一,由于该 jar 包不是免费的, maven 仓库一般不会有,需要我们去官网下载并安装到本地 maven 仓库
1,用地址 https://www-evget-com/product/564 下载 19.4 和 18.1 两个版本 (不知道为什么这个地址博客园不允许粘贴,请大家将域名的 - 换成 . 后在访问)
2,安装到本地 maven 仓库,不会安装的请移步 https://www.cnblogs.com/lovling/p/10122207.html
3,笔者安装的命令如下可做参考,这里两个 JAR 包放到 E 盘
mvn install:install-file -DgroupId=com.aspose -DartifactId=words -Dversion=19.4.jdk17 -Dpackaging=jar -D file=E:aspose-words-19.4-jdk17.jar
mvn install:install-file -DgroupId=com.aspose -DartifactId=words -Dversion=18.1.jdk16 -Dpackaging=jar -D file=E:aspose-words-18.1-jdk16.jar
二,创建一个 maven 项目,引入刚刚安装的依赖 common-asponse,这样命名是为了之后将该项目封装成公共工具库
<dependency> <groupId>com.aspose</groupId> <artifactId>words</artifactId> <version>19.4.jdk17</version> <!--<version>18.1.jdk16</vers-ion>--> </dependency>
1,在 resource 目录下创建一个 export 目录,准备以下几个文件,一张图片,一个证书,分别用 wps 和 office 创建的 word 文档
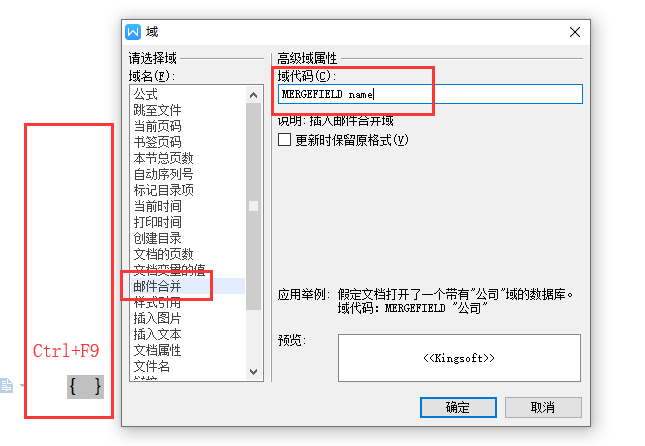
2,我们创建一个 域 邮件合并的模板,这是一个有实体类点属性的,两层 FOR 循环,带图片的模板

3,注意域的创建方式,Ctrl + F9 -> 右键点击生成的花括号 -> 选择编辑域 -> 选择邮件合并 -> 写内容
(注意如果用 wps 不要动 MERGEFIELD 这个单词,空一格在后面写, office 则没有 该单词)
三,模板准备完成后,开始写 JAVA 代码,
1,首先该框架 是不支持 Map 类型的数据的,所以我们需要自己去实现接口 IMailMergeDataSource 具体看注解
package com.hwq.aspose.word; import com.aspose.words.IMailMergeDataSource; import java.util.List; import java.util.ListIterator; import java.util.Map; public class MailMapData implements IMailMergeDataSource { private ListIterator<Map<String, Object>> list; private String name; private Map<String, Object> map; /** * 构造器初始化,将 list 集合转化为可迭代的对象,提高性能 * @param name 健 * @param list 值 */ public MailMapData(String name, List<Map<String, Object>> list) { this.name = name; this.list = list.listIterator(); } /** * 获取字段名的方法 * @return 自定义的字段名 */ @Override public String getTableName() throws Exception { return name; } /** * 移动到下一组数据,并判断下一组数据是否存在 * @return 是否存在下一个数据 */ @Override public boolean moveNext() throws Exception { map = list.hasNext() ? list.next() : null; return map != null; } /** * 获取当前字段的的数据,这里注意 18.1 和 19.4 的版本有一定的区别,下面注释的 19.4 版本的实现方式 * 在循环一个 Map 的时候,取字段时会运行改方法 * @param s 字段 * @param ref 数据容器 * @return * @throws Exception */ /* @Override public boolean getValue(String key, Ref<Object> ref) throws Exception { Object value = map.get(key); ref.set(value); return value != null; } */ @Override public boolean getValue(String key, Object[] args) throws Exception { Object value = map.get(key); args[0] = value; return value != null; } /** * 所谓数组的循环 * 在循环的时候,如果遇到内部还嵌套了循环,会执行该方法 * @param key 健 * @return 空或者另一个实现了邮件合并接口的子类 */ @Override public IMailMergeDataSource getChildDataSource(String key) throws Exception { Object object = map.get(key); return object instanceof List ? new MailMapData(key, (List) object) : null; } }
2,我们实现一个 邮件合并的数据 操作类,用于加载模板 和 把数据填入模板,以及保存文件,具体看注解
