【整理自http://zh.wikipedia.org/wiki/CPU%E7%BC%93%E5%AD%98(维基百科)】
在计算机系统中,CPU高速缓存(CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
基本描述
结构上,一个直接匹配(Direct Mapped)缓存由若干缓存段(Cache Block,或Cache Line)构成。每个缓存段存储具有连续内存地址的若干个存储单元。在32位计算机上这通常是一个字(word),即四个字节。因此,每个字具有一个唯一的段内偏移量。其图如下:

图1
图上是一个缓存段,存储单元为一个字,总共具有四个字(word0, word1, word2, word3)。
每个缓存段有一个索引(Index),它一般是一个内存地址的低端部分,但不含段内偏移和字节偏移所占的的最低若干位。一个数据总量4KB、每个缓存段16B的直接匹配缓存将共有256个缓存段,其索引为自0到255。使用一个简单的移位函数,就可以求得任意内存地址对应的缓存段。
关于数据总量的计算:The "size" of the cache is the amount of main memory data it can hold. This size can be calculated as the number of bytes stored in each data block times the number of blocks stored in the cache. (The number of tag and flag bits is irrelevant to this calculation, although it does affect the physical area of a cache).(因此,在缓存大小不变的情况下,缓存段大小和缓存段总数成反比关系。)
由于这是一个多对一的对应,必须在存储一段数据的同时标示出这些数据在内存中的确切位置。所以每个缓存段都配有一个标签(Tag)。拼接标签值和此缓存段的索引,即可求得缓存段的内存地址。如果再加上段内偏移,就能得出任意一个字的对应内存地址。
此外,每个缓存段还可对应若干标志位,包括有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等。这些位在保证正确性、排除冲突、优化性能等方面起着重要作用。
Data is transferred between memory and cache in blocks of fixed size, called cache lines. When a cache line is copied from memory into the cache, a cache entry is created. The cache entry will include the copied data as well as the requested memory location (now called a tag).
| tag | data block | flag bits |
The data block (cache line) contains the actual data fetched from the main memory. The tag contains (part of) the address of the actual data fetched from the main memory. (数据块(缓存行)包括从内存中取出的实际数据;标签包括实际数据的内存地址的一部分)
Flag bits
An instruction cache requires only one flag bit per cache row entry: a valid bit. The valid bit indicates whether or not a cache block has been loaded with valid data.(指令缓存的时候每一个缓存行只需要一个标志位:一位真实比特,这个位表明一个缓存块里面是否载入了真实的数据)
On power-up, the hardware sets all the valid bits in all the caches to "invalid". Some systems also set a valid bit to "invalid" at other times (电源启动的时候,硬件设置所有的真实位为“非真实”,一些系统也在其他时候设置一个真实位为非真实)
A data cache typically requires two flag bits per cache row entry: a valid bit and also a dirty bit. The dirty bit indicates whether that block has been unchanged since it was read from main memory -- "clean" -- or whether the processor has written data to that block (and the new value has not yet made it all the way to main memory) -- "dirty".(一个数据缓存行一般需要两个标志位:真实位和脏位。脏位表明缓存块中的数据是否遭到修改并且没有被写入内存)。
The "size" of the cache is the amount of main memory data it can hold. This size can be calculated as the number of bytes stored in each data block times the number of blocks stored in the cache. (The number of tag and flag bits is irrelevant to this calculation, although it does affect the physical area of a cache).(缓存的“大小”就是它所能容纳的内存数据大小,“大小”=每个缓存快所能缓存的数据大小 X 缓存块的数量(标签和标志位的大小与计算机无关,尽管它的确占据了一定的物理内存))
An effective memory address is split (MSB to LSB) into the tag, the index and the block offset.(一个有效的内存地址分成标签,索引和块偏移)
| tag | index | block offset |
The index describes which cache row (which cache line) that the data has been put in. The index length is  bits. The block offset specifies the desired data within the stored data block within the cache row. Typically the effective address is in bytes, so the block offset length is
bits. The block offset specifies the desired data within the stored data block within the cache row. Typically the effective address is in bytes, so the block offset length is 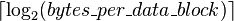 bits.(索引描述了数据被缓存在哪一个缓存行,块偏移说明了在缓存行的哪一块。一般来说有效地住是byte的倍数)
bits.(索引描述了数据被缓存在哪一个缓存行,块偏移说明了在缓存行的哪一块。一般来说有效地住是byte的倍数)
The tag contains the most significant bits of the address, which are checked against the current row (the row has been retrieved by index) to see if it is the one we need or another, irrelevant memory location that happened to have the same index bits as the one we want. The tag length in bits is 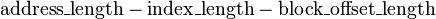 .(标签则包含了地址最最重要的部分,是用来检测当前行是否是我们需要找的行,或者只是恰好只是和我们要找的行具有相同的索引值的无关内存行)
.(标签则包含了地址最最重要的部分,是用来检测当前行是否是我们需要找的行,或者只是恰好只是和我们要找的行具有相同的索引值的无关内存行)
以上的结构可以保证内存和缓存中的数据同步!
