一.关于gpt2的理论网上有很多资料(推荐https://jalammar.github.io/illustrated-gpt2/),它源自transformer-decoder部分,话不多説。
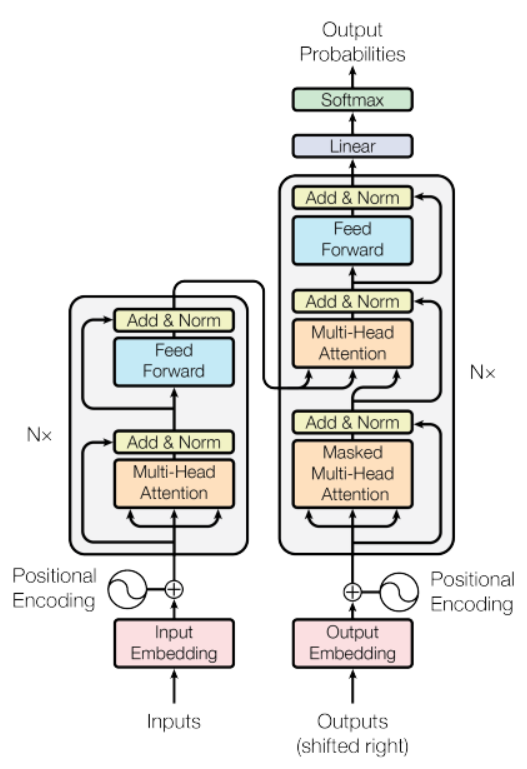
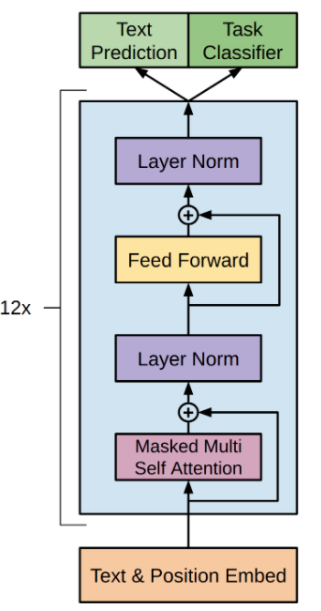
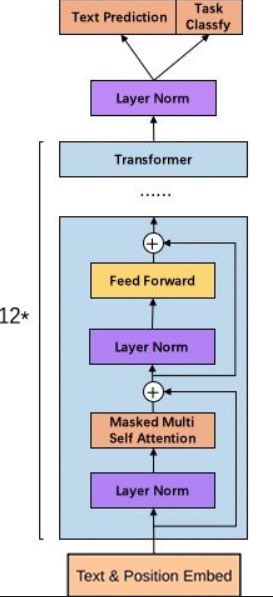
下图是transformer、gpt以及gpt2的简要结构图,可以从中简单看出其中不同的部分:
和transformer-decode(transformer右侧)r比,gpt和gpt2都少了一个multi-head attention模块。另外gpt2将layer norm提到了masked multi-attention和feed forward的前面;并且在最后一个transformer-decoder后接了一个layer norm。像gpt这种自回归模型,由于用到masked self-attention,它只能看到上文,不能看到下文(而没有masked的self-attention能看到上下文),且每次预测出的token加入原序列中继续预测下一个,符合文本生成。
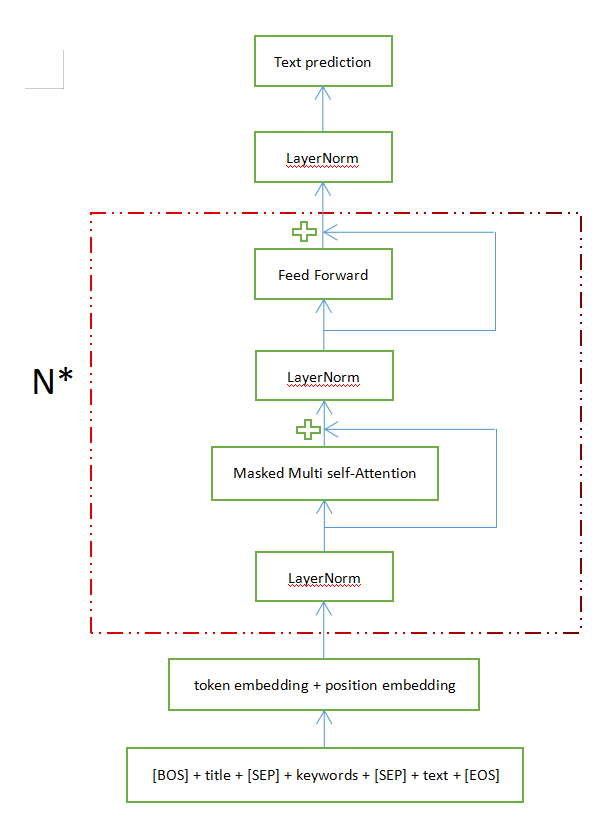
二.这里输入title和keywords到gpt2中进行相关文本生成,如下图:
model的输入是:[BOS] + title + [SEP] + keywords + [SEP] + text + [EOS]
三.程序见(https://github.com/jiangnanboy/text_generation)
def load_pretrained_mode(tokenizer, pretrained_model_path, special_token_path=None): ''' 加载 pretrained model :param tokenizer: :param pretrained_model_path: :param special_token_path: :return: ''' print("pretrained model loadding...") gpt2Config = GPT2Config.from_pretrained(pretrained_model_path, bos_token_id=tokenizer.bos_token, eos__token_id=tokenizer.eos_token, sep_token_id=tokenizer.sep_token, pad_token_id=tokenizer.pad_token, output_hidden_states=False) model = GPT2LMHeadModel.from_pretrained(pretrained_model_path, config=gpt2Config) if special_token_path: # 添加special token,model embedding size需要作调整 model.resize_token_embeddings(len(tokenizer)) # 冻结所有层 for param in model.parameters(): param.requires_grad = False # 1.只训练最后6个block ''' for i, m in enumerate(model.transformer.h): if (i + 1) > 6: for param in m.parameters(): param.requires_grad=True ''' # 2.或者只训练最后的一层 for param in model.lm_head.parameters(): param.requires_grad=True return model.to(DEVICE)