先说说分区的好处吧!
1) 增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
2) 维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
3) 均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;
4) 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
Oracle数据库提供对表或索引的分区方法有三种:
ü 范围分区
ü Hash分区(散列分区)
ü 复合分区
一、范围分区详细说明
范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据序号分区,根据时间等来进行分区。根据序号,比如小于2000000的放在part01, 2000000~4000000的放在part02。。。
create table AAA
(
id number primary key,
indate date not null
)
partition by range(indate)
(
partition part_01 values less than(to_date('2006-01-01','yyyy-mm-dd'))tablespace space01,
partition part_02 values less than(to_date('2010-01-01','yyyy-mm-dd'))tablespace space02,
partition part_03 values less than(maxvalue)tablespace space03
);
space01 space02 space03为建立的三个表空间,相当于把建立的一个大的表分在了3个不同的表空间的分区上了。
二、Hash分区(散列分区)详细说明
散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。也就是只命名分区名称,这样均匀进行数据分布。
三、复合分区详细说明
有时候我们需要根据范围分区后,每个分区内的数据再散列地分布在几个表空间中,这样我们就要使用复合分区。复合分区是先使用范围分区,然后在每个分区内再使用散列分区的一种分区方法。
partition by range(indate)subpartition by hash(id)
subpartitions 3 store in (space01, space02, space03)
(
partition part_01 values less than(to_date(’2006-01-01’,’yyyy-mm-dd’)),
partition part_02 values less than(to_date(’2010-01-01’,’yyyy-mm-dd’)),
partition part_03 values less than(maxvalue)
);
四、分区表操作
1、插入记录:insert into AAA values(1 ,sysdate);
2、查询分区表记录:select * from AAA partition(part_01);
3、更新分区表的记录:update AAA partition(part_01) t set indate=’’where id=1; 但是当更新的时候指定了分区,而根据查询的记录不在该分区中时,将不会更新数据
4、删除分区表记录:delete from AAA partition(part_02) t where id=4; 如果指定了分区,而条件中的数据又不在该分区中时,将不会删除任何数据。
5、增加一个分区:alter table AAA add partition part_04 values less than(to_date(’2012-01-01’,’yyyy-mm-dd’)) tablespace dinya_spa ce03; 增加一个分区的时候,增加的分区的条件必须大于现有分区的最大值,否则系统将提示ORA-14074 partition bound must collate higher than that of the last partition 错误。
6、合并一个分区:alter table AAA merge partitions part_01,part_02 into partition part_02; ,如果在合并的时候把合并后的分区定为part_01的时候,系统将提示ORA-14275 cannot reuse lower-bound partition as resulting partition 错误。
7、删除分区:alter table AAA drop partition part_01; 删除分区表的一个分区后,查询该表的数据时显示,该分区中的数据已全部丢失,所以执行删除分区动作时要慎重,确保先备份数据后再执行,或将分区合并。
五、建立索引
分区表和一般表一样可以建立索引,分区表可以创建局部索引和全局索引。当分区中出现许多事务并且要保证所有分区中的数据记录的唯一性时采用全局索引。
1. 局部索引分区的建立:create index idx_t on AAA(id)
local
(
partition idx_1 tablespace space01,
partition idx_2 tablespace space02,
partition idx_3 tablespace space03
);
2. 全局索引建立时global 子句允许指定索引的范围值,这个范围值为索引字段的范围值:create index idx_t on AAA(id)
global partition by range(id)
(
partition idx_1 values less than (1000) tablespace space01,
partition idx_2 values less than (10000) tablespace space02,
partition idx_3 values less than (maxvalue) tablespace space03
);
当然也可以不指定索引分区名直接对整个表建立索引:
create index idx_t on AAA(id);
数据切分可以是物理上的,对数据通过一系列的切分规则将数据分布到不同的DB服务器上,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。
数据切分也可以是数据库内的,对数据通过一系列的切分规则,将数据分布到一个数据库的不同表中,比如将article分为article_001,article_002等子表,若干个子表水平拼合有组成了逻辑上一个完整的article表,这样做的目的其实也是很简单的。 举个例子说明,比如article表中现在有5000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成100 个table呢,从article_001一直到article_100,5000w行数据平均下来,每个子表里边就只有50万行数据,这时候我们向一张只有50w行数据的table中insert数据后建立索引的时间就会呈数量级的下降,极大了提高了DB的运行时效率,提高了DB的并发量。当然分表的好处还不知这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
综上,分库降低了单点机器的负载;分表,提高了数据操作的效率,尤其是Write操作的效率。

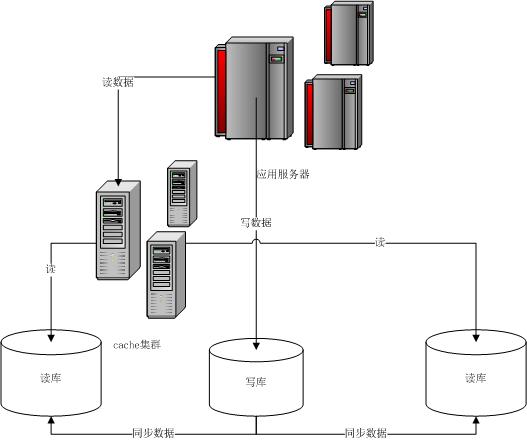
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
为什么要分库、分表、读写分?
单表的数据量限制,当单表数据量到一定条数之后数据库性能会显著下降。数据多了之后,对数据库的读、写就会很多。分库减少单台数据库的压力。接触过几个分库分表的系统,都是通过主键进行散列分裤分表的。这类数据比较特殊,主键就是唯一的获取该条信息的主要途径。比如:京东的订单、财付通的交易记录等。。。该类数据的用法,就是通过订单号、交易号来查询该笔订单、交易。
还有一类数据,比如用户信息,每个用户都有系统内部的一个userid,与userid对应的还有用户看到的登录名。那么如果分库分表的时候单纯通过userid进行散列分库,那么根据登录名来获取用户的信息,就无法知道该用户处于哪个数据库中。
或许有朋友会说,我们可以维护一个email----userid的映射关系,根据email先查询到userid,在根据userid的分库分表规则到对应库的对应表来获取用户的记录信息。这么做是可以的,但是这个映射关系的条数本身也是个瓶颈,原则上是没有减少单表内数据的条数,算是一个单点。并且要维护这个映射关系和用户信息的一致性(修改登录名、多登录名等其他特殊需求),最大一个原因,其实用户信息是一个读大于写的库,web2.0都是以用户为中心,所有信息都和用户信息相关联,所以对用户信息拆分还是有一定局限性的。
对于这类读大于写并且数据量增加不是很明显的数据库,推荐采用读写分离+缓存的模式,试想一下一个用户注册、修改用户信息、记录用户登录时间、记录用户登录IP、修改登录密码,这些是写操作。但是以上这些操作次数都是很小的,所以整个数据库的写压力是很小的。唯一一个比较大的就是记录用户登录时间、记录用户登录IP这类信息,只要把这些经常变动的信息排除在外,那么写操作可以忽略不计。所以读写分离首要解决的就是经常变化的数据的拆分,比如:用户登录时间、记录用户登录IP。这类信息可以单独独立出来,记录在持久化类的缓存中(可靠性要求并不高,登陆时间、IP丢了就丢了,下次来了就又来了)
以oracle为例,主库负责写数据、读数据。读库仅负责读数据。每次有写库操作,同步更新cache,每次读取先读cache在读DB。写库就一个,读库可以有多个,采用dataguard来负责主库和多个读库的数据同步。