目录
第一周 卷积神经网络基础
垂直边缘检测器,通过卷积计算,可以把多维矩阵进行降维。如下图:

卷积运算提供了一个方便的方法来发现图像中的垂直边缘。例如下图:
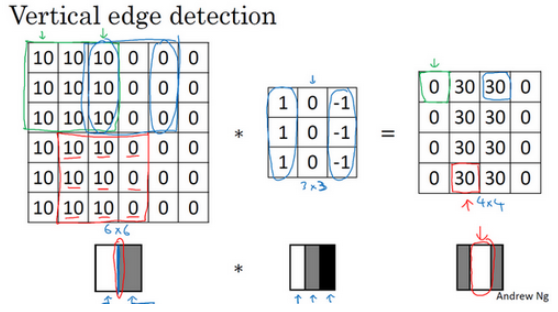
对于3x3的过滤器,使用下面的数字组合鲁棒性比较高,这样的过滤器也称为Sobel过滤器。

还有一种称为Scharr的过滤器,如下:

随着深度学习的发展,我们学习的其中一件事就是当你真正想去检测出复杂图像的边缘,你不一定要去使用那些研究者们所选择的这九个数字(3x3的过滤器),但你可以从中获益匪浅。把这矩阵中的9个数字当成9个参数,并且在之后你可以学习使用反向传播算法,其目标就是去理解这9个参数。
将矩阵的所有数字都设置为参数,通过数据反馈,让神经网络自动去学习它们,我们会发现神经网络可以学习一些低级的特征,例如这些边缘的特征。
padding卷积,为了指定卷积操作中的padding,你可以指定的值。也可以使用Valid卷积,也就是p = 0。也可使用Same卷积填充像素,使你的输出和输入大小相同。(same卷积填充的核心要点,是使得原给出的矩阵中像素点都能够均匀被调用计算,否则边缘点调用少,从而被忽略)
一个典型的卷积神经网络通常有三层,一个是卷积层,我们常常用Conv来标注。还有两种常见类型的层,一个是池化层,我们称之为POOL。最后一个是全连接层,用FC表示。如下图:

卷积网络中使用池化层,也能够缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。一下是一个池化层的例子, 把4×4的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。

最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
池化的超级参数包括过滤器大小f和步幅s,常用的参数值为f = 2,s = 2,应用频率非常高,其效果相当于高度和宽度缩减一半。
最大池化只是计算神经网络某一层的静态属性,它只是一个静态属性。
如何选定这些参数,常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序。
下面看一个卷积神经网络的例子,步骤一般为卷积->池化->卷积->池化... ... ->全连接,全连接等。如下图:

第二周 深度卷积网络:实例探究
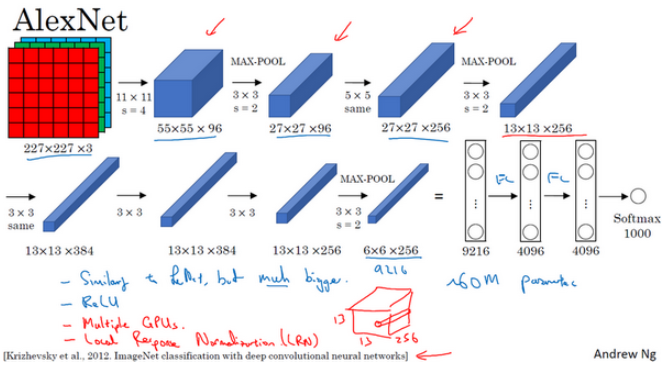
当用于训练图像和数据集时,AlexNet能够处理非常相似的基本构造模块,这些模块往往包含着大量的隐藏单元或数据,这一点AlexNet表现出色。AlexNet比LeNet表现更为出色的另一个原因是它使用了ReLu激活函数。如下图:
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。 跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。我们可以利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层。
如图所示,5个残差块连接在一起构成一个残差网络。
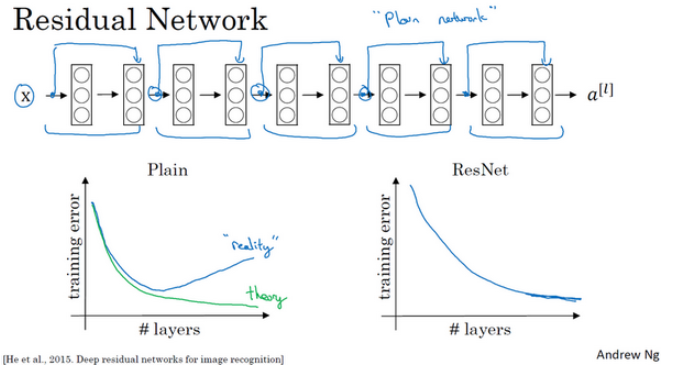
一般情况,随着网络深度加深,训练错误会越来越多。但是ResNets不一样, 即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。这种方法,可以有助于 解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。也许从另外一个角度来看,随着网络越来深,网络连接会变得臃肿,但是ResNet确实在训练深度网络方面非常有效。
普通网络和ResNets网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。直到最后,有一个通过softmax进行预测的全连接层。
1×1卷积层 给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。后面你会发现这对构建Inception网络很有帮助。如下图:

如果你看到一篇研究论文想应用它的成果,你应该考虑做一件事,我经常做的就是在网络上寻找一个开源的实现。因为你如果能得到作者的实现,通常要比你从头开始实现要快得多,虽然从零开始实现肯定可以是一个很好的锻炼。
在自己遇到的问题,训练的数据集内容比较少时,可以从网上下载一些以已训练且数据集比较大的模型,然后修改其最后的softmax输出值,然后再在此模型上进行训练学习,这就是卷积网络训练中的迁移学习,一般能够达到很好的效果。
常用的实现数据扩充的方法是使用一个线程或者是多线程,这些可以用来加载数据,实现变形失真,然后传给其他的线程或者其他进程。
当你没有太多标签数据时,你只需要更多地考虑手工工程。 另一套技术,当你有相对较少的数据时就可以用很多相似的数据。
第三周 目标检测
目标定位

滑动窗口目标检测,通过不断改变初始窗口的大小,以一定的步幅移动该窗口,对意向目标进行检测。具体如下图:

滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
YOLO对象检测算法是最有效的对象检测算法之一,包含了整个计算机视觉对象检测领域文献中很多最精妙的思路。
第四周 特殊应用:人脸识别和神经风格转换
人脸识别,需要解决一次学习的问题。 要让人脸识别能够做到一次学习,为了能有更好的效果,要做的应该是学习Similarity函数。 解决一次学习问题的,只要你能学习函数d,通过输入一对图片,它将会告诉你这两张图片是否是同一个人。如果之后有新人加入了你的团队(编号5),你只需将他的照片加入你的数据库,系统依然能照常工作。
函数的作用就是输入两张人脸,然后告诉你它们的相似度。实现这个功能的一个方式就是用Siamese网络,如下图:
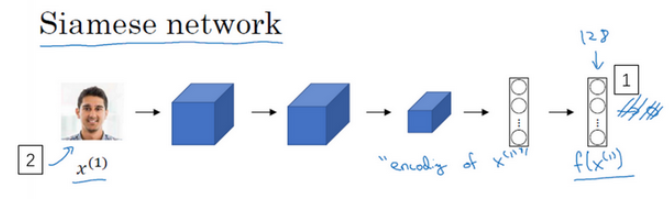
对于两个不同的输入,运行相同的卷积神经网络,然后比较它们,这一般叫做Siamese网络架构。
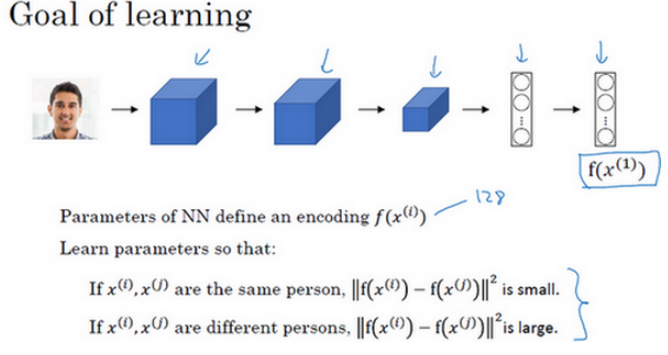
要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。学习收集定义好的三元组数据集, 用梯度下降最小化我们之前定义的代价函数,这样做的效果就是反向传播到网络中的所有参数来学习到一种编码,使得如果两个图片是同一个人,那么它们的d就会很小,如果两个图片不是同一个人,它们的d就会很大。如下图:

人脸识别的另一种方法是可以把识别过程当成一个二分类问题。对比两种图片的差异,输出相似度,如下图:

什么是神经风格迁移?
例如,可以把一张图片的元素整合到另一张图片中,如下图:

参考资料: