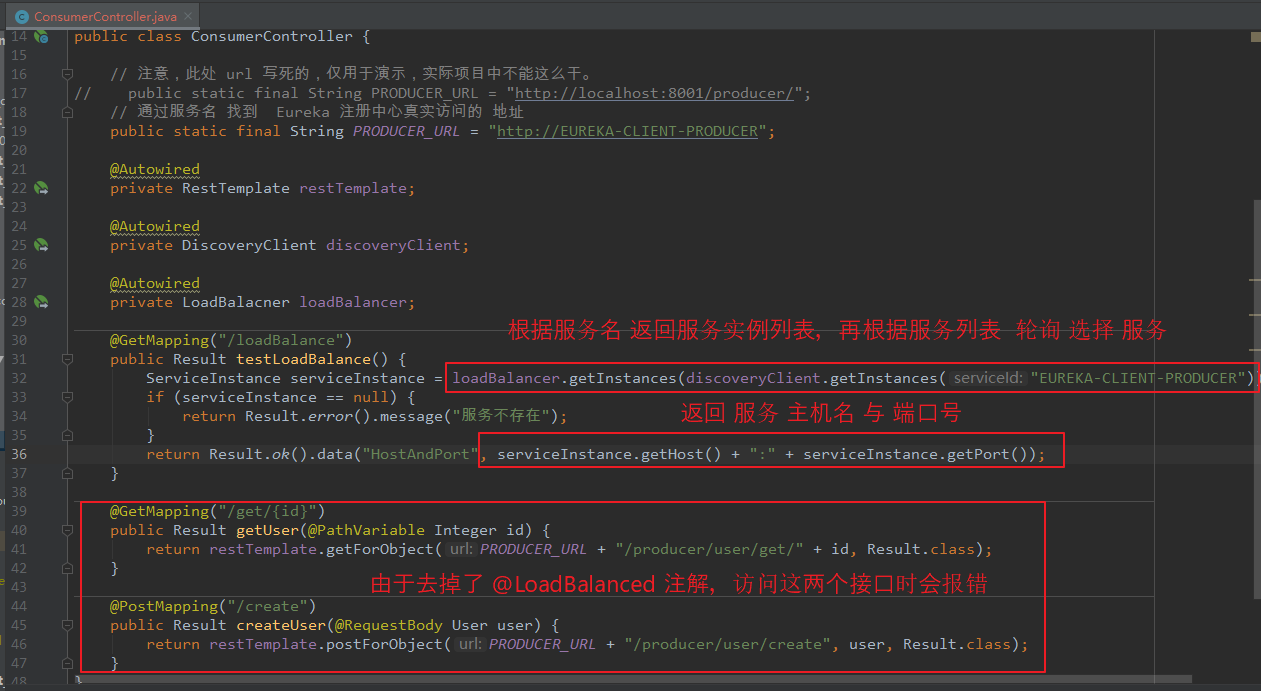
在 controller 中编写接口(服务发现),测试一下。
【LoadBalacner】 package com.lyh.springcloud.eureka_client_consumer_9005.consumizeLoadBalance; import org.springframework.cloud.client.ServiceInstance; import java.util.List; public interface LoadBalacner { /** * 从服务实例列表中获取出 服务实例 */ ServiceInstance getInstances(List<ServiceInstance> serviceInstances); } 【LoadBalancerImpl】 package com.lyh.springcloud.eureka_client_consumer_9005.consumizeLoadBalance.impl; import com.lyh.springcloud.eureka_client_consumer_9005.consumizeLoadBalance.LoadBalacner; import org.springframework.cloud.client.ServiceInstance; import org.springframework.stereotype.Component; import java.util.List; import java.util.concurrent.atomic.AtomicInteger; @Component public class LoadBalancerImpl implements LoadBalacner { private AtomicInteger atomicInteger = new AtomicInteger(); @Override public ServiceInstance getInstances(List<ServiceInstance> serviceInstances) { if (serviceInstances == null || serviceInstances.size() == 0) { return null; } return serviceInstances.get(incrementAndGetModulo(serviceInstances.size())); } public int incrementAndGetModulo(int count) { int current = 0; int next = 0; do { current = atomicInteger.get(); next = (current >= Integer.MAX_VALUE ? 0 : current + 1) % count; } while (!atomicInteger.compareAndSet(current, next)); return next; } } 【ConsumerController】 package com.lyh.springcloud.eureka_client_consumer_9005.controller; import com.lyh.springcloud.common.tools.Result; import com.lyh.springcloud.eureka_client_consumer_9005.consumizeLoadBalance.LoadBalacner; import com.lyh.springcloud.eureka_client_consumer_9005.entity.User; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.client.ServiceInstance; import org.springframework.cloud.client.discovery.DiscoveryClient; import org.springframework.web.bind.annotation.*; import org.springframework.web.client.RestTemplate; @RestController @RequestMapping("/consumer/user") public class ConsumerController { // 注意,此处 url 写死的,仅用于演示,实际项目中不能这么干。 // public static final String PRODUCER_URL = "http://localhost:8001/producer/"; // 通过服务名 找到 Eureka 注册中心真实访问的 地址 public static final String PRODUCER_URL = "http://EUREKA-CLIENT-PRODUCER"; @Autowired private RestTemplate restTemplate; @Autowired private DiscoveryClient discoveryClient; @Autowired private LoadBalacner loadBalancer; @GetMapping("/loadBalance") public Result testLoadBalance() { ServiceInstance serviceInstance = loadBalancer.getInstances(discoveryClient.getInstances("EUREKA-CLIENT-PRODUCER")); if (serviceInstance == null) { return Result.error().message("服务不存在"); } return Result.ok().data("HostAndPort", serviceInstance.getHost() + ":" + serviceInstance.getPort()); } @GetMapping("/get/{id}") public Result getUser(@PathVariable Integer id) { return restTemplate.getForObject(PRODUCER_URL + "/producer/user/get/" + id, Result.class); } @PostMapping("/create") public Result createUser(@RequestBody User user) { return restTemplate.postForObject(PRODUCER_URL + "/producer/user/create", user, Result.class); } }
三、补充知识
1、CAS
(1)什么是 CAS?
【CAS:】 CAS 是 Compare And Swap 的缩写,即 比较交换。 是一种无锁算法,在不加锁的情况下实现多线程之间变量同步,从而保证数据的原子性。 属于硬件层面对并发操作的支持(CPU 原语)。 注: 原子性:一个操作或多个操作要么全部执行且执行过程中不会被其他因素打断,要么全部不执行。 原语:指的是若干条指令组成的程序段,实现特定的功能,执行过程中不能被中断(也即原子性)。 【基本流程:】 CAS 操作包含三个操作数 —— 内存值(V)、预期原值(A)和新值(B)。 如果内存里面的值 V 和 A 的值是一样的,那么就将内存里面的值更新成 B, 若 V 与 A 不一致,则不操作(某些情况下,可以通过自旋操作,不断尝试修改数据直至成功修改)。 即 V = V == A ? B : V; 或者 for(;;) { V = getV(); if (V == A) { V = B; break; } } 【缺点:(详见下面的 Atomic 类底层原理)】 会出现 ABA 问题(两次读取数据时值相同,但不确定值是否被修改过)。 使用自旋(死循环)CAS 时会占用系统资源、影响执行效率。 每次只能对一个共享变量进行原子操作。
