数据是创造和决策的原材料,高质量的数据都价值不菲。而利用爬虫,我们可以获取大量的价值数据,经分析可以发挥巨大的价值,比如:
豆瓣、知乎:爬取优质答案,筛选出各话题下热门内容,探索用户的舆论导向。
淘宝、京东:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
搜房、链家:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
拉勾、智联:爬取各类职位信息,分析各行业人才需求情况及薪资水平。
雪球网:抓取雪球高回报用户的行为,对股票市场进行分析和预测。

爬虫是入门Python最好的方式,没有之一。Python有很多应用的方向,比如后台开发、web开发、科学计算等等,但爬虫对于初学者而言更友好,原理简单,几行代码就能实现基本的爬虫,学习的过程更加平滑,你能体会更大的成就感。
掌握基本的爬虫后,你再去学习Python数据分析、web开发甚至机器学习,都会更得心应手。因为这个过程中,Python基本语法、库的使用,以及如何查找文档你都非常熟悉了。
何为爬虫?简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
今天我们来讲一个爬虫实例。爬取当当网数据以及图片。
一、首先我们需要安装python环境
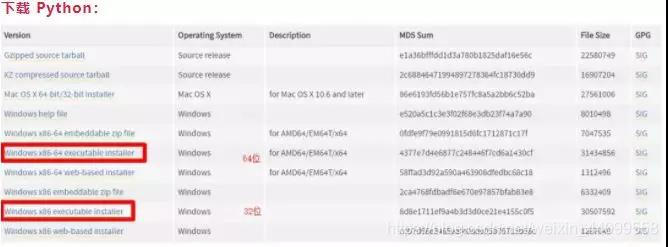
![]()