相关
1)直接匹配
为了便于数据查找,一般规定内存数据只能置于缓存的特定区域。对于直接匹配缓存,每一个内存块地址都可通过模运算对应到一个唯一缓存块上。注意这是一个多对一匹配:多个内存块地址须共享一个缓存区域。
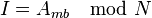
其中I为缓存索引,Amb为内存块地址,N为缓存块总数。
使用内存块地址而不是内存地址是因为缓存块通常包含一组连续的内存单元数据。以缓存块为32字节的直接匹配缓存为例,内存地址Am到缓存索引的计算为
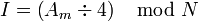
由于缓存字节数和缓存块数均为2的幂,上述运算可以由硬件通过移位极快地完成。
2)组相关
直接匹配缓存尽管在电路逻辑上十分简单,但是存在显著的冲突问题。由于多个不同的内存块仅共享一个缓存块,一旦发生缓存失效就必须将缓存块的当前内容清除出去。这种做法不但因为频繁的更换缓存内容造成了大量延迟,而且未能有效利用程序运行期所具有的时间局部性。
组相联(Set Associativity)是解决这一问题的主要办法。使用组相联的缓存把存储空间组织成多个组,每个组有若干数据块。通过建立内存数据和组索引的对应关系,一个内存块可以被载入到对应组内的任一数据块上。
以右图为例, 如使用2路组相联,内存地址为0、8、16、24的数据均可被置于缓存第0组中两个数据块的任意一个;如果使用4路组相联,内存地址为0、8、16、24的数据均可被置于缓存第0组中四个数据块的任意一个。一般地,

其中,I为缓存索引,Am为内存地址,Nw为缓存块内字数, Na为相联路数, N为组数。当使用组相联时,在通过索引定位到对应组之后,必须进一步地与所有缓存块的标签值进行匹配,以确定查找是否命中。这在一定程度上增加了电路复杂性,因此会导致查找速度有所降低。
此外,在不增大缓存大小的前提下单纯地增加组相联的路数,将不会改变缓存和内存的对应比例。再以右图为例,对于2路组相联,尽管第0组内有两个缓存块,但是该组现在也是内存块1、9、17、25的目标块。
直接匹配可以被认为是单路组相联。经验规则表明,在缓存小于128KB时,欲达到相同失效率,一个双路组相联缓存仅需相当于直接匹配缓存一半的存储空间。
3)全相关
组相联的一个极端是全相联。这种缓存意味着内存中的数据块可以被放置到缓存的任意区域。这种相联完全免去了索引的使用,而直接通过在整个缓存空间上匹配标签进行查找。 由于这样的查找造成的电路延迟最长,因此仅在特殊场合,如缓存极小时,才会使用。
置换策略
对于组相联缓存,当一个组的全部缓存块都被占满后,如果再次发生缓存失效,就必须选择一个缓存块来替换掉。存在多种策略决定哪个块被替换。
显然,最理想的替换块应当是距下一次被访问最晚的那个。这种理想策略无法真正实现,但它为设计其他策略提供了指针。
先进先出算法(FIFO)替换掉进入组内时间最长的缓存块。最久未使用算法(LRU)则跟踪各个缓存块的使用状况,并根据统计比较出哪个块已经最长时间未被访问。对于2路以上相联,这个算法的时间代价会非常高。
对最久未使用算法的一个近似是非最近使用(NMRU)。这个算法仅记录哪一个缓存块是最近被使用的。在替换时,会随机替换掉任何一个其他的块。故称非最近使用。相比于LRU,这种算法仅需硬件为每一个缓存块增加一个使用位(use bit)即可。
此外,也可使用纯粹的随机替换法。测试表明完全随机替换的性能近似于LRU
写操作