(2)原子性
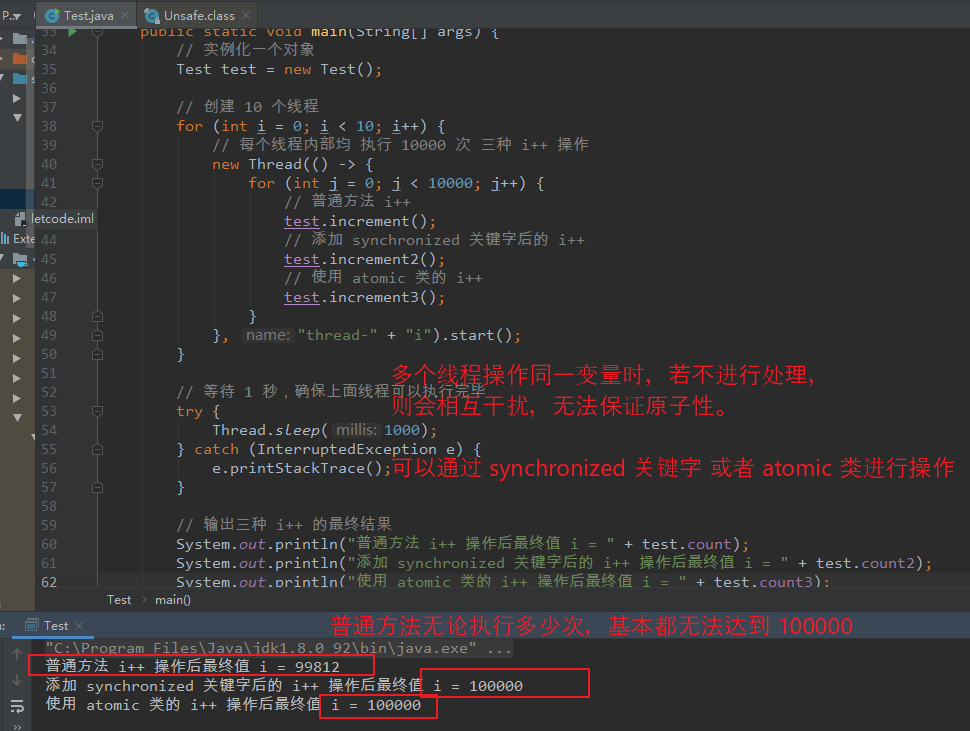
【说明:】 初始 i = 0,现有 10 个线程,分别执行 i++ 10000次,若不对 i++ 做任何限制,那么最终执行结果一般都是小于 100000 的。 因为 A、B 执行 i++ 操作时,彼此会相互干扰,也即不能保证原子性。 【如何保证原子性:】 可以给 i++ 操作加上 synchronized 进行同步控制,从而保证操作按照顺序执行、互不干扰。 也可以使用 Atomic 相关类进行操作(核心是 自旋 CAS 操作 volatile 变量)。 注: synchronized 在 JDK1.6 之前,属于重量级锁,属于悲观锁的一种(在操作锁变量前就给对象加锁,而不管对象是否发生资源竞争),性能较差。 在 JDK1.6 之后,对 synchronized 进行了优化,引入了 偏向锁、轻量级锁、采用 CAS 思想,提升了效率。 【CAS 与 synchronized 比较:】 CAS: CAS 属于无锁算法,可以支持多个线程并发修改,并发度高。 CAS 每次只支持一个共享变量进行原子操作。 CAS 会出现 ABA 问题。 synchronized: synchronized 一次只能允许一个线程修改,并发度低。 synchronized 可以对多个共享变量进行原子操作。 【举例:】 package com.lyh.tree; import java.util.concurrent.atomic.AtomicInteger; public class Test { private int count = 0; private int count2 = 0; private AtomicInteger count3 = new AtomicInteger(0); /** * 普通方法 */ public void increment() { count++; } /** * 使用 synchronized 修饰的方法 */ public synchronized void increment2() { count2++; } /** * 使用 atomic 类的方法 */ public void increment3() { count3.getAndIncrement(); } public static void main(String[] args) { // 实例化一个对象 Test test = new Test(); // 创建 10 个线程 for (int i = 0; i < 10; i++) { // 每个线程内部均 执行 10000 次 三种 i++ 操作 new Thread(() -> { for (int j = 0; j < 10000; j++) { // 普通方法 i++ test.increment(); // 添加 synchronized 关键字后的 i++ test.increment2(); // 使用 atomic 类的 i++ test.increment3(); } }, "thread-" + "i").start(); } // 等待 1 秒,确保上面线程可以执行完毕 try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 输出三种 i++ 的最终结果 System.out.println("普通方法 i++ 操作后最终值 i = " + test.count); System.out.println("添加 synchronized 关键字后的 i++ 操作后最终值 i = " + test.count2); System.out.println("使用 atomic 类的 i++ 操作后最终值 i = " + test.count3); } }
2、Atomic 类底层原理
(1)Atomic 常用类有哪些?
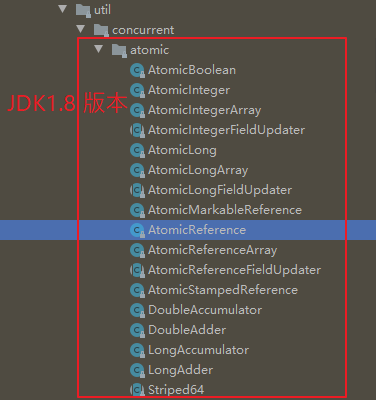
【Atomic:】 Atomic 类存放于 java.util.concurrent.atomic 包下,用于提供对变量的原子操作(保证变量操作的原子性)。 【常用类:】 操作基本类型的 Atomic 类(提供了对 boolean、int、long 类型的原子操作): AtomicBoolean AtomicInteger AtomicLong 操作引用类型的 Atomic 类(提供了引用类型的原子操作): AtomicReference AtomicStampedReference AtomicMarkableReference 注: AtomicStampedReference、AtomicMarkableReference 以版本号、标记的方式解决 ABA 问题。 操作数组的 Atomic 类(提供了数组的原子操作): AtomicIntegerArray AtomicLongArray AtomicReferenceArray
(2)底层原理
【底层原理:】 一句话概括:Atomic 类基于 Unsafe 类 以及 (自旋) CAS 操作 volatile 变量实现的。 核心点: Unsafe 类 提供 native 方法,用于操作内存 valueOffset 变量 指的是变量在内存中的地址。 volatile 变量 指的是共享变量(保证操作可见性)。 CAS CPU 原语(保证操作原子性)。 【Unsafe:】 Unsafe 存放于 JDK 源码 rt.jar 的 sun.misc 包下。 内部提供了一系列 native 方法,用于与操作系统交互(可以操作特定内存中的数据)。 注: Unsafe 属于 CAS 核心类,Java 无法直接访问底层操作系统,需要通过 native 方法进行操作,而 Unsafe 就是为此存在的。 【volatile 变量:】 使用 volatile 修改变量,保证数据在多线程之间的可见性(一个线程修改数据后,其余线程均能知道修改后的数据)。 【valueOffset 变量:】 valueOffset 变量 表示共享变量在内存中的偏移地址,Unsafe 根据此地址获取 共享变量在内存中的值。
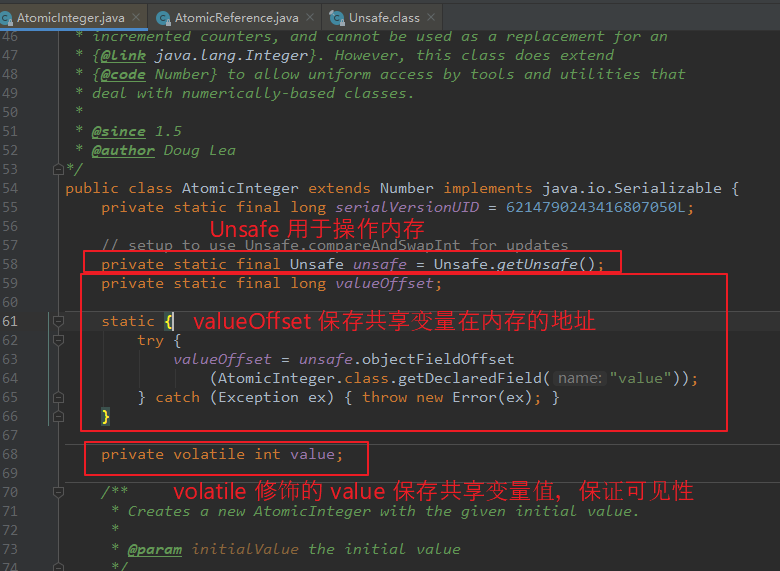
(3)以 AtomicInteger 为例。
compareAndSet() 直接调用 CAS 进行比较。
getAndIncrement() 使用 自旋 CAS 进行比较。
【AtomicInteger 类:】 /** * 直接调用 Unsafe 的 CAS 操作。 * 根据 this 以及 valueOffset 获取到内存中的值 V,expect 为期望值 A,如果 V == A,则将 V 值改为 update,否则不操作。 * * this 表示当前对象 * valueOffset 表示共享变量在内存的偏移地址 * expect 表示期望值 * update 表示更新值 */ public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); } /** * 以原子方式递增当前 value。 * 调用 Unsafe 的 getAndAddInt() 进行操作,即 自旋 CAS 操作。 * * this 表示当前对象 * valueOffset 表示共享变量在内存的偏移地址 * 1 表示每次增加值为 1 */ public final int getAndIncrement() { return unsafe.getAndAddInt(this, valueOffset, 1); } 【Unsafe 类:】 /** * CAS 原语操作。 * 各变量含义参考上面 AtomicInteger compareAndSet() 的注释。 */ public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); /** * 自旋 CAS 操作。 * var1 表示当前对象。 * var2 表示共享变量在内存的偏移地址 * var4 表示共享变量每次递增的值 */ public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { // 先根据偏移地址,获取到 内存中存储的值 var5 = this.getIntVolatile(var1, var2); // 然后死循环(自旋)CAS 判断。 // 根据偏移地址再去取一次内存中的值 与 已经取得的值进行比较,相同则加上需要增加的值。 // 不同,则 CAS 失败,也即 while 条件为 true,再进行下一次比较。 } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
(4)缺点:
【CAS 缺点:】 会出现 ABA 问题(两次读取数据时值相同,但不确定值是否被修改过)。 自旋(死循环)CAS 会占用系统资源、影响执行效率。 每次只能对一个共享变量进行原子操作。 【对于自旋 CAS:】 在上面 Unsafe 类的 getAndAddInt() 方法中,可以看到一个 do-while 循环。 存在这么一种情况:while 条件中 CAS 一直失败,也即循环一直持续(死循环), 此时将会占用 CPU 资源不断执行循环,影响执行效率。 【对于 ABA 问题:】 CAS 算法是从内存中取出某时刻的值并与当前期望值进行比较,从内存中取出的值就可能存在问题。 存在这么一种情况:线程 A、线程 B 同时操作内存值 V,线程 A 由于某种原因停顿了一下,而线程 B 先将值 V 改为 K,然后又将 K 改为 V, 此时 A 再次获取的值仍是 V,然后 A 进行 CAS 比较成功。 虽然 A 两次获取的值是同一个值,但是这个值中间是发生过变化的,也即此时 A 执行 CAS 不应该成功,这就是 ABA 问题。 为了解决ABA问题,可以在对象中额外再增加一个标记来标识对象是否有过变更,当且仅当 标记 与 预期标记位 也相同时,CAS 才可以执行成功。 比如: AtomicStampedReference 或者 AtomicMarkableReference 类。
(5)ABA 再现
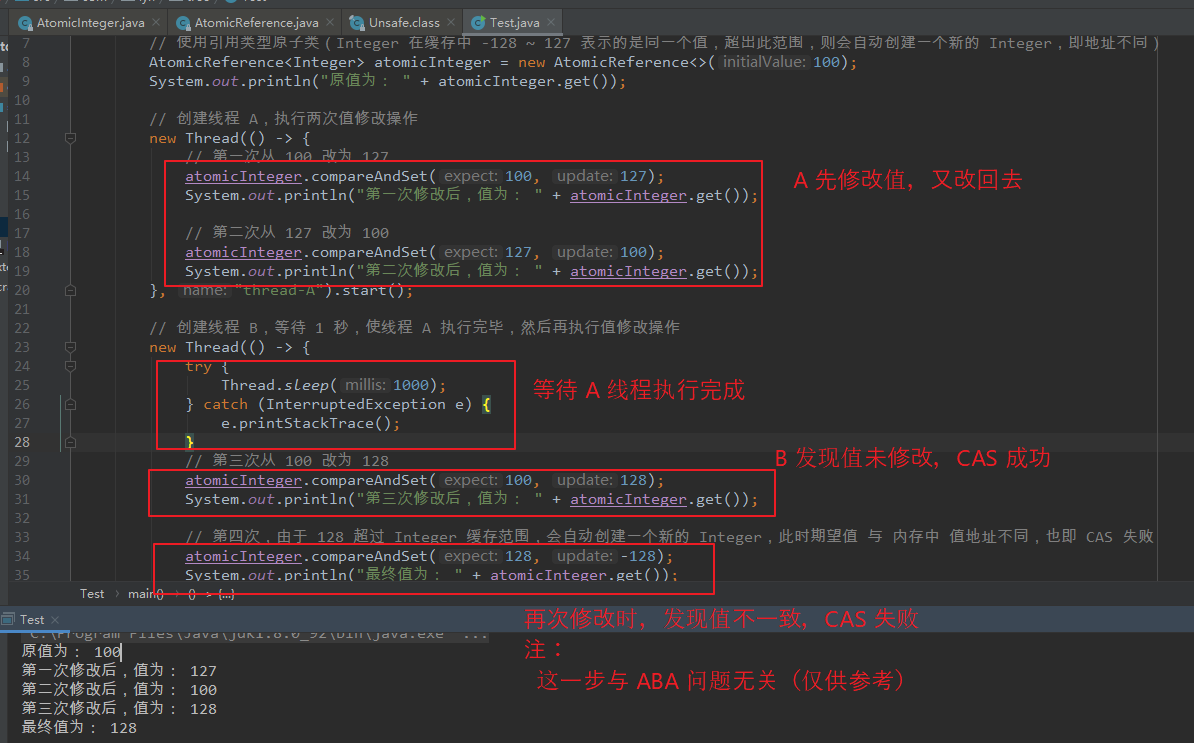
使用 AtomicReference<Integer> 再现 ABA 问题。
【问题再现:】 package com.lyh.tree; import java.util.concurrent.atomic.AtomicReference; public class Test { public static void main(String[] args) { // 使用引用类型原子类(Integer 在缓存中 -128 ~ 127 表示的是同一个值,超出此范围,则会自动创建一个新的 Integer,即地址不同) AtomicReference<Integer> atomicInteger = new AtomicReference<>(100); System.out.println("原值为: " + atomicInteger.get()); // 创建线程 A,执行两次值修改操作 new Thread(() -> { // 第一次从 100 改为 127 atomicInteger.compareAndSet(100, 127); System.out.println("第一次修改后,值为: " + atomicInteger.get()); // 第二次从 127 改为 100 atomicInteger.compareAndSet(127, 100); System.out.println("第二次修改后,值为: " + atomicInteger.get()); }, "thread-A").start(); // 创建线程 B,等待 1 秒,使线程 A 执行完毕,然后再执行值修改操作 new Thread(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 第三次从 100 改为 128 atomicInteger.compareAndSet(100, 128); System.out.println("第三次修改后,值为: " + atomicInteger.get()); // 第四次,由于 128 超过 Integer 缓存范围,会自动创建一个新的 Integer,此时期望值 与 内存中 值地址不同,也即 CAS 失败 atomicInteger.compareAndSet(128, -128); System.out.println("最终值为: " + atomicInteger.get()); }, "thread-B").start(); } } 【结果:】 原值为: 100 第一次修改后,值为: 127 第二次修改后,值为: 100 第三次修改后,值为: 128 最终值为: 128
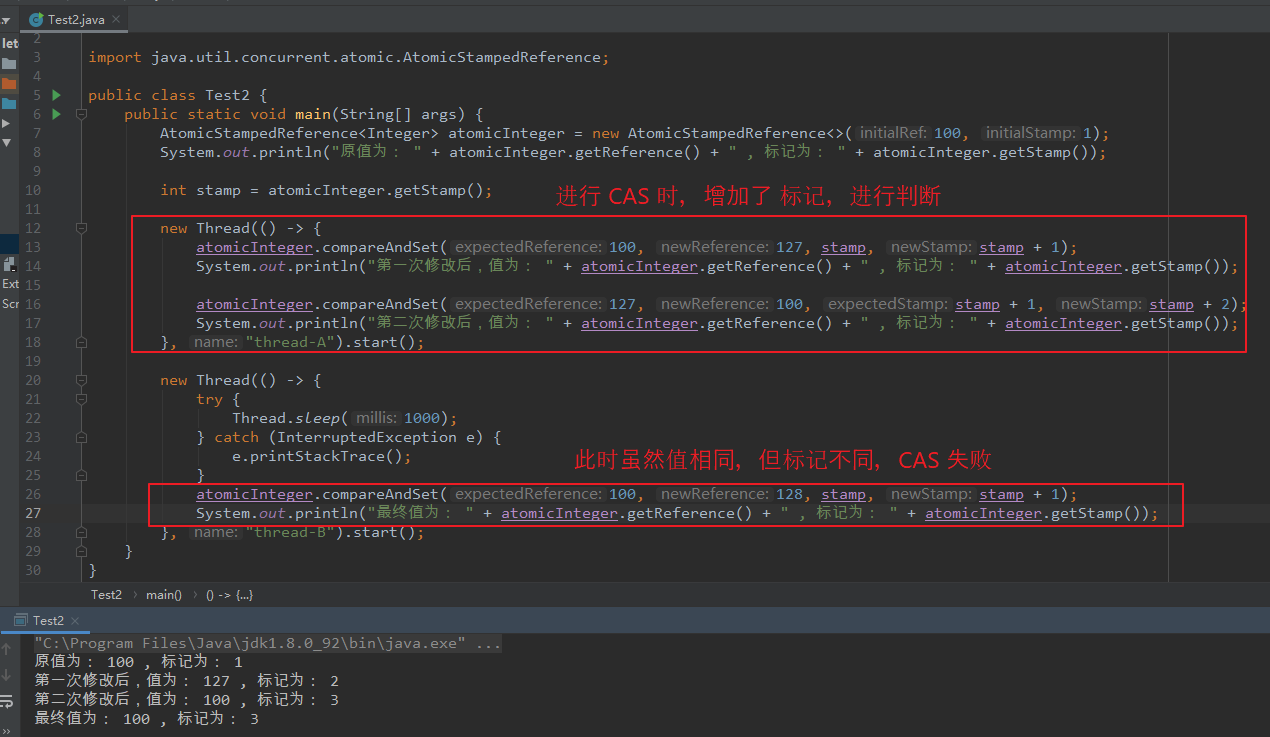
(6)ABA 解决
使用 AtomicStampedReference<Integer> 解决 ABA 问题。
新增了标记位,用于判断当前值是否发生过变化。
package com.lyh.tree; import java.util.concurrent.atomic.AtomicStampedReference; public class Test2 { public static void main(String[] args) { AtomicStampedReference<Integer> atomicInteger = new AtomicStampedReference<>(100, 1); System.out.println("原值为: " + atomicInteger.getReference() + " , 标记为: " + atomicInteger.getStamp()); int stamp = atomicInteger.getStamp(); new Thread(() -> { atomicInteger.compareAndSet(100, 127, stamp, stamp + 1); System.out.println("第一次修改后,值为: " + atomicInteger.getReference() + " , 标记为: " + atomicInteger.getStamp()); atomicInteger.compareAndSet(127, 100, stamp + 1, stamp + 2); System.out.println("第二次修改后,值为: " + atomicInteger.getReference() + " , 标记为: " + atomicInteger.getStamp()); }, "thread-A").start(); new Thread(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } atomicInteger.compareAndSet(100, 128, stamp, stamp + 1); System.out.println("最终值为: " + atomicInteger.getReference() + " , 标记为: " + atomicInteger.getStamp()); }, "thread-B").start(); } }
3、自旋锁(SpinLock)
(1)什么是自旋锁?
