1. 分片和分段
1.1 分片
- 分片是 Es 处理的最小单元;
- 一个分片是一个 Lucene 索引;
- 一个包含倒排索引的文件目录;
- 分片越多搜索越慢。
a. 扩展和容灾
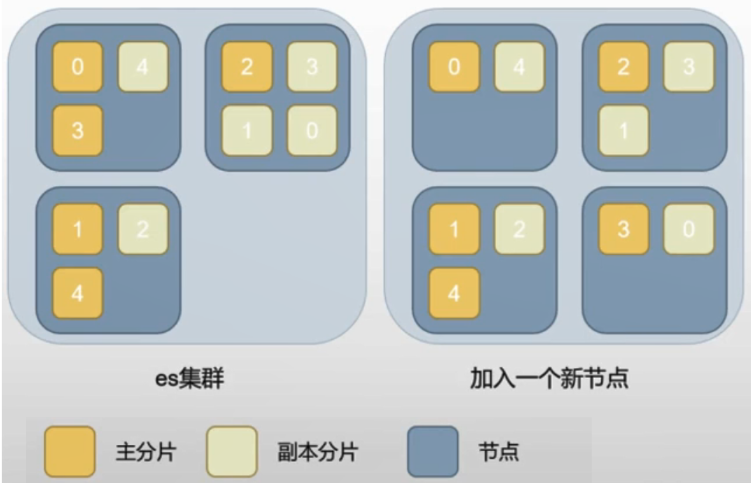
- 一个索引的所有分片会自动均匀分布在所有节点中;
- 加入新节点后,原集群节点的分片会部分迁移到新节点;
- 设置分片数量稍微大于节点数量,有利于横向扩容时,分片蔓延到所有新节点(每个节点都有分片时最理想的状态);
- 主分片和所有副本分片都就绪时,索引的健康状态是绿色的。

- 挂掉了 N 个节点时,如果副本分片是 N,那么剩下的副本分片将自动提升为主分片;
- 所有的主分片能构成完整的索引,但是副本分片缺失,所以此时索引健康状态是黄色;
- 如果挂掉 N+1 个节点,主分片将缺失,健康状态是红色;
- 根据实际情况设置副本数量(副本太多会影响性能);
- 通常同时挂掉两个节点的概率不高,一个副本可以满足常规容灾要求。
b. 索引和搜索数据
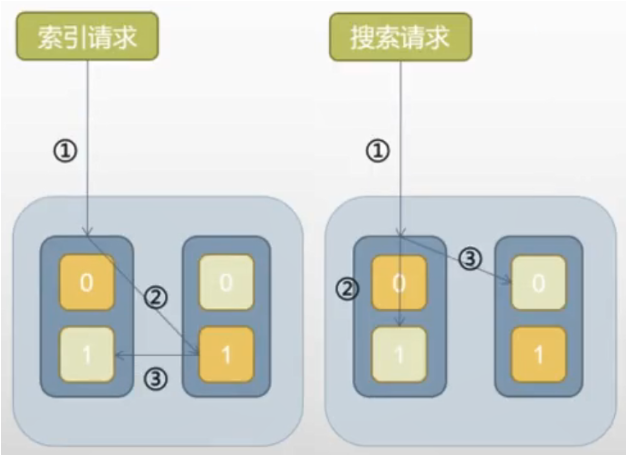
(1)索引请求:
- 索引文档请求到一个节点;
- 文档被随机到一个主分片;
- 从主分片同步到副本分片;
- 返回成功的结果。
副本分片越多,索引数据越慢,因为要所有副本都完成才算完成。
(2)搜索请求:
- 搜索请求到一个节点;
- 节点转发请求到本节点的一个分片(主副均可)和其他节点上的其他分片;
- 所有分片都返回搜索结果到发起节点;
- 发起节点返回搜索结果到请求方。
不同节点上的“主分片+副本分片”的总数越多,请求被分摊的越均匀,并发搜索性能越好(单个搜索无法通过增加分片副本的数量来加速)。但如果节点数很少,分片都集中到少数节点上,搜索速度会变慢,因为增加了开销,实际没有分摊负载。
c. 索引分片不是免费的吗?

【官方建议】JVM Heap 每 1G 不超过 20 个分片;每个分片大小在 20G~40G。
1.2 分段
- Lucene 索引再分割成小单元;
- 分段越多搜索越慢;
- 分段不会被修改;
- 索引新的文档会创建新的分段;
- 分段会持续地被合并;
- 删除文档时不会真的删除(标记删除)
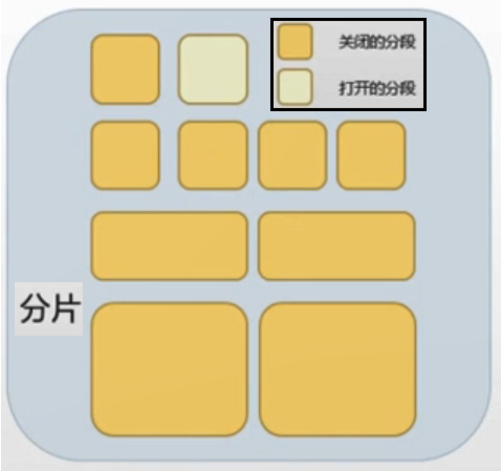
a. 分段写入
- 只能写打开的分段;
- 删除是假删除,也是往打开的分段写删除标记(→ 分段不会被修改);
- 分段大小超过一定阈值,会触发分段合并;
- 为了查询加速,小分段会合并成大分段;合并过程是先创建一个大分段,把两个小的重写进去,然后再删掉两个小分段,这个过程会耗费大量资源;
- 如果希望写入快,应该避免频繁分段合并。
b. 分段读取
- 只能读关闭的分段(所以叫“准实时”)
- 对一个分片查询,会等它所有的分段结果,所以分片过多 ...
- 刷新
- 刷新时,会关闭一批分段,这时数据才会被查到;
- 刷新频率太快会导致分段碎片多;
- 刷新频率太蛮会导致读写实时性低(只读关闭的);
c. 一切都是为了更快
- 弱化关系、弱化一致性,都是为了速度;
- 想读得快,就要牺牲写速度,反之亦然。
- 刷新间隔:index#settings#refresh_interval

2. 索引、更新、删除数据
2.1 索引文档
a. 字段类型

关于数据的存储:简单来说就是压扁了存~
(1)动态映射
PUT /company/_doc/1
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2019-01-01"
}
(2)查询映射
GET /company/_mapping
{
"company" : {
"mappings" : {
"properties" : {
"address" : {
"properties" : {
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"country" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"province" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"age" : {
"type" : "long"
},
"join_date" : {
"type" : "date"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
(3)docID=1 的底层存储格式
{
"name": [jack],
"age": [27],
"join_date": [2021-07-13],
"address.country": [china],
"address.province": [jiangsu],
"address.city": [nanjing]
}
(4)扩展:对象数组
{
"authors": [
{ "age": 26, "name": "Jack White"},
{ "age": 55, "name": "Tom Jones"},
{ "age": 39, "name": "Kitty Smith"}
]
}
·························· 存储格式 ··························
{
"authors.age": [26, 55, 39],
"authors.name": [jack, white, tom, jones, kitty, smith]
}
b. Mapping&Template
