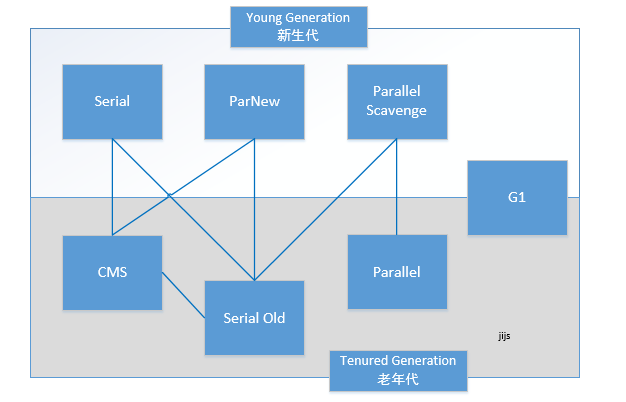
一、HotSpot虚拟机中的垃圾收集器:
|--Serial
|--Serial Old
|--PerNew
|--Parallel Scavenge
|--Parallel Old
|--CMS
|--G1
1. Serial和SerialOld收集器
• 单线程收集器,在进行GC时必须暂停其他所有线程,直到GC结束。
• 优势:简单而高效,Serial收集器虚拟机运行在client模式下的么人新生代收集器。
• 在单核cup环境中,由于没有线程交互的开销,效率更高。
• 新生代采用复制算法,老年代采用标记整理算法
2. PerNew收集器
• 是Serial的多线程版本。
• 采取复制算法实现
• 除了通过多个线程去执行GC之外,和Serial收集器完全一样。
• 是许多Server模式下的虚拟机的首选新生代收集器,因为只有它能够与CMS收集器配合工作。
• 默认开启的线程数和cpu的数量相同,在cpu数量非常多的情况下,可以通过参数-XX:ParallelGCThreads参数来控制线程数
3. ParallelScavenge收集器
• 使用复制算法的并行多线程收集器。
• 与CMS等收集器关注的垃圾收集时用户线程的停顿时间不同,ParallelScavenge收集器关注的是可控制的吞吐量:吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
• 通过参数-XX:MaxGCPauseMillis控制最大垃圾收集停顿时间,参数-XX:GCTimeRatio用于直接设置吞吐量,需要注意的是,GC停顿时间的减少是需要付出代价的,会直接导致垃圾收集变得更加频繁
• ParallelScavenge的GC自适应调节策略:通过开关参数-XX:+UseAdaptiveSizePolicy控制,这时不需要指定新生代大小、Eden和Survivor区域比例、老年代对象大小等参数,虚拟机会根据当前系统的运行情况收集性能监控数据,动态调整这些信息。
4. ParallelOld收集器
• 是ParallelScavenge的老年代版本,使用多线程的标记整理算法实现。
• 如果新生代使用了ParallelScaven收集器,老年代必须使用ParallelOld收集器进行配合。
5. CMS收集器(Concurrent Mark Sweep)
• 基于标记-清除算法实现的,以获得最短回收停顿时间为目标的收集器。
• 运作过程:初始标记-->并发标记-->重新标记-->并发清除。
• 其中初始标记、重新标记需要stop the world,初始标记只标记与GCRoots直接关联的对象;并发标记时程序继续执行,GC进行查找引用链操作;重新标记则是为了修正程序继续执行期间产生变动的对象,用时<并发标记,但>初始标记
• CMS的问题:
a. CMS对CPU资源非常敏感,在超过4个cpu时,垃圾收集线程占用25%以上的cpu资源,随着cpu数量的增加这一数值会降低;但在4个以下时,可能导致在GC时程序的执行效率骤降
b. 由于CMS不可避免的存在浮动垃圾,不能再老年代空间已满的情况下再进行GC。而如果由于浮动垃圾而导致Concurrent Mode Failure失败而导致另一次Full GC的产生。
c. 标记-清除算法会产生内存碎片,当大对象分配内存不足时,会触发Full GC
• CMS参数-XX:CMSInitiatingOccupancyFraction用来设置再老年代空间占用到多少时触发CMS收集器,默认92%;参数-XX:+UserCMSCompacgAFullCollection(默认开启)用于在CMS收集器顶不住需要Full GC时,开启内存碎片的整理过程,此过程无法并发执行;参数-XX:CMSFullGCsBeforeCompaction用于设置执行多少次不压缩的Full GC后跟着执行一次带压缩的Full GC(默认是0,表示每次进入Full GC时都进行碎片整理)
• CMS收集器执行过程:

6. G1收集器
• G1的特点:
a. 并行并发:G1能够充分利用多CPU、多核环境的特点,使用多个CPU缩短StopTheWorld的时间。
b. 基于整个GC堆的分代收集:和其他收集器不同,G1负责整个堆的垃圾回收;
c. 空间整合:从整个堆内存来看G1通过标记-整理算法实现;从局部看(两个Region之间)G1基于“复制”算法实现;
d. 停顿可预测:用户可以指定在长度为M的毫秒内,消耗在垃圾收集的时间不会超过N毫秒。
• 实现方式:
a. 将整个堆内存划分为大小相等的独立区域Region,新生代和老年代都是一个Region的一部分。
b. 可以有计划的在堆中进行整个Region的收集,每次在允许的时间内回收价值最大的Region。
c. 在G1中,Region之间的对象应用,(包括其他收集器中新生代和老年代之间的对象引用)都是通过RememberedSet来实现,避免全堆扫描;
d. RememberedSet的记录方式:JVM在发现都Reference类型的数据进行写操作时,会产生一个WriteBarrier暂停写操作,检查Reference对象是否处于不同的Region(或分代)之中,如果是,通过CardTable把相关信息记录到被引用的对象所属Region的RememberedSet之中。
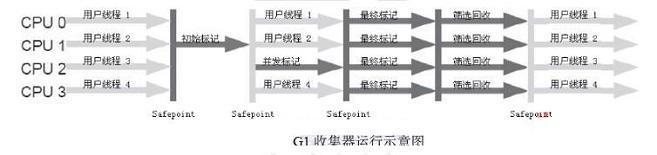
• G1收集器的运行过程:
a. 初始标记:同CMS
b. 并发标记:同CMS
c. 最终标记:同CMS
d. 筛选回收:先对各个Region的回收价值和成本进行排序,再根据用户期望的GC停顿时间来指定回收计划
• G1收集器执行过程图:
二、GC日志
GC日志:[GC [ParNew: 3324K -> 152K(3712K), 0.0025933 secs] 3324K -> 152K(11904K),0.0031680 secs]
1. 日志开头,“[GC”或“[Full GC”分别表示GC的停顿类型,FullGC表示发生了StopTheWorld,如果是调用了System.gc()方法触发的GC,日志将显示为:“[Full GC(System)”
2. 后边的“[ParNew”表示GC发生的区域,这一部分根据不同的收集器,内容会不同;
3. 后边方括号内的3324K -> 152K(3712K)表示:GC前该区域已使用容量->GC后该区域已使用容量(该区域总容量)
4. 括号外的3324K -> 152K(11904K)表示:GC前整个堆已使用容量->GC后整个堆已使用容量(堆内存总容量)
5. 0.0025933 secs表示该区域GC所占用的时间,有的回收器会给出更加具体的时间