【自旋锁:】 指的是当一个线程尝试去获取锁时, 若此时锁已经被其他线程获取,那么当前线程将采用 循环 的方式不断的去尝试获取锁。 当循环执行的某次操作成功获取锁时,将退出循环。 【优点:】 减少了线程上下文切换带来的消耗。 【缺点:】 循环会占用 CPU 资源,若长时间获取不到锁,那么相当于一个死循环在执行。 【举例:】 前面介绍的 Unsafe 类中 getAndAddInt() 即为 自旋锁实现,自旋 CAS 进行值的递增。 public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
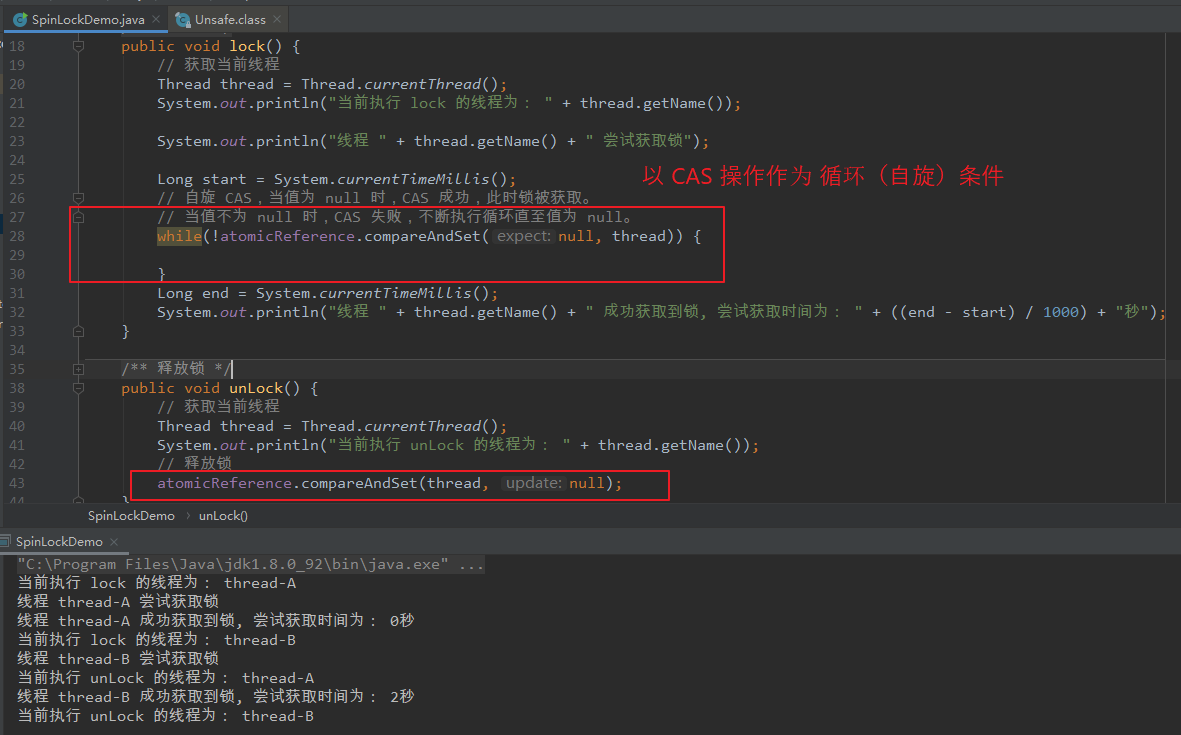
(2)手写一个自旋锁
通过 CAS 操作作为 循环(自旋)条件。
【SpinLockDemo】 package com.lyh.tree; import java.util.concurrent.atomic.AtomicReference; /** * 演示自旋锁(类似于 Unsafe 类中的 getAndAddInt() 方法)。 * * 通过 CAS 操作作为自旋锁条件,A 线程先获取锁,并占用锁时间为 3 秒, * B 线程获取锁,发现锁被 A 占用,B 则执行 循环 等待。 * A 线程释放锁后,B 在某次循环中 CAS 成功,即 B 获取到锁,然后释放。 */ public class SpinLockDemo { private AtomicReference<Thread> atomicReference = new AtomicReference<>(); /** * 获取锁 */ public void lock() { // 获取当前线程 Thread thread = Thread.currentThread(); System.out.println("当前执行 lock 的线程为: " + thread.getName()); System.out.println("线程 " + thread.getName() + " 尝试获取锁"); Long start = System.currentTimeMillis(); // 自旋 CAS,当值为 null 时,CAS 成功,此时锁被获取。 // 当值不为 null 时,CAS 失败,不断执行循环直至值为 null。 while(!atomicReference.compareAndSet(null, thread)) { } Long end = System.currentTimeMillis(); System.out.println("线程 " + thread.getName() + " 成功获取到锁, 尝试获取时间为: " + ((end - start) / 1000) + "秒"); } /** * 释放锁 */ public void unLock() { // 获取当前线程 Thread thread = Thread.currentThread(); System.out.println("当前执行 unLock 的线程为: " + thread.getName()); // 释放锁 atomicReference.compareAndSet(thread, null); } public static void main(String[] args) { SpinLockDemo spinLockDemo = new SpinLockDemo(); // 创建线程 A new Thread(() -> { // A 获取锁 spinLockDemo.lock(); // A 占用锁 3 秒 try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } // A 释放锁 spinLockDemo.unLock(); }, "thread-A").start(); // 等待 1 秒,确保 A 线程先执行 try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 创建线程 B new Thread(() -> { // B 获取锁 spinLockDemo.lock(); // B 释放锁 spinLockDemo.unLock(); }, "thread-B").start(); } } 【输出结果:】 当前执行 lock 的线程为: thread-A 线程 thread-A 尝试获取锁 线程 thread-A 成功获取到锁, 尝试获取时间为: 0秒 当前执行 lock 的线程为: thread-B 线程 thread-B 尝试获取锁 当前执行 unLock 的线程为: thread-A 线程 thread-B 成功获取到锁, 尝试获取时间为: 2秒 当前执行 unLock 的线程为: thread-B
四、服务调用、负载均衡 -- Feign、OpenFeign
1、什么是 Feign、 OpenFeign ?
【Feign:】 Feign 是一个声明式 web service 客户端,使用 Feign 使得编写 Java HTTP 客户端更容易。 SpringCloud 组件中 Feign 作为一个轻量级 Restful 风格的 HTTP 服务客户端,内置了 Ribbon,提供客户端的负载均衡。 使用 Feign 注解定义接口,调用该接口即可访问 服务。 【OpenFeign:】 SpringCloud 组件中 Open Feign 是在 Feign 基础上支持了 SpringMVC 注解。 通过 @FeignClient 注解可以解析 SpringMVC 中 @RequestMapping 等注解下的接口,并通过动态代理的方式产生实现类,在实现类中做负载均衡、服务调用。 【相关地址:】 https://cloud.spring.io/spring-cloud-openfeign/reference/html/ https://github.com/OpenFeign/feign
2、Feign 集成了 Ribbon
前面使用 Ribbon + RestTemplate 实现 负载均衡 以及 服务调用时,
流程如下:
Step1:在配置类中通过 @Bean 声明一下 RestTemplate 类,再添加上 @LoadBalanced 注解。
Step2:在 controller 中注入 RestTemplate 。
Step3:使用 RestTemplate 根据服务名发送 HTTP 请求。
而不同的模块若要调用服务(一个接口可能会被多个模块调用),则每次都要进行 Step1、Step2、Step3。
实际开发中,若不进行处理,对于编码、维护都是一件麻烦的事情。
Feign 就是在 Ribbon 基础上做了进一步封装,只需要创建一个接口,并使用注解的方式进行配置,
即可完成 接口 与 服务提供方接口的绑定。通过自定义的接口即可完成 服务调用。
注:
类似于在 Dao 层接口上添加 @Mapper。
Feign 在接口上添加 @FeignClient,并配置服务名。
3、使用 OpenFeign
(1)说明
【说明:】 创建一个空模块 eureka_client_consumer_9006。 用于测试 OpenFeign 的使用。 注: 创建流程此处省略,详细可参考上一篇博客:https://www.cnblogs.com/l-y-h/p/14193443.html#_label2_3
(2)创建项目 eureka_client_consumer_9006
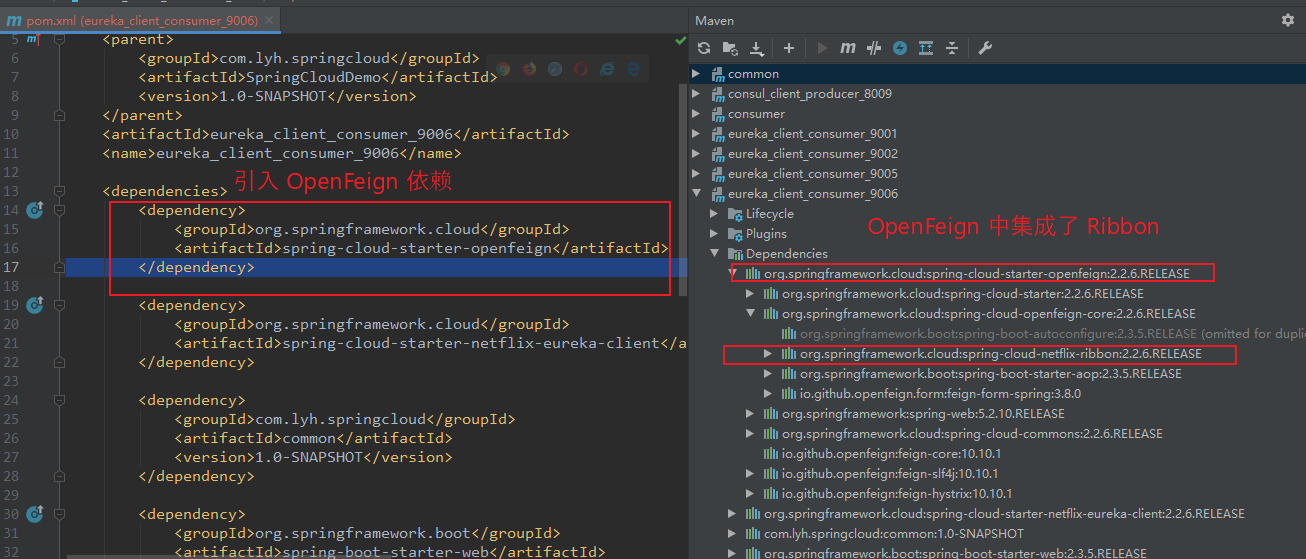
创建 eureka_client_consumer_9006 模块,修改 父工程以及当前工程 pom.xml 文件。