类似数据库的字段类型定义,你定义了一个字段,就要指定一个类型;如果不指定字段类型,Es 会在插入第一条数据时,自动创建一个 index,同时帮你创建 mapping 或者是索引了新字段,字段 mapping 也将会被动态设置。
字段如果和定义的类型不匹配,会插入失败。因此同一个字段不能有时候是字符串,有时候是数组。最好提前定义映射而不是依赖自动。
字段的 Mapping 配置中,处理指定类型,还可以为字段指定参数:① analyzer,指定分析器;② boost,指定字段的分值加成。
通过 模板(Template) 创建索引:除了每次创建 index 前,手动指定 index 的 mapping 和配置外,还可以自动从 Template 中获取 index 的 mapping 以及其他的设置(分片、副本数等),这是一个非常常用的操作。
- dynamic field mapping:Es 会根据 Json 字段自动判断类型,甚至能够发现 string 里面填的是日期、数值还是文本来设置字段类型;
- dynamic template:可以配置映射模板,自定义类型识别;
- index template:索引模板,通过索引名命中模板,模板中设置字段类型;
【注】
- 字段是否分析:不分析就不能全文检索这个字段,省性能;
- 字段是否索引:不索引就不能搜这个字段,省性能;
b. 分析字段
- 定义:解析、转变、分解文本,使得搜索变得更加相关;
- 步骤:
- 字符过滤(过滤器):使用字符过滤器转变字符(比如:大写变小写);
- 文本切分为分词(分词器):将文本切分为单个或者多个分词(比如:英文文本用空格切位一堆单词);
- 分词过滤(分词过滤器):转变每个分词(比如把 'a', 'an', 'of' 这类词干掉,或者复数单词转为单数单词);

2.2 更新文档
- 前面提过 segment 创建之后不能修改,因此文档更新实际上是创建了一条新的然后删掉旧的。但其实删除也不是真删,而是加上一条删除标记。
- 分段合并的时候会真删
- 删除会消耗性能
- 整个 index 删除是最快的
- 文档更新步骤:检索文档(按 id)→ 处理文档 → 重新索引文档
- 更新有 3 种方式:整条更新、字段合并、若存在则放弃更新
- 可以使用自动生成 id 来插入新文档,这样可以节省检索文档所耗费的资源(如果手动指定,Es 会先去检索该 id 的文档是否存在,如果存在,则会新增 → 更新),加快索引速度。
Es 显然是分布式的,那么就会有并发问题:再一个更新获取原文档进行修改期间,可能会有另一个更新也在修改这篇文档,那么第一个更新就丢了 → Es 通过「文档版本」实现并发控制(类似‘乐观锁’)
- 为每个文档设置一个版本号;
- 文档创建时版本号是 1;
- 当更新后,版本号++变成 2;
- 如果此时有另一个更新,版本号也将是 2,此更新结束时发现已经有一个 2,那么将产生冲突;
- 发生冲突后,重试这个更新操作,如果不再冲突,那么完成更新,版本号设置为 3;

- 可以更精确地控制冲突,默认情况下遇到冲突会更新失败,通过参数 retry_on_conflict 控制重试次数,默认为 0(不重试);
- 可以显式指定版本号(插入和更新都可以),而不是默认取最新版本;
- 可以使用外部版本号,比如时间戳;
2.3 删除文档
a. 删除文档
可以通过 id 删除单个,也可以通过条件批量删除,类似于 DELETE ... FROM ... WHERE ...;
删除文档会拖慢查询和进一步的索引:因为删除只是标记为删除,搜索的时候还要检查一遍命中的文档是否已经被删除;只有分段合并的时候才彻底删除。
不推荐使用。
b. 删除索引
- 删除索引是很快的,因为是直接移除索引相关的分片文件;
- 删除是不可恢复的,在生产环境上也没有权限控制,一定要小心操作(7.0+可控制权限);
- 小心!DELETE_ALL 会直接瞬间清空所有索引!
