之前学习过标准库,最近身边有人问到相关话题,故在此做一个总结
1 标准库介绍
C++标准库:C++ Standard Library
C++标准模板库:Standard Template Library(STL)
1.1 二者关系及表现形式
- 标准库是由编译器提供的(比如我们常见的VC,GCC...),STL属于标准库的一部分(占比绝大部分),标准库一定是包含(大于)STL的;
- 标准库引用形式:
-
- 都是以头文件的形式提供不带.h,比如:#include<vector>;
- 新式c头文件一般是:#include<cstdio>;
- 命令空间:namespace std;
引用方法:
1 #include <iostream> 2 #include <cstdio> //snprintf() 3 #include <cstdlib> //RAND_MAX 4 #include <cstring> //strlen(), memcpy() 5 #include <string> 6 using namespace std; 7 using std::cin; 8 using std::cout; 9 using std::string;
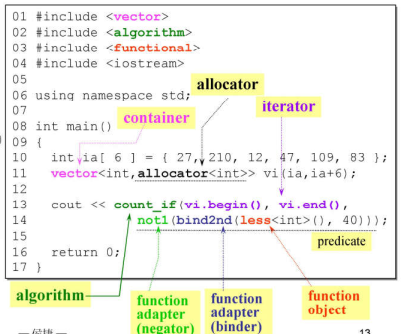
1.2 STL六大部件

以上的六大部件解释如下:
- 容器:容器就是我们存放数据的地方,相当于数据仓库,实现方式是类模板;
- 分配器:管理容器背后的内存使用,实现方式是类模板;
- 算法:常见的比如排序、查找等,实现方式是函数模板;
- 迭代器:算法操作容器的桥梁,是一种泛化的指针,实现方式是类模板;
- 仿函数:或者叫Function Object,它是一个类对象,其次它重载了
()操作符,使用在自定义类对象时,比如我们对石头进行排序,在算法操作时就可以写一些仿函数供算法正确使用,实现方式时类模板; - 适配器:相对于迭代器、仿函数、容器的数据转换,实现方式是类模板。
1.3 STL的简单使用
1.4 事间复杂度
要讨论时间复杂度,其中n必须建立在足够大的工业数据基础上

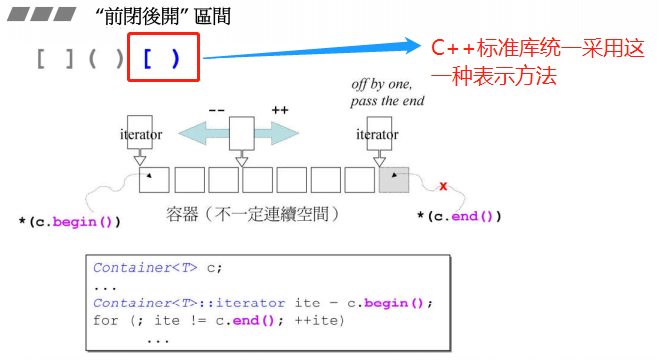
1.5 STL中的区间表示法
STL采用前闭后开区间表示数据的范围,所有的数据都是通过begin()和end()两个函数表示数据的范围,begin表示数据的头,end表示数据尾的下一个元素,也就是说,对end进行解引用操作得到的指针它是不确定的东西,也可能造成程序宕机或者其他不是你心里所想的东西。
2 容器分类
容器分为序列式容器和关联式容器(分为有序和无序),红色部分是c++2.0引入的

序列式容器(Sequence Container):元素都是有序的,里面的空间可能是连续的,也可能是由指针一个个串起来的;
关联式容器(Associative Container):元素是由key和value组成的,当然用key能很快找value,适用于查找操作
2.1 序列式容器(Sequence Container)
2.1.1 Array
对比于c语言的数组,标准库进行封装,初始化的时候就要确定大小,不能扩展(注意在栈上有大小限制,不同的机器内存限制不一样);
2.1.2 Vector
一种可以动态扩充的数组,只能在容器的末端进行扩充,当容量不足时会自动扩充,扩充规则为当前空间的2倍,内存由Vector背后的分配器进行,使用者不用关心内存分配问题;
2.1.3 Deque
双端队列,容器两端均可进行数据扩充;
2.1.4 List
双向环状链表,内存占用比Forward_List多;
2.1.5 Forward_List
单向链表,只能从尾部扩充。
2.2 关联式容器(Associative Container)-- 有序
元素key是有序
2.2.1 Set/MultSet
目前各大厂商编译器都是由红黑树(RBtree)实现,保证每个子树根节点键值大于左子树所有节点的键值,小于右子树所有节点的键值,左右是高度平衡的防止某一个分支比较长,每个元素由key和value组成,set中key和value是同一个值,key和value是不分的,元素不可重复,当重复放入时容器会反弹回来;
MultSet表示元素可以重复。
2.2.2 Map/Multimap
目前各大厂商编译器也都是由红黑树实现,区别于set,每个元素分为key和value,同样元素不可重复,当重复放入时容器会反弹回来;
Multimap表示元素可重复,也就是key-value可重复。
2.3 无序容器(Unordered Container)-- 无序
元素的key是无序的;
Unordered set和Unordered map底层是由哈希表(Hashtable)实现,用哈希表必然存在元素碰撞问题,所以各大编译器都采用Separate Chaining哈希表。