修改配置类。
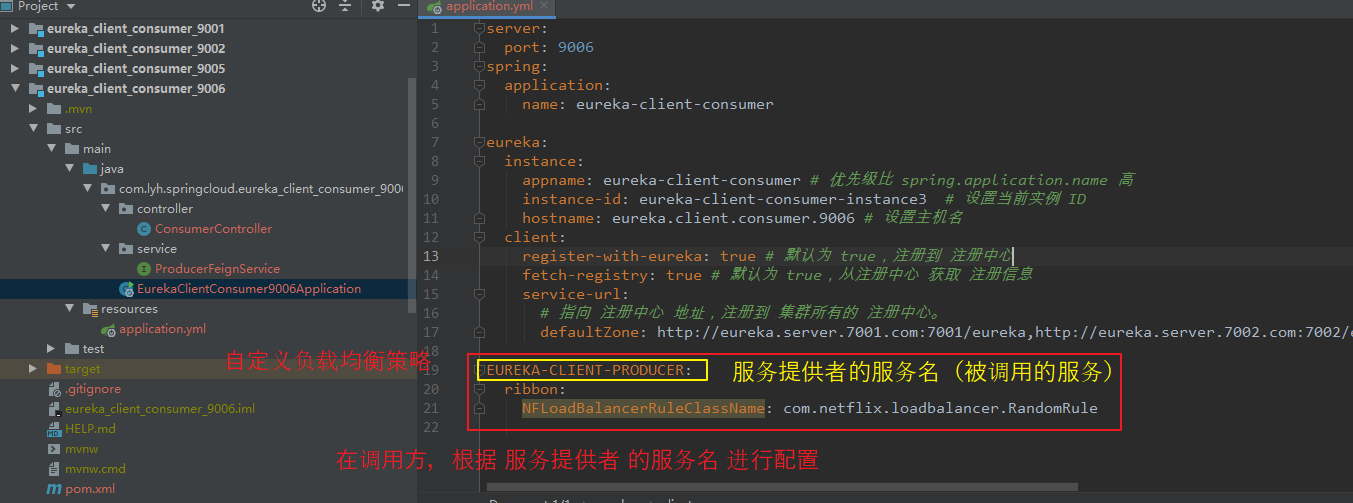
【依赖:】 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> 【application.yml】 server: port: 9006 spring: application: name: eureka-client-consumer eureka: instance: appname: eureka-client-consumer # 优先级比 spring.application.name 高 instance-id: eureka-client-consumer-instance3 # 设置当前实例 ID hostname: eureka.client.consumer.9006 # 设置主机名 client: register-with-eureka: true # 默认为 true,注册到 注册中心 fetch-registry: true # 默认为 true,从注册中心 获取 注册信息 service-url: # 指向 注册中心 地址,注册到 集群所有的 注册中心。 defaultZone: http://eureka.server.7001.com:7001/eureka,http://eureka.server.7002.com:7002/eureka,http://eureka.server.7003.com:7003/eureka

(3)编写接口,绑定服务。
通过 @Component 注解,将该接口交给 Spring 管理(用于 @Autowired 注入)。
通过 @FeignClient 注解配置 服务名,并编写方法,用于绑定需要访问的接口。
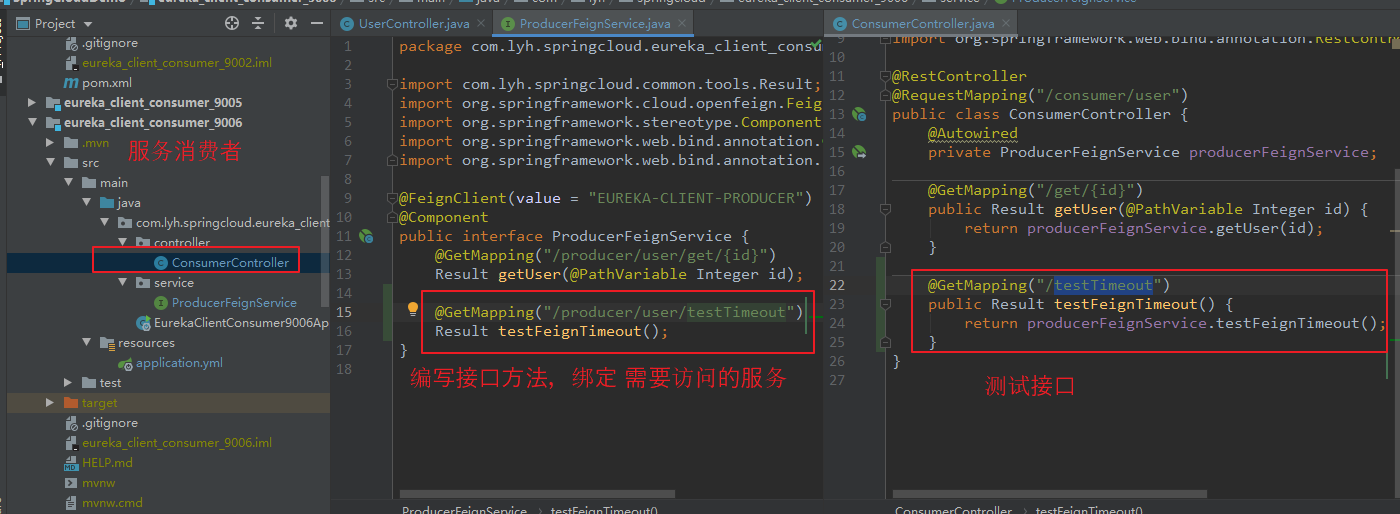
【ProducerFeignService】 package com.lyh.springcloud.eureka_client_consumer_9006.service; import com.lyh.springcloud.common.tools.Result; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.stereotype.Component; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; @FeignClient(value = "EUREKA-CLIENT-PRODUCER") @Component public interface ProducerFeignService { @GetMapping("/producer/user/get/{id}") Result getUser(@PathVariable Integer id); }

(4)编写 controller
【ConsumerController】 package com.lyh.springcloud.eureka_client_consumer_9006.controller; import com.lyh.springcloud.common.tools.Result; import com.lyh.springcloud.eureka_client_consumer_9006.service.ProducerFeignService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/consumer/user") public class ConsumerController { @Autowired private ProducerFeignService producerFeignService; @GetMapping("/get/{id}") public Result getUser(@PathVariable Integer id) { return producerFeignService.getUser(id); } }