package com.hwq.aspose.word; import com.aspose.words.Document; import com.aspose.words.SaveFormat; import java.util.List; import java.util.Map; import java.util.Set; /** * 几个常用标签,一下都基于域的邮件合并模式 * 普通数据 «key» 或者 «key.kk» * 列表循环 «TableStart:key» ... «TableEnd:key» * 图片标签 «Image:key» */ public class WordData { private Document doc; /** * 构造器 * @param doc Word 文档操作类,操作模板的基础 */ public WordData(Document doc) { this.doc = doc; } /** * 插入普通数据,即邮件合并的 编辑域内容为 «key» 这种写法的数据(少用或者不用) * @param keys 健数组 * @param values 值数组 */ public void setData(String[] keys, Object[] values) { try { doc.getMailMerge().execute(keys, values); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex.getMessage()); } } /** * 插入实体数据,即邮件合并的 编辑域内容为 «key.kk» 这种写法的数据(常用) * @param key 健值 * @param map 单层树状的 Map 集合 */ public void setMap(String key, Map<String, Object> map) { Set<String> keySet = map.keySet(); String[] keys = new String[keySet.size()]; Object[] values = new Object[keySet.size()]; int index = 0; for (String kk : keySet) { keys[index] = key + "." + kk; values[index] = map.get(kk); index ++; } try { doc.getMailMerge().execute(keys, values); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex.getMessage()); } } /** * 插入列表数据,即邮件合并的 编辑域内容为 «TableStart:key» ... «TableEnd:key» 这种写法的数据(常用) * 理论上支持和 JSON 树状相同格式的无限树状 Map List 嵌套 * @param key 健 * @param list 数据列表 */ public void setList(String key, List<Map<String, Object>> list) { try { doc.getMailMerge().executeWithRegions(new MailMapData(key, list)); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex.getMessage()); } } /** * 保存文件到本地 * @param path 保存的地址 * @param suffix 保存的后缀名 和 格式 */ public void save(String path, SuffixEnum suffix) { try { doc.save(path + suffix.getSuffix(), suffix.getFormat()); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex.getMessage()); } } }
3,我们创建一个生成数据操作类的工具类
package com.hwq.aspose.word; import com.aspose.words.Document; import com.aspose.words.License; import org.springframework.core.io.ClassPathResource; import java.io.InputStream; public class WordUtil { private static WordUtil asposeUtil = null; private final String TEMP_PATH = "export/license.xml"; /** * 私有化构造器,并在类初始化的时候,执行加载证书的方法 * 如果没有证书,会有水印,测试阶段先注释 */ private WordUtil() { // loadLicense(); } /** * 单例模式对外暴漏的获取实体的方法 */ public static WordUtil get() { if (asposeUtil == null) { asposeUtil = new WordUtil(); } return asposeUtil; } /** * 加载签名证书的方法,购买正版的时候使用该方法加载 * 为了防止重复加载证书,该类设计为单例模式 */ private void loadLicense() { boolean result = false; ClassPathResource license = new ClassPathResource(TEMP_PATH); License aposeLic = new License(); try { aposeLic.setLicense(license.getInputStream()); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex.getMessage()); } } /** * 初始化 WORD 模板并获取邮件合并数据操作类 * @param templatePath 模板完整路径 */ public WordData initWordData(String templatePath) { try ( InputStream in = new ClassPathResource(templatePath).getInputStream(); ) { Document doc = new Document(in); return new WordData(doc); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex.getMessage()); } } }
4,我们创建一个枚举,用于确定文件最后生成的格式,该枚举不完整,后续可能补充
package com.hwq.aspose.word; import com.aspose.words.SaveFormat; /** * 该枚举主要定义生成的文件的后缀名的内容格式 * 后续根据需要自行添加,具体支持的格式查看 SaveFormat 类的源码 */ public enum SuffixEnum { DOCX(".docx", SaveFormat.DOCX), DOC(".doc", SaveFormat.DOC), PDF(".pdf", SaveFormat.PDF), PNG(".png", SaveFormat.PDF); public String suffix; public int format; SuffixEnum(String suffix, int saveFormat) { this.suffix = suffix; this.format = saveFormat; } public String getSuffix() { return suffix; } public int getFormat() { return format; } }
5,一切准备就绪,让我们写一个测试类来测试一下
package com.hwq.aspose.word; import org.springframework.core.io.ClassPathResource; import java.io.ByteArrayOutputStream; import java.io.InputStream; import java.util.*; public class Tester { public static void main(String[] args) throws Exception { // 模板的地址需要到后缀名为止 和 最后生成文件的保存地址,后缀名不需要加 String temp = "export/wps_word.docx"; String path = "E:/text/file/" + UUID.randomUUID().toString().replaceAll("-", ""); // 合并模板和数据 WordData word = WordUtil.get().initWordData(temp); word.setMap("user", getMap()); word.setList("data", getList()); // 保存新文件,该方法的第二个参数决定保存文件的类型和格式 word.save(path, SuffixEnum.DOCX); // word.save(file, SuffixEnum.PDF); } /** * 获取图片资源,这里测试就用一张图片,具体项目应该传入不同地址 * 这里只要返回二进制数组就行,具体的操作不固定,网络图片也是可行的 */ public static byte[] getImage() throws Exception { InputStream in = new ClassPathResource("export/head.png").getInputStream(); ByteArrayOutputStream swapStream = new ByteArrayOutputStream(); byte[] buff = new byte[100]; int rc = 0; while ((rc = in.read(buff, 0, 100)) > 0) { swapStream.write(buff, 0, rc); } return swapStream.toByteArray(); } /** * 获取单层树状结构数据 */ public static Map<String, Object> getMap() { Map<String, Object> map = new HashMap<String, Object>(); map.put("name", "Word"); map.put("sex", "男"); return map; } /** * 获取多层树状结构数据 (2层),理论上支持无限嵌套 */ public static List<Map<String, Object>> getList() throws Exception { List<Map<String, Object>> data = new ArrayList<Map<String, Object>>(); for (int j = 0; j < 2; j++) { Map<String, Object> dataMap = new HashMap<String, Object>(); List<Map<String, Object>> list = new ArrayList<Map<String, Object>>(); for (int i = 0; i < 3; i++) { Map<String, Object> map = new HashMap<String, Object>(); map.put("code", i + 1); map.put("name", "000" + i); map.put("date", "1992071" + i); // 图片需要的是二进制数组 map.put("head", getImage()); list.add(map); } dataMap.put("list", list); data.add(dataMap); } return data; } }
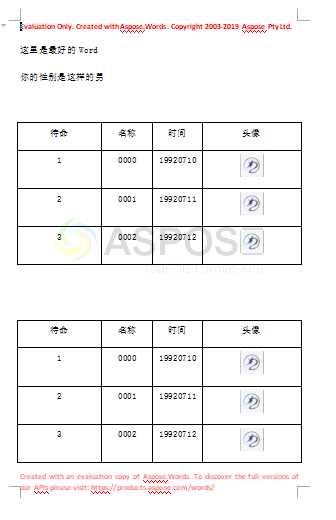
6,点击运行,得到结果,还算是比较顺利的
四,一些问题的解释
1,如果没有购买使用,测试生成的文件会带水印,并且有使用时间以及文件大小的局限性,如上图,就是测试的文件带着大大的水印,
如果条件允许,建议去官网进行购买,购买后我们可以获得一个 license.xml 的签名证书,在第三步的第3小步的类中把加载证书的代码
解开,就可以享受无水印无限制的结果了
当然,如果我么只是为了学习一下,使用破解版也是无可厚非的,不过不建议破解最新版,容易产生纠纷,笔者建议破解旧一点的版本,
这也是一开始为什么要下载两个版本的原因,至于破解的过程无非就是用 idea 打断点,找到签名的验证代码,反编译修改为跳过验证,
在打成 jar 包,网上教程很多,这里不再缀诉,下面笔者给出自己破译的版本供大家学习(请勿用于商业用途),点击前往
切换两个版本 需要注意修改一下 第三步的 第 1 小步创建类,这是由于两个版本的 getValue 方法有所不同,具体看上面的代码注释
破解后的我们可以随意编写一个 license.xml 内容如下,直接复制就可以使用
<License> <Data> <!-- 这里放产品名称 Aspose 的产品名称,可以多个 --> <Products> <Product>Aspose.Words for Java</Product> </Products> <!-- 这里填写产品类型,个人还是企业,一般写 Enterprise --> <EditionType>Enterprise</EditionType> <!-- 这里是 订阅到期期限,日期要大于当前 --> <SubscriptionExpiry>20991231</SubscriptionExpiry> <!-- 这里是 许可证到期期限,日期要大于当前 --> <LicenseExpiry>20991231</LicenseExpiry> <!-- 流水号,随便填一个,没有中文就行 --> <SerialNumber>8bfe198c-7f0c-4ef8-8ff0-ac</SerialNumber> </Data> <!-- 签名参数,随便填一个,没有中文那就行 --> <Signature>ZheLiSuiBianXieDianShaDouXing</Signature> </License>
2,我们会发现生成的文档,每一行文字都比较靠上,这个困扰了笔者很久,经过反复测试 发现用 WPS,编写的模板新生成的文件的
每一段文字只要不设置段后间距,生成的新文件就会莫名多出 10 榜 的段后间距,不知道是程序的原因还是 wps 本身的原因
解决办法,改用 office 编写的模板就一切正常了,推荐使用,毕竟 office 和 aspose 都是国外的软件和产品
如果非要用 wps 编写模板,那就只能给每一段文字设置段后间距为 1 榜,这样就不会,也可以试试比较新版的 WPS