c. 关闭索引
- 除了删除,还有一个更安全的操作,就是关闭索引;
- 索引关闭之后,不能读取和写入,直到再次打开;
- 关闭后的索引只占磁盘,非常 cheap,因此我们通常会关闭而不是删除索引;
[POST] /my_index/_close
[POST] /my_index/_open
d. 冻结索引
- 扩展包功能
- 介于打开和关闭之间:不能写入;分片开销很小;
[POST] /my_index/_freeze [POST] /my_index/_unfreeze - 腾讯云版 Es 做了限制,需要特殊参数才能搜;
[GET] /my_index/_search?ignore_throttled=false
2.4 reindex
- 复制一个索引
- 可用于重建索引
- 可用于提取字段
- 可以跨集群复制
- 改变索引配置
- 分段一旦生成就不能修改,因此索引一旦创建就无法改变;
- 有些索引的配置也是不可改变的,比如分片数量、Mapping 映射等;
- 只能通过重建索引修改
- 提取字段
- 有时字段休要通过脚本处理后才能满足新的使用需求;
- 比如只存了航班 AA571,没有单独存航司,需要按航司聚类;
- 可以用脚本字段聚类,但不建议使用;
- 可以通过
reindex,写脚本来索引新字段;
- 注意,reindex 操作不会复制索引的配置,所以需要体检设置或者配置 Template;
- reindex 之前最好先把目标配置的副本数减为 0,并关闭刷新,加快写入;
[POST] _reindex
{
"source": {
"index": "source_index"
},
"dest": {
"index": "dest_index"
}
}
2.5 ILM
ILM(Index Lifecycle Management)索引生命周期管理
- rollover 滚动存储:可让分片大小均匀在 30~40 G;
- shrink 缩减分片:写的时候分片多可加速;读的时候收缩分片,减小内存消耗;
- allocate 分片节点感知:冷热分离;远期日志放到冷节点;省钱+延长日志存放时间;
- forcemerge 压缩分段:加速查询,节省开销;
- freeze 把索引关闭:不占内存只占存储;进一步延长日志存放时间;
- delete 彻底删除:自动删除,当前是用云脚本,不方便统一管理;

3. 搜索数据
Es 的搜索上下文分为「查询上下文(query context)」和「过滤上下文(filter context)」。区别在于过滤器不计算相关性,只关心是否命中条件。计算相关性需要计算匹配度分值,耗费性能(匹配度分值都是实时计算,无法缓存),所以尽量使用过滤查询以减少性能消耗加快查询速度。
3.1 Full-Text-Queries
全文检索,被查询的字段需要被分析;查询条件也会被分析。
a. match
最基本的全文检索查询,支持单词查询、模糊匹配、短语查询、近义词查询。
b. match_phrase
类似 match,专门查询短语,可以指定短语的间隔 slop(默认是 0)。例如希望含有 "quick brown fox" 的文档也能够匹配对 "quick fox" 的查询。
slop 参数告诉 match_phrase 查询词条能够相隔多远时仍然将文档视为匹配。相隔多远的意思是,你需要移动一个词条多少次来让查询和文档匹配?
尽管在使用了 slop 的短语匹配中,所有的单词都需要出现,但是单词的出现顺序可以不同。如果 slop 的值足够大,那么单词的顺序可以是任意的。
再比如说,想查一个词出现多次的:
{
"query": {
"match_phrase": {
"products.product_name": {
"query": "blue blue blue",
"slop": 1000
}
}
}
}
c. match_phrase_prefix
类似短语查询,但最后一个单词是前缀查询,用于最后一个单词想不起来的情况。比如“is t”可以命中“this is a test”。
d. multi_match
把 match 查询用在多个字段上。
e. common_terms
给非普通单词更大的权重。比如“eat”是普通单词,“tree6x7”是特殊单词。
f. query_string
使用 Lucene 查询语法的查询,可以指定各种 AND|OR|NOT 查询条件,而且支持在一条语句里对多字段查询。
g. simple_query_string
傻瓜版的 query_string,可以兼容错误的语法,不会搞挂查询,适合当作搜索框直接暴露给用户。
3.2 Term-Level-Queries
精确匹配查询,查询条件不会被分析。通常用于结构化的数据。比如数字、日期、枚举、keyword(当然,对于被分析过的字段也可以用)。
a. Normalizer
【场景】在 Es 中处理字符串类型的数据时,如果我们想把整个字符串作为一个完整的 term 存储,我们通常会将其类型 type 设定为 keyword。但有时这种设定又会给我们带来麻烦,比如同一个数据再写入时由于没有做好清洗,导致大小写不一致,比如 apple、Apple 两个实际都是 apple,但当我们去搜索 apple 时却无法返回 Apple 的文档。要解决这个问题,就需要 Normalizer 出场了。
PUT test_normalizer
{
"mappings": {
"doc":{
"properties": {
"type":{
"type":"keyword"
}
}
}
}
}
PUT test_normalizer/doc/1
{
"type":"apple"
}
PUT test_normalizer/doc/2
{
"type":"Apple"
}
# 查询一
GET test_normalizer/_search
{
"query": {
"match":{
"type":"apple"
}
}
}
# 查询二
GET test_normalizer/_search
{
"query": {
"match":{
"type":"aPple"
}
}
}
大家执行后会发现 查询一返回了文档 1,而 查询二没有文档返回,原因如下图所示:
- Docs 写入 Es 时由于 type 是 keyword,分词结果为原始字符串;
- 查询 Query 时分词默认是采用和字段写时相同的配置,因此这里也是 keyword,因此分词结果也是原始字符;
- 两边的分词进行匹对,便得出了我们上面的结果。
Normalizer 是 keyword 的一个属性,可以对 keyword 生成的单一 Term 再做进一步的处理,比如 lowercase,即做小写变换。使用方法和自定义分词器有些类似,需要自定义,如下所示:
DELETE test_normalizer
# 自定义 normalizer
PUT test_normalizer
{
"settings": {
"analysis": {
"normalizer": {
"lowercase": {
"type": "custom",
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"doc": {
"properties": {
"type": {
"type": "keyword"
},
"type_normalizer": {
"type": "keyword",
"normalizer": "lowercase"
}
}
}
}
}
PUT test_normalizer/doc/1
{
"type": "apple",
"type_normalizer": "apple"
}
PUT test_normalizer/doc/2
{
"type": "Apple",
"type_normalizer": "Apple"
}
# 查询三
GET test_normalizer/_search
{
"query": {
"term":{
"type":"aPple"
}
}
}
# 查询四
GET test_normalizer/_search
{
"query": {
"term":{
"type_normalizer":"aPple"
}
}
}
上述是自定义了名为“lowercase”的 Normalizer,其中 filter 类似自定义分词器中的 filter ,但是可用的种类很少,详情大家可以查看官方文档。然后通过 Normalizer 属性设定到字段 type_normalizer 中,然后插入相同的 2 条文档。执行发现,查询 3 无结果返回,查询 4 返回 2 条文档。
- 文档写入时由于加入了 Normalizer,所有的 term 都会被做小写处理;
- 查询时搜索词同样采用有 Normalizer 的配置,因此处理后的 term 也是小写的;
- 两边分词匹对,就得到了我们上面的结果。
b. term
精确匹配整个查询语句。
c. terms
类似 terms,可以传入一个数组,匹配到其中一个即可。
d. terms_set
类似 terms,可以指定匹配条件数。支持脚本通过计算指定。
e. range
范围查询;可以按区间查日期、数字,甚至字符串。
f. exists
非空查询;
g. prefix
前缀匹配。
h. wildcard
通配符查询,支持单个 ? 和多个 *,通配符放在越前面,查询效率越低。
i. regexp
正则表达式查询;使用不当会造成效率低下的查询。不要出现过度通配。
查询结果不被缓存。
j. fuzzy
模糊查询,比如 ab 可以命中 ba。
k. type
类型查询,指定被查询字段的 mapping。
l. ids
id 查询,可指定多个 id。
3.3 Compound-Queries
a. constant_score
包裹住的查询,会使用 filter 上下文,不计算相关性得分(可以指定常量分值)。
b. bool
最常用的组合查询,AND / OR / NOT / filter 可嵌套。
c. dis_max
对多个子查询的得分取最高,如果有子查询得分相近,还有加成选项。
d. function_score
可以对子查询的得分进行复杂计算,比如最大、最小、平均、随机、各种复杂的数学运算。
e. boosting
可以对子查询进行加分 positive 或者减分 negative,区别在于 bool 查询里的 NOT,不是去掉,而是降低命中者的权重。
3.4 Other-Queries
- Join-Queries:类似关系型数据库那样的关联查询;
- Geo-Queries:地理信息查询;
- Specialized-Queries:特殊查询,比如脚本;
- Span-Queries:跨度查询,将分词之间的距离纳入查询;被查询的字段需要被分析