为了和下级存储(如内存)保持数据一致性,就必须把数据更新适时传播下去。这种传播通过回写来完成。一般有两种回写策略:写回(Write back)和写通(Write through)。
写回是指,仅当一个缓存块需要被替换回内存时,才将其内容写入内存。如果缓存命中,则总是不用更新内存。为了减少内存写操作,缓存块通常还设有一个脏位(Dirty bit),用以标识该块在被载入之后是否发生过更新。如果一个缓存块在被置换回内存之前从未被写入过,则可以免去回写操作。
写回的优点是节省了大量的写操作。这主要是因为,对一个数据块内不同单元的更新仅需一次写操作即可完成。这种内存带宽上的节省进一步降低了能耗,因此颇适用于嵌入式系统。
写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个缓存块大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
下面补充一点详细内容(来自《计算机组织与体系结构(性能设计)》)
1.主存储器由多达2^n个可寻址的字(注:一个字节是8个bits,普通的字长为8位,16位或者32位)组成,每个字有唯一的n位地址。为了实现映射,我们把这个存储器看成由许多定长的块组成,每个块由K个字组成,即有M=2^n/K个块。Cache由C个行组成,每行有K个字。行数远远小于主存储器块的数目。由于块数多于行数,因此每一行都有一个标记(tag)用来识别当前存储的是哪个块,这个标记通常是主存储器地址的一部分。
(注:到这里应该很清楚图1中的四个字是怎么来的了,根据上面的描述,实际上它们是主存中的一个块,所以缓存都是以块为单位进行调度的,这利用到空间局部性原理)
2.为了实现Cache存取,每个主存储器地址定义为三个域。最低的w位(block offset)标识主存储器中的某个块中唯一的字或者字节;在大多数当代的机器中,地址是字节级别的。剩余的s位指定了主存储器2^s个块中的一个,Cache则将这S位解释为s-r位(高位部分)的标记域(tag)以及r位的行域(index),后者标记了Cache m=2^r行中的一个
(注:根据以上描述,我们可以作如下理解,远门我们使用n来标志字的地址(根据1的描述)后来又将这些字分组,因而形成了2^s个组,而剩余的n-s位则作为block set来表示字在组中的偏移,由此形成一个地址。而s位块的地址对于Cache来说又不一样,分为标记域和行域,所以Cache和内存中地址的tag其实是一样的。)
3.采用部分地址作为行号提供了主存储器中的每一块到Cache的唯一映射。当一块读入带分配给它的行的时候有必要给它做标记,从而将它与其他能装入这一行的块区别开来,最高的s-r位用来做标记。
(注:映射的时候采用以下公式:i = j mod m,其中i=Cache的行号,j=主存储器的块号,m=Cache的行数。根据上面的要求,如果两个内存块被分配到同一个行,那么必须要求它们的tag是不一样的,否则无法识别。)
假设Cache系统用24位地址表示,14位行号用作索引,到Cache中去取一个特定的行,如果8位标记与当前该行中存储的标记相匹配,则用2位的号码来选择改行中四个字节之一。否则,用22位的标记和行号从主存储器中取出一个块,取块的实际地址是22位的标记和行号再加两位0,因此在块的边界起始读取四个字节。
所以总结一下,整个过程应该是这个样子的,处理器想要取某个地址里面的内容,首先,将这个地址分成三部分,取中间部分映射到某一行,映射完毕之后使用tag去匹配,如果成功,再使用剩余两位去取特定的字节,如果不匹配,就从内存中重新取出相应的数据并且按照规定放入行中。