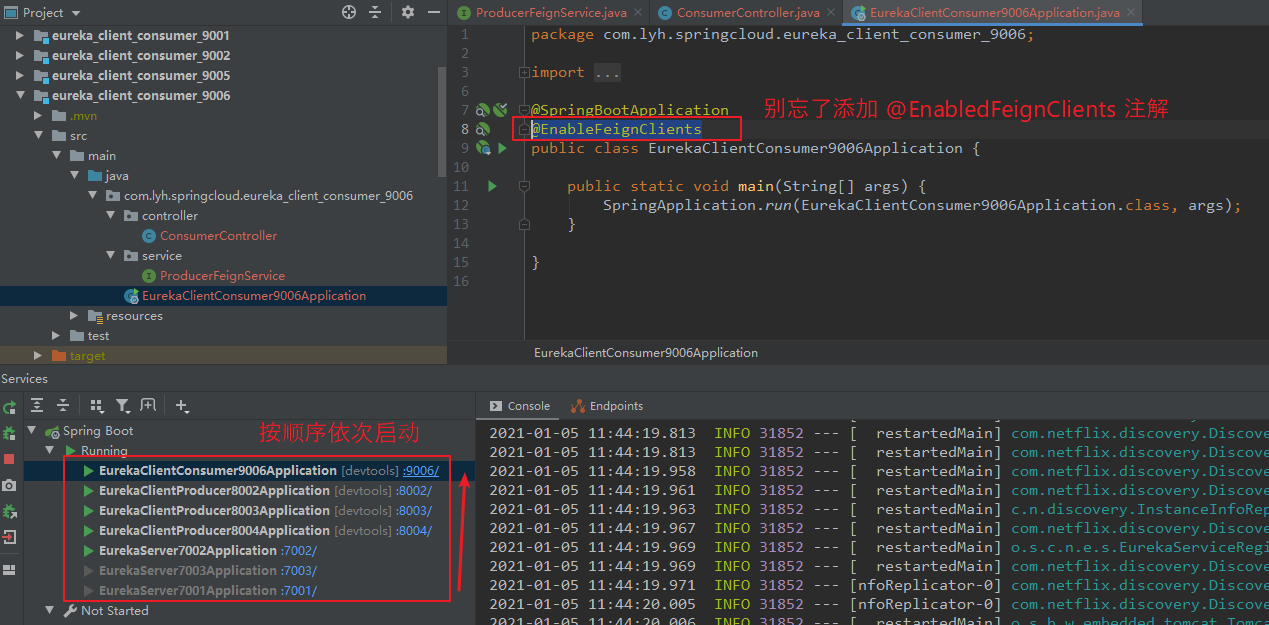
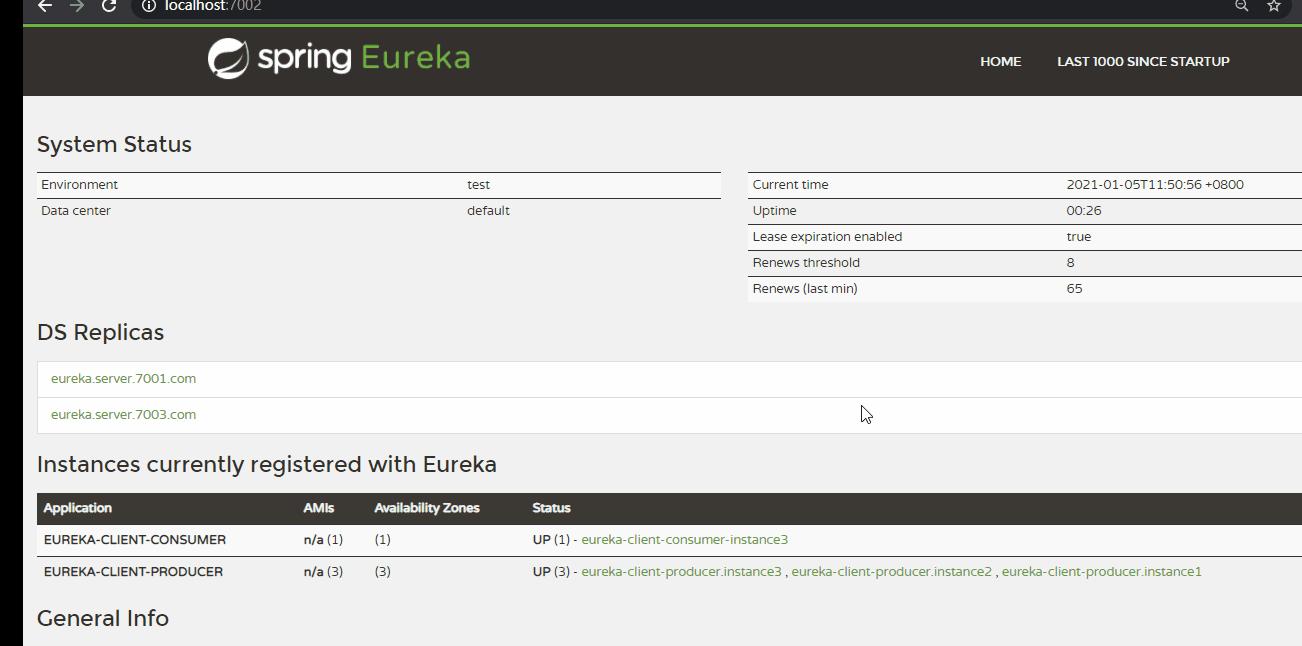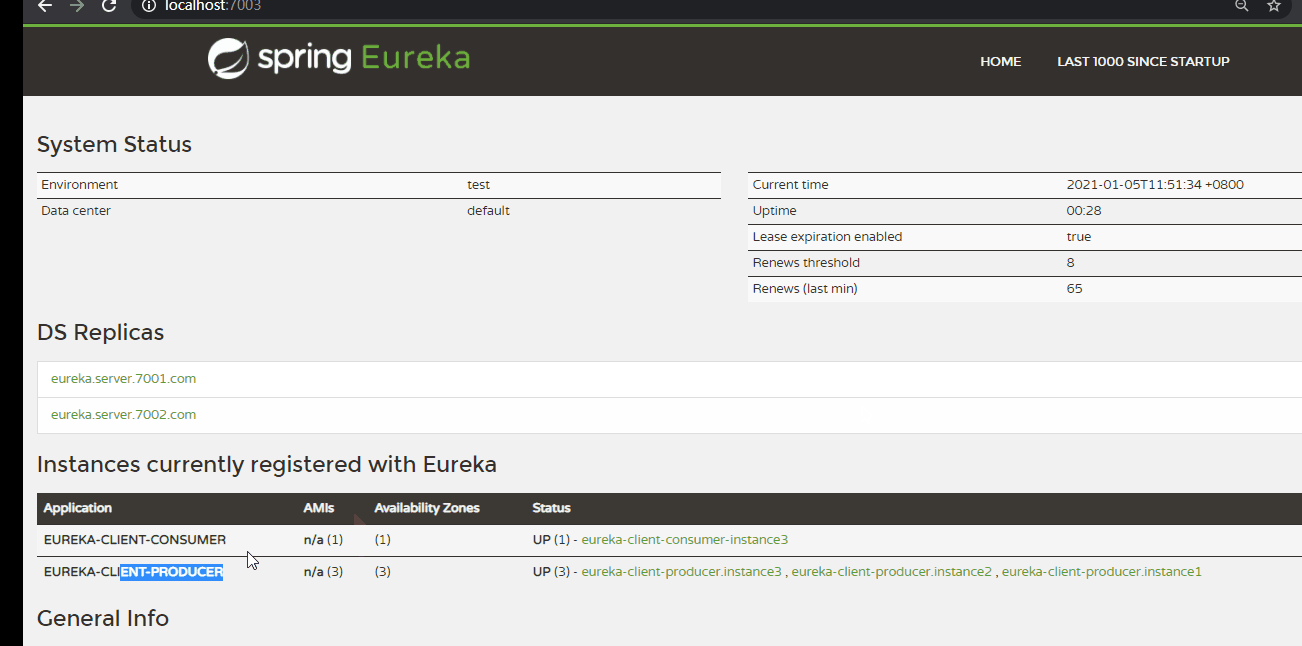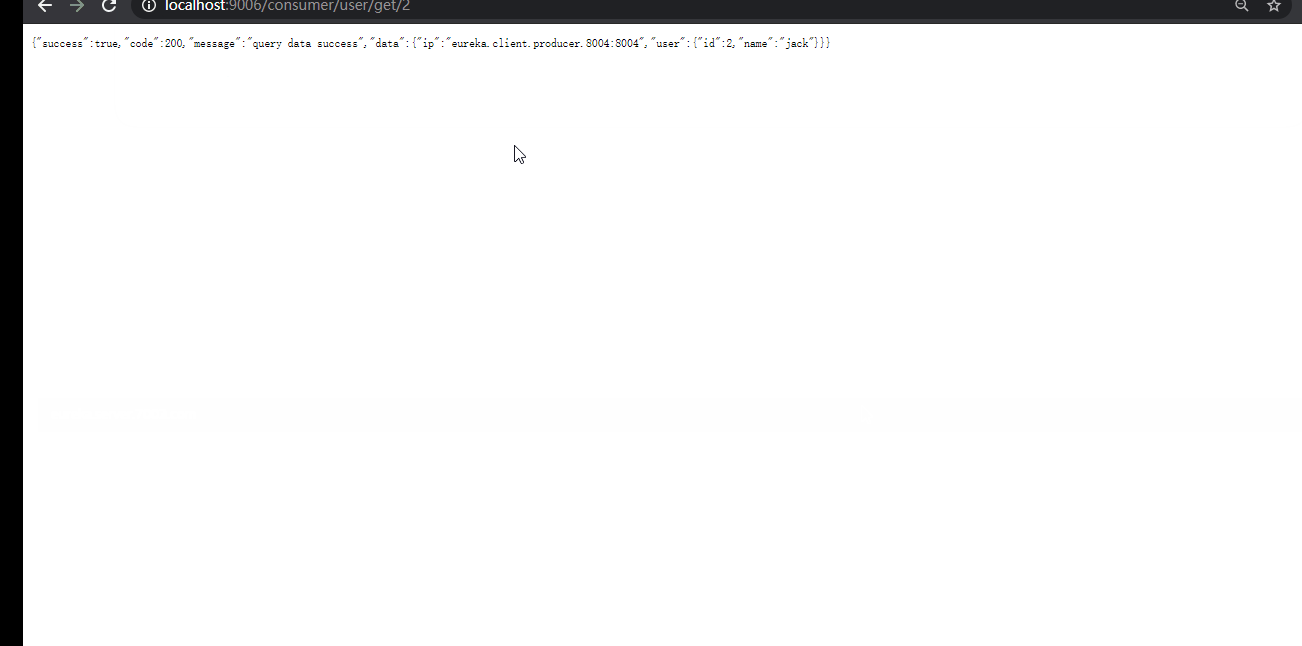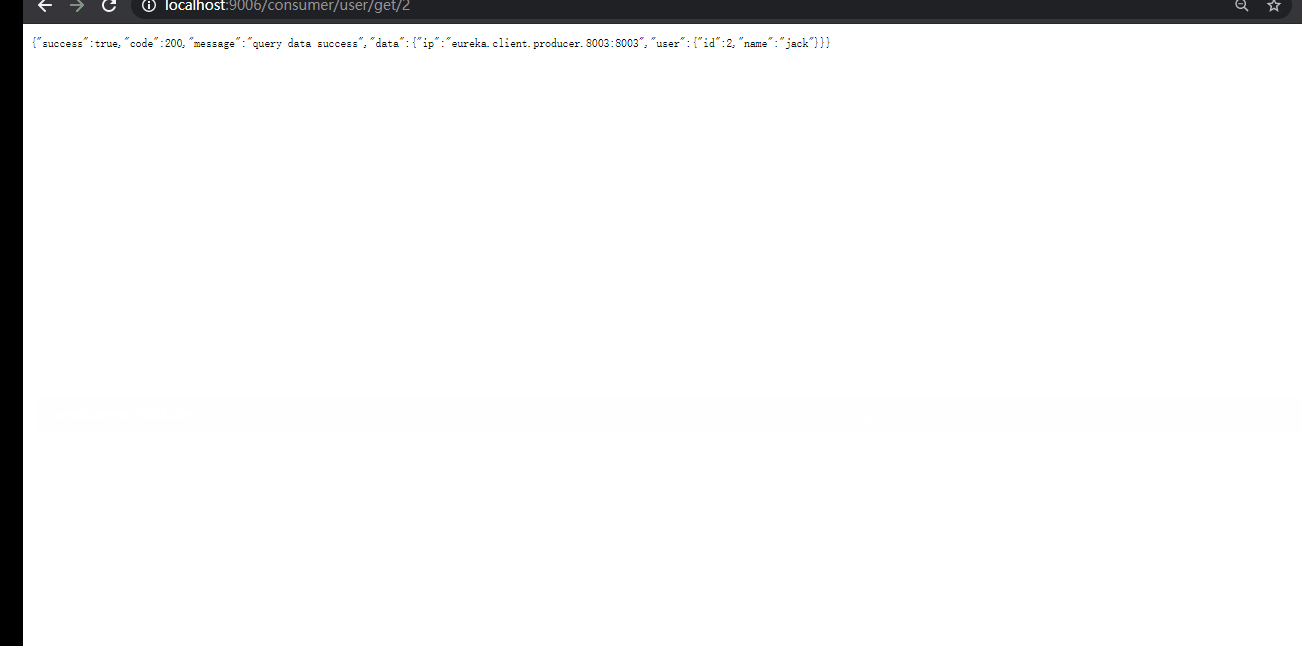
(5)启动服务,并测试。
按顺序依次启动,Eureka Server 以及 Producer。
在 eureka_client_consumer_9006 启动类上添加 @EnableFeignClients 注解,并启动。
效果与使用 ribbon 时相同(默认 ZoneAvoidanceRule 负载均衡规则)。
(6)启动失败时的错误
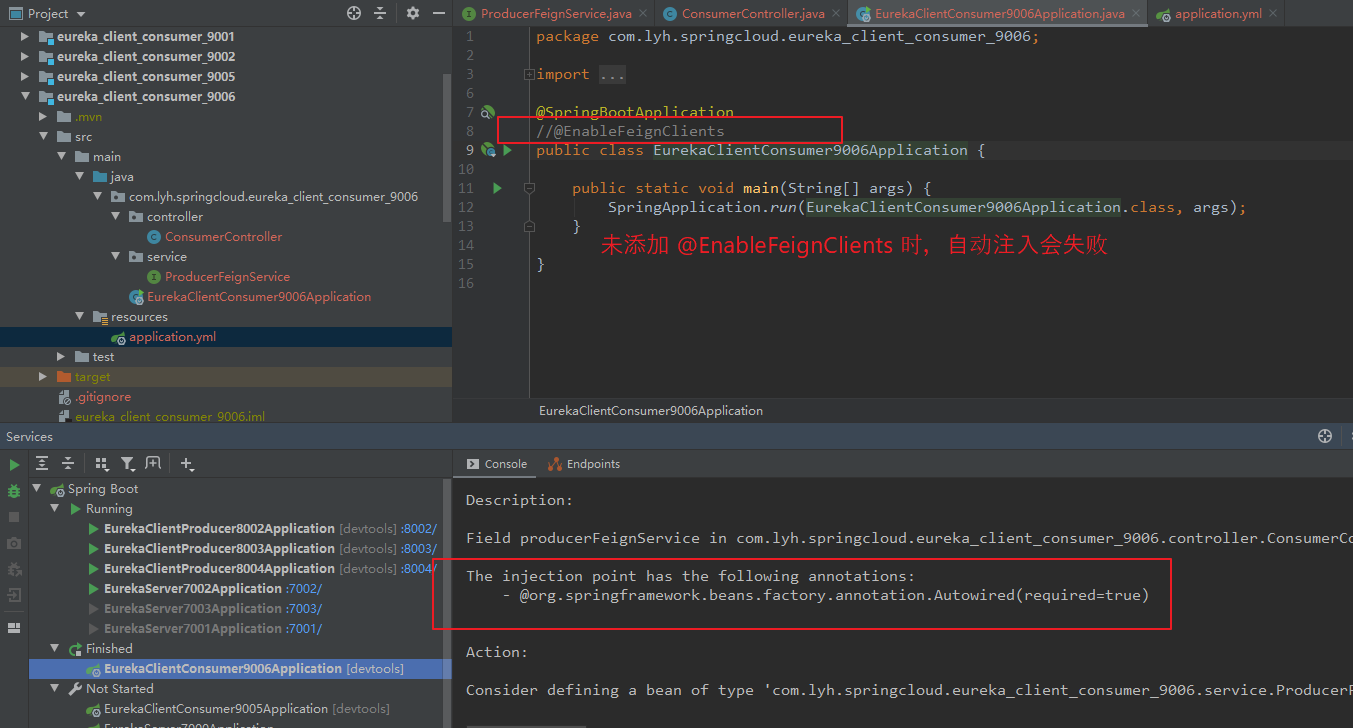
【错误:】 Description: Field producerFeignService in com.lyh.springcloud.eureka_client_consumer_9006.controller.ConsumerController required a bean of type 'com.lyh.springcloud.eureka_client_consumer_9006.service.ProducerFeignService' that could not be found. The injection point has the following annotations: - @org.springframework.beans.factory.annotation.Autowired(required=true) Action: Consider defining a bean of type 'com.lyh.springcloud.eureka_client_consumer_9006.service.ProducerFeignService' in your configuration. 【解决:】 在启动类上添加 @EnableFeignClients 注解。
(7)自定义负载均衡策略
Feign 集成了 Ribbon,所以 Ribbon 自定义负载均衡策略也适用于 Feign。
此处使用配置文件的方式进行自定义负载均衡。
在服务调用方的配置文件中,根据 服务提供者的 服务名,进行 ribbon 负载均衡策略更换。
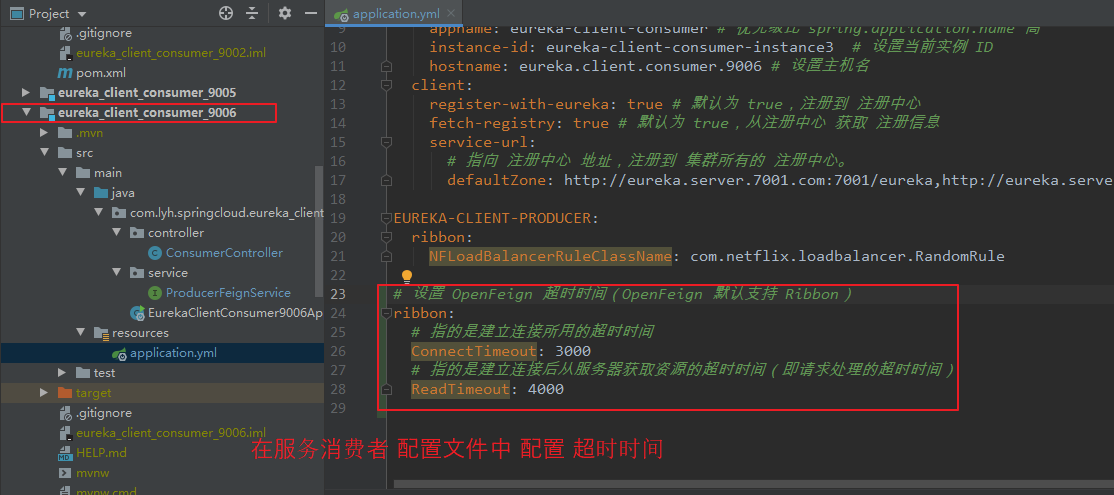
【自定义负载均衡策略:】 EUREKA-CLIENT-PRODUCER: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule 【application.yml】 server: port: 9006 spring: application: name: eureka-client-consumer eureka: instance: appname: eureka-client-consumer # 优先级比 spring.application.name 高 instance-id: eureka-client-consumer-instance3 # 设置当前实例 ID hostname: eureka.client.consumer.9006 # 设置主机名 client: register-with-eureka: true # 默认为 true,注册到 注册中心 fetch-registry: true # 默认为 true,从注册中心 获取 注册信息 service-url: # 指向 注册中心 地址,注册到 集群所有的 注册中心。 