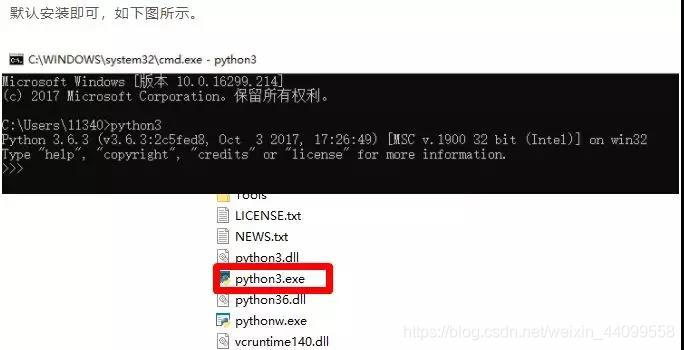
![]()
二、安装编辑器,这里我们就选pycharm吧,安装只需要默认选择即可。
1.第一种安装库模块的方式为:打开 Pycharm IDE,选择 file-Settings,如下图所示
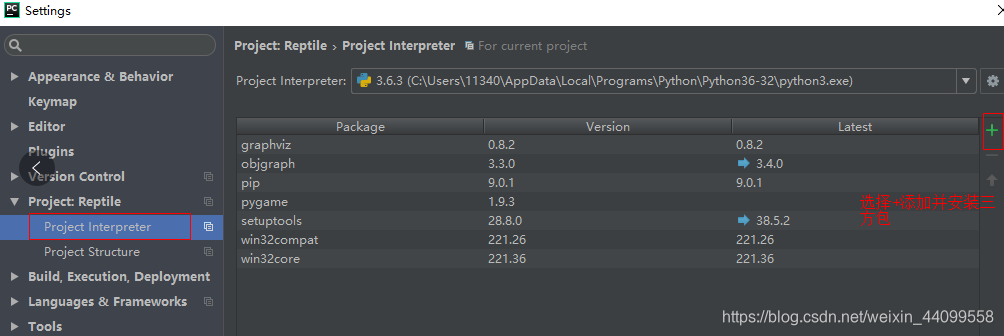
![]()
这时我们选择右方的"+"符号,如下图所示:
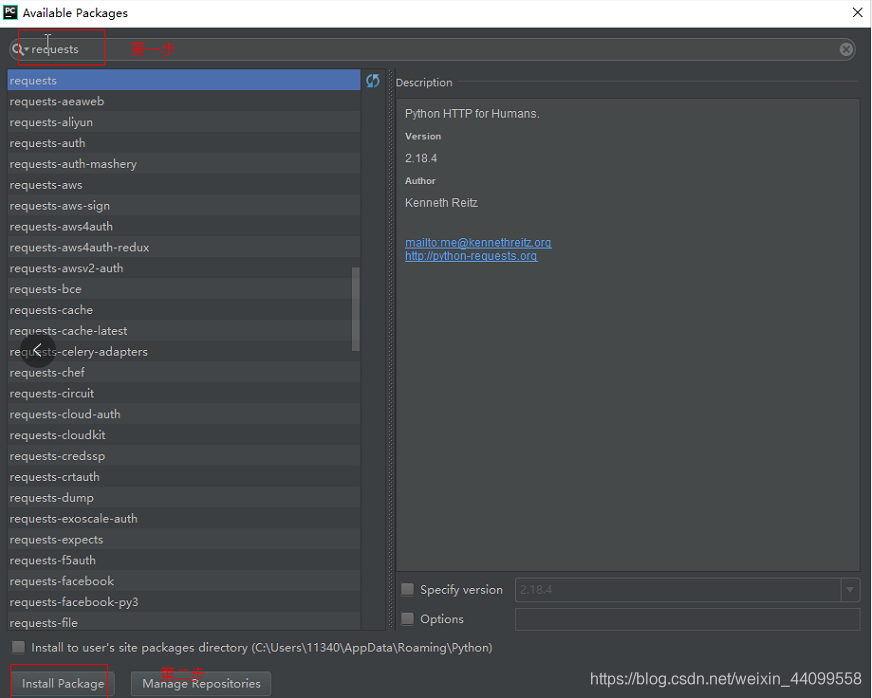
![]()
三、上代码!我们用的是scrapy框架~
1.首先设置settings包括设置数据库基础信息,你的pipeline,还有图片下载位置
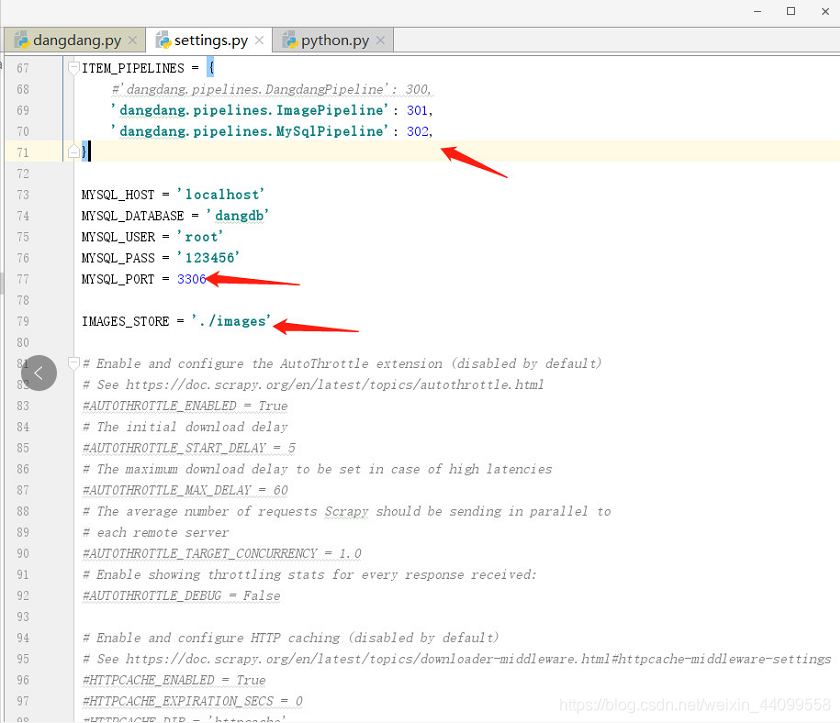
![]()
2.item设置存入数据库字段为后期存入数据库做准备
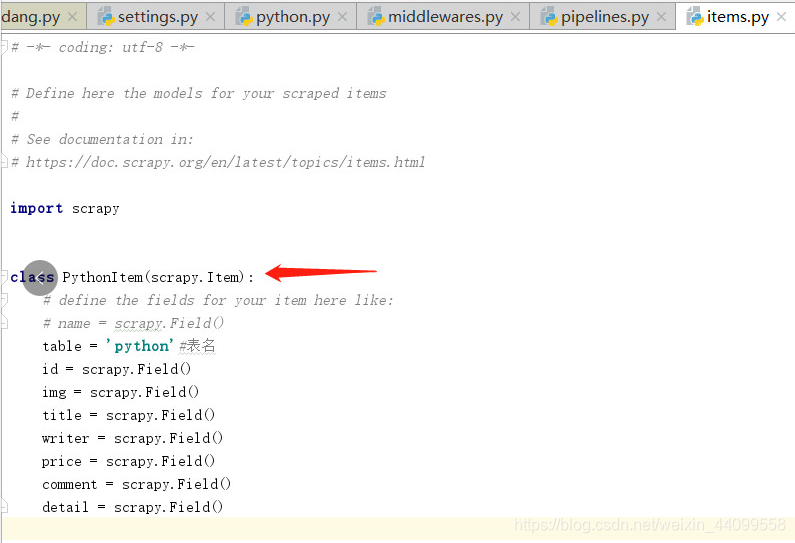
![]()
3.spider.py文件,主要通过请求地址,发送请求,将返回数据返回到parse方法,在parse方法中利用选择器去选择我们需要存入数据库的字段,以及设置需要爬去多少页
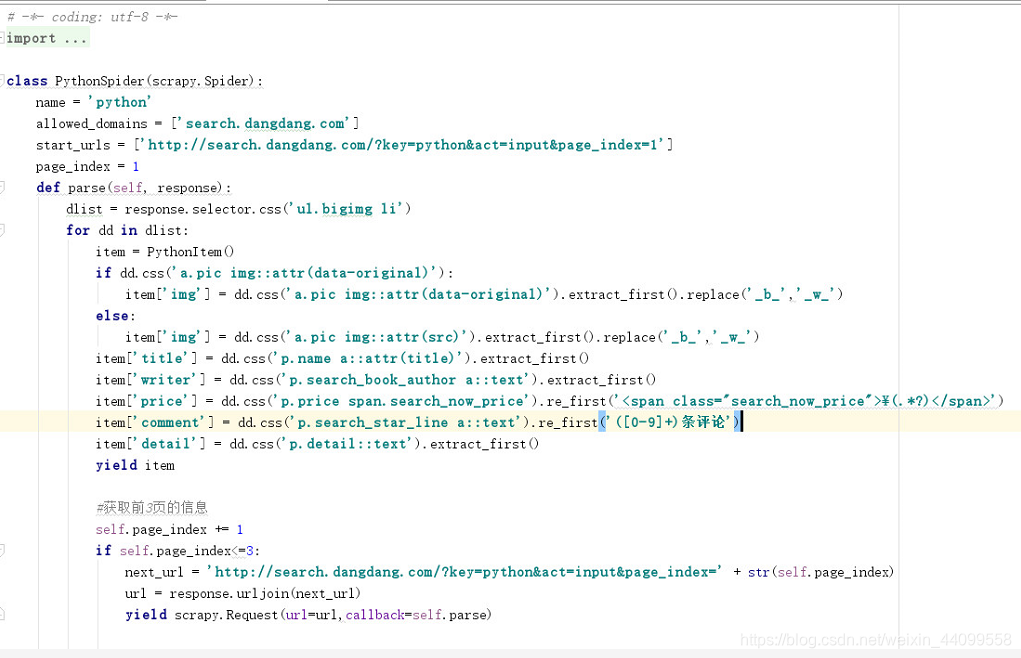
![]()
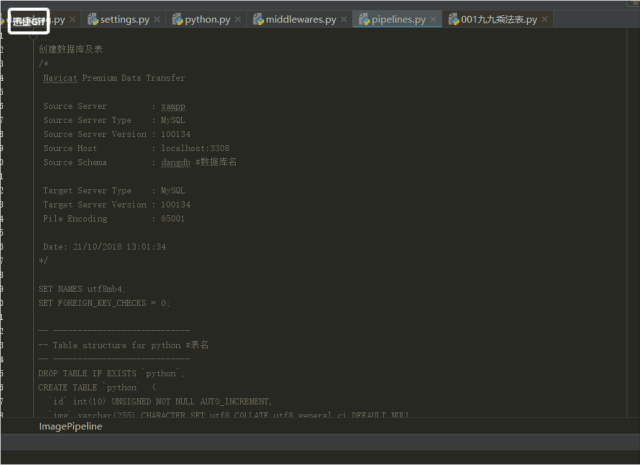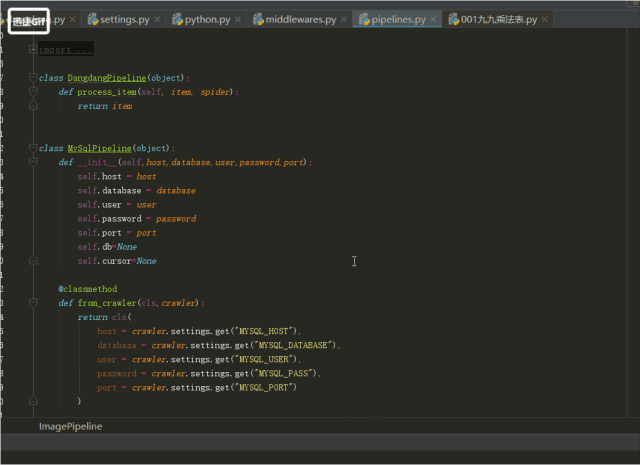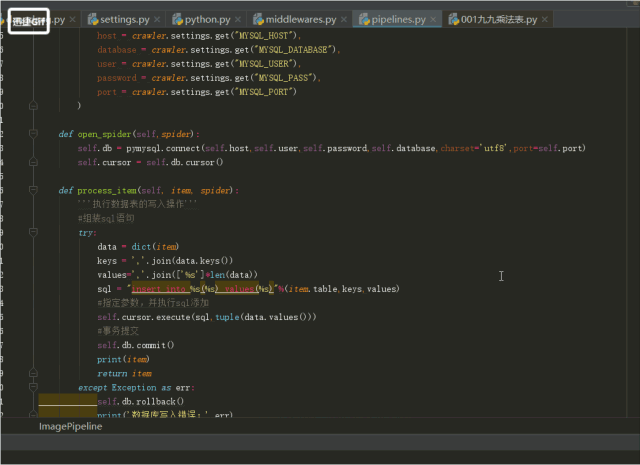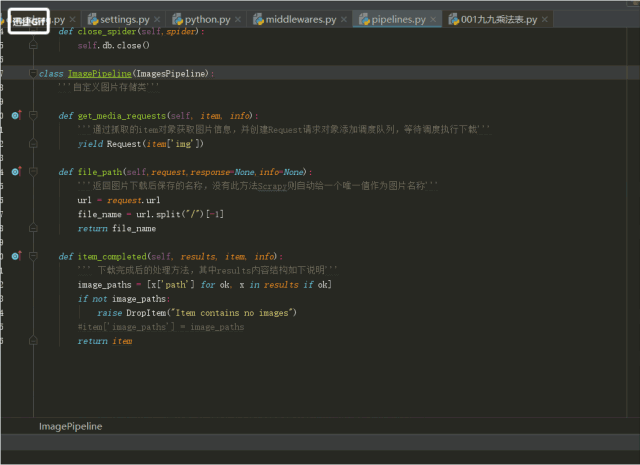
4.pipeline是用存储数据的文件,将数据存入数据库,操作数据的
![]()
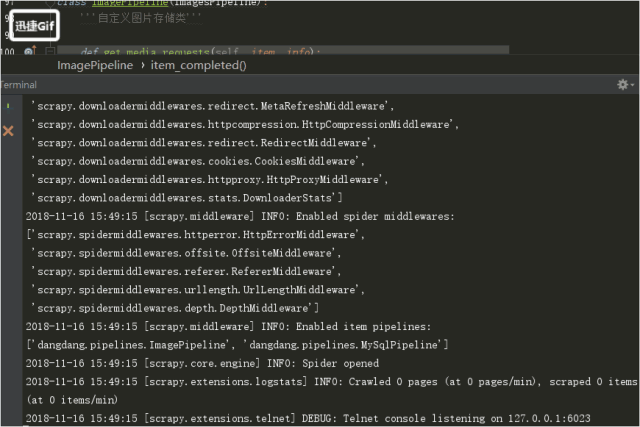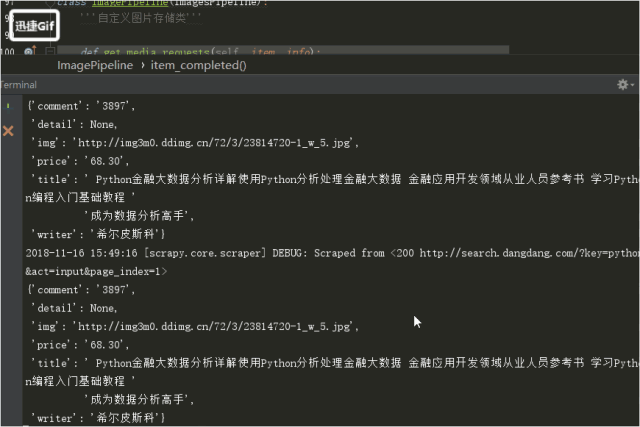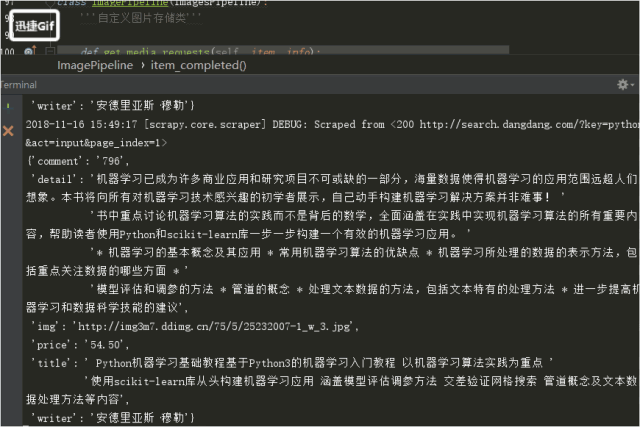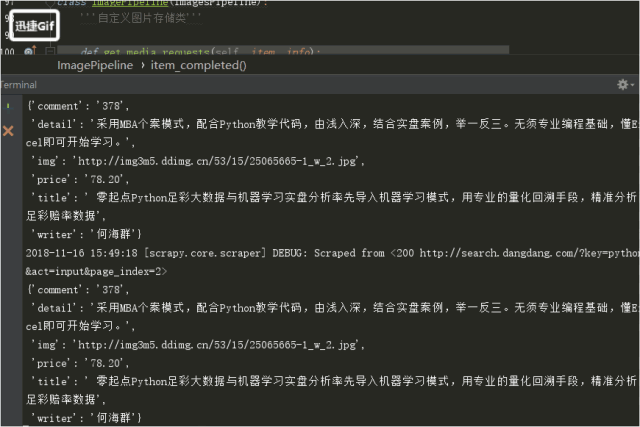
5.运行
![]()
结果!!!!
数据库
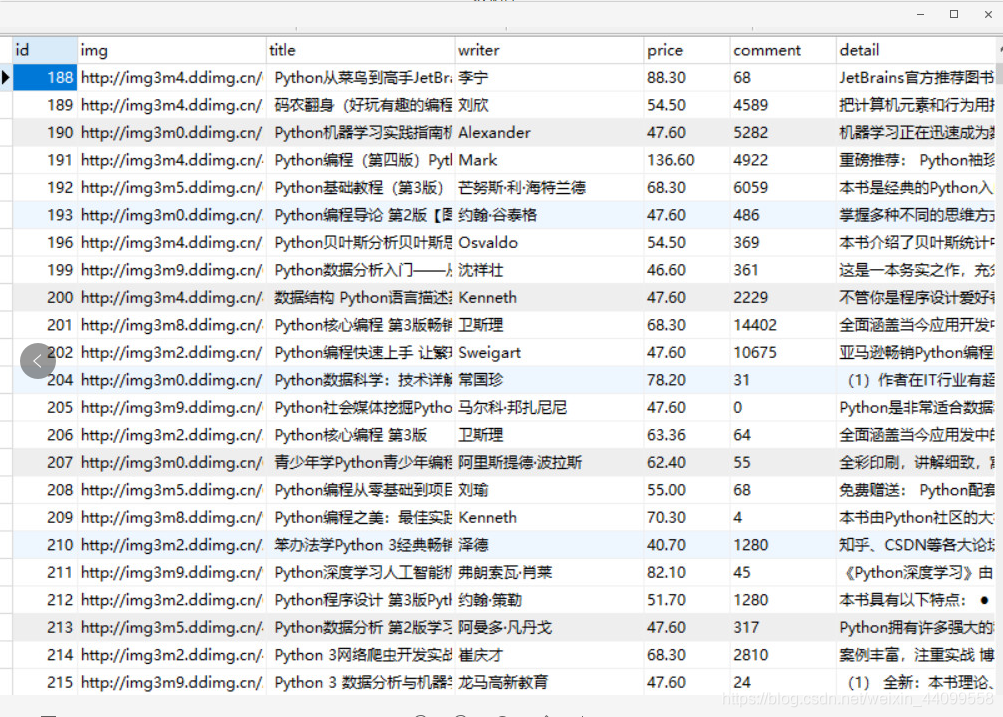
![]()
爬取的图片
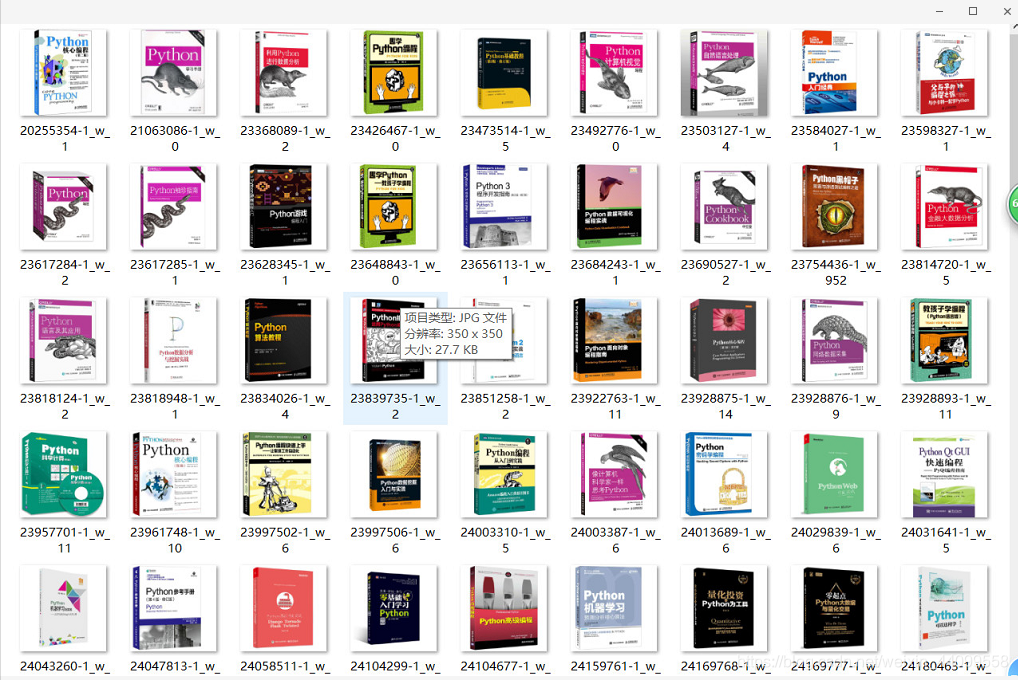
![]()
这样爬取信息效率很高哒~你看,这一条学习路径下来,你已然可以成为老司机了,非常的顺畅。所以在一开始的时候,尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这种简单的入手),直接开始就好。