defaultZone: http://eureka.server.7001.com:7001/eureka,http://eureka.server.7002.com:7002/eureka,http://eureka.server.7003.com:7003/eureka EUREKA-CLIENT-PRODUCER: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule

4、Feign 超时控制 以及 日志打印
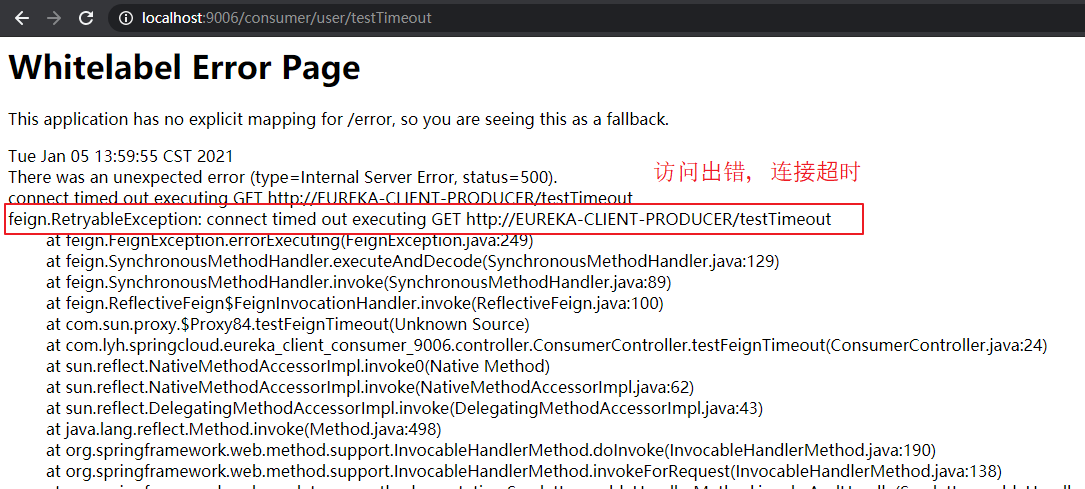
(1)超时控制
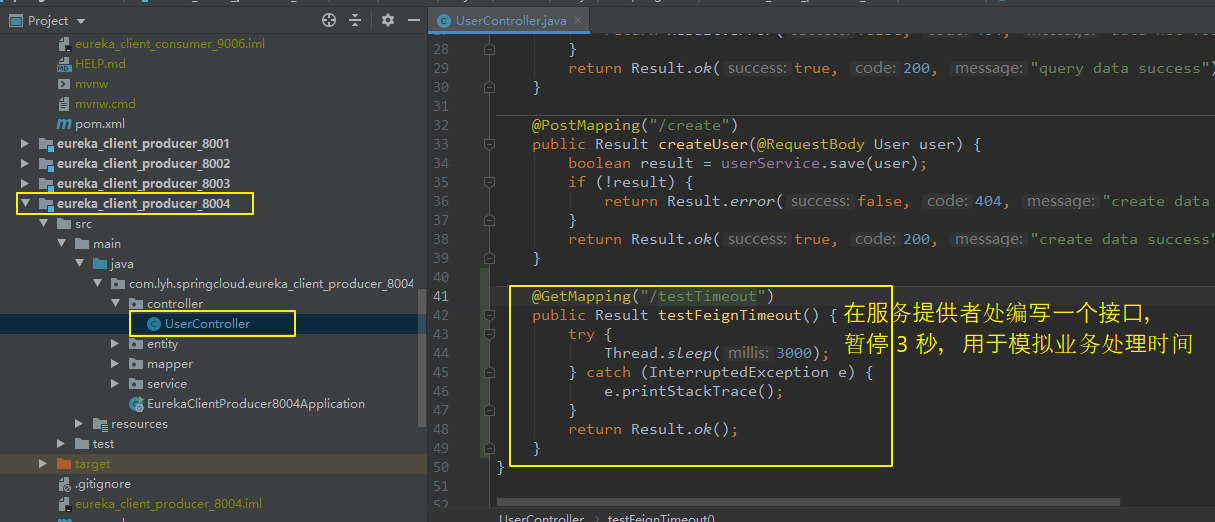
【说明:】 OpenFeign 默认请求等待时间为 1 秒钟,即 若服务器超过 1 秒仍未返回处理结果,那么 OpenFeign 将认为调用出错。 有时服务器业务处理时间需要超过 1 秒,此时直接报错是不合适的。 为了避免这样的问题,可以根据实际情况 适当设置 Feign 客户端的超时控制。 【演示:】 在 服务提供者 eureka_client_producer_8004 提供一个接口,并在内部暂停 3 秒,用于模拟业务处理时间。 在 服务消费者 eureka_client_consumer_9006 中调用并访问接口,用于测试 是否会出错。 在配置文件中 配置超时控制后,再次查看是否出错。 【application.yml】 # 设置 OpenFeign 超时时间(OpenFeign 默认支持 Ribbon) ribbon: # 指的是建立连接所用的超时时间 ConnectTimeout: 3000 # 指的是建立连接后从服务器获取资源的超时时间(即请求处理的超时时间) ReadTimeout: 4000
(2)日志打印
【说明:】
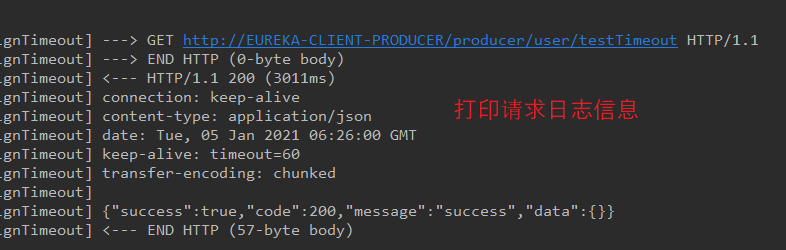
Feign 提供了日志打印功能,通过配置调整日志级别,可以方便了解 Feign 中请求调用的细节。
日志级别:
NONE:默认,不显示任何日志。
BASIC: 仅记录请求方法、URL、响应状态以及执行时间。
HEADERS:包含 BASIC、请求头信息、响应头信息。
FULL:包含 HEADERS、请求数据、响应数据。
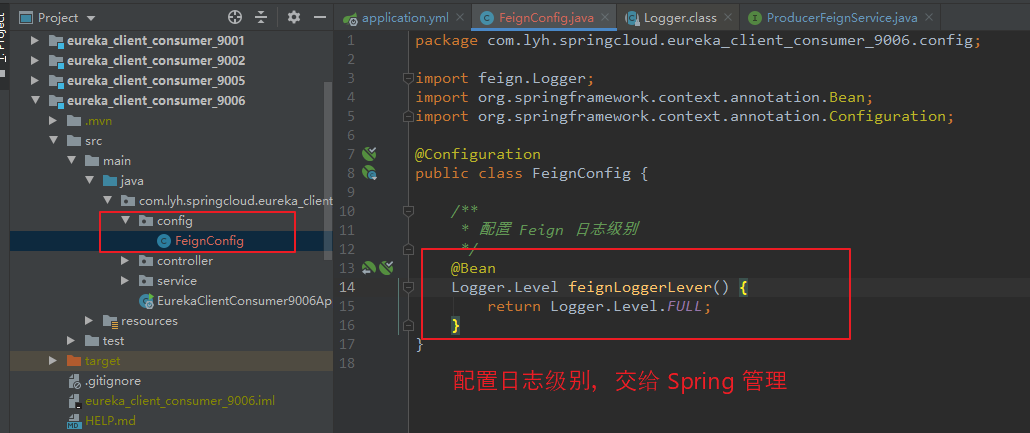
Step1:
配置 日志级别(Logger.Level)。
注:
import feign.Logger。不要导错包了。
package com.lyh.springcloud.eureka_client_consumer_9006.config; import feign.Logger; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class FeignConfig { /** * 配置 Feign 日志级别 */ @Bean Logger.Level feignLoggerLever() { return Logger.Level.FULL; } }
Step2:
配置需要打印日志的接口。
【application.yml】
logging:
level:
com.lyh.springcloud.eureka_client_consumer_9006.service.ProducerFeignService: debug

Step3:
启动服务,并调用服务,可以在控制台看到日志信息。