1 pyhton 第一行被执行的代码在哪里??
python没有main函数,第一行被执行的代码,就是文件中的第一行代码
2 python有哪些常用的数据类型??
整型 浮点型 复数类型
字符串:
1 去掉某一种字符 strip/lstrip/rstrip
2 切分 split
3 查找子串 find
4 获得某一个子串出现的次数 count
5 将列表中的字符串拼接为一个 join
6 判断是否以某一子串开头或者结尾 startswith endswith
7 求字符个数 len
8 可以进行切片操作
被切片的对象[起始位置:结束位置:步长]
位置可以是正数,也可以是负数
正数的时候代表着从0开始的下标。负数的话,就倒着数的下标,注意:最后一个元素是-1.
列表:可以认为是存储任意类型数据的动态数组
li = []
增:append 末尾 insert 任意位置
删:pop 默认删除末尾,也可以根据下标进行删除 remove:根据元素删除
改:通过下标运算符更改------[]
查:index 查找元素所在的位置
其他操作:
排序: sort
倒序:reverse
元组:可以认为是存储任意类型数据的不可改变的数组
基本的操作只有查询相关的的操作:
index []
count:统计某一个数据出现的次数
元组不可以改变,说的是元组的元素不能再引用其他数据,但是如果元素的元素是一个列表,列表是可以改变的。
li= (1,2,[1,2,3],4,5)
li[2][1] = "hello world"
print(li)
字典:
键值对
什么可以作为键:整数 浮点 元组 字符串 列表不可以
什么可以作为值:任意数据都可以作为值
增:setdefault []
删:del
查:get
改:[]
3 python中的三大结构:
选择结构:if-else if-elif-elif....else
循环结构:
while 和C/C++是一致的
for in 通常用来遍历序列
4 python中的函数:
def 函数名(参数1名称,参数2名称.....):
#函数体 如果暂时没有想好怎么写,可以用pass占位
不需要返回值类型,也不需要参数类型 因为pyhton是弱类型,什么类型都可以传递,都可以返回。
python中形参和实参的关系:
形参是否能够改变实参????
类似于 整数 浮点 元组啊 等等 都不能改变
字典 列表 就可以改变
大家以指针的思想去理解这个问题,就会比较好理解。存储任何数据都是存储此数据的地址。
def my_fun1(a):
a = 20
def my_fun2(a):
a[1] = 10
m = 100
n= [1,2,3,4,5]
my_fun1(m)
my_fun2(n)
print(m,n)
深浅拷贝的问题:
m = 100
b = m
print(hex(id(m)))
print(hex(id(b)))
n= [1,2,3,4,5]
j = n.copy()
print(hex(id(n)))
print(hex(id(j)))

函数的作用域问题:
python中也有全局变量和局部变量:
定义在函数外的变量是全局变量,定义在函数内的变量是局部变量。
如果想在函数内使用全局变量的话,需要用global声明一下。
函数的参数问题:
1 python传参可以按位置传递,也可以按照关键字传(按照参数名传递)
3 python支持变参
位置变参
def calc_addition(*m):
print(m)
for i in m:
print(i)
calc_addition(1,2,3,"helloworld",[1,2,3],("nihao"))

关键字变参
def calc_addition(**m):
print(m)
for i in m:
print(i)
calc_addition(xiaoming = 1,xiaobai = 2,xiaohei = 3)

如果一个函数定义为如下形式,那么任意参数都可以往里面传递了。
def calc_addition(*args,**kwargs):
print(args)
print(kwargs)
calc_addition(1,2,3,4,5,6,"nihao",day = 1,month = 12)
模块管理:
一个python文件,就称之为一个模块。
如果你想要在自己的python文件中使用别的模块的函数,变量,那么就需要导入那个模块:
import 模块名
使用函数的时候,需要提供模块名
import mymath
print(mymath.add(1,2))
form 模块名 import 符号名
导入某一个符号
from mymath import add
print(add(1,2))
form 模块名 import *
导入所有的符号
from mymath import *
print(add(1,2))
print(sub(10,20))
导入模块的时候,会有三个事情:
1 执行目标模块文件中的所有脚本
2 构建一个命名空间,载入要导入的符号
3 将符号可命名空间联系在一起、
关于主模块的区分问题:
每一个模块,都有一个属性:
name
在作为主模块运行的时候,数据是"main"
作为导入模块运行的时候,数据是模块名
所以一般用它来区分,当前的python脚本是否作为主模块运行:
def add(a,b):
return a+b
def sub(a,b):
return a-b
if __name__ == "__main__":
print("我在测试")
包:就是一堆模块在一个文件夹中
import shiwupai.my_file as haha
from mymath import *
haha.fun()

python中的面向对象:
class StudentInfo(object):
count = 0 #这种属性是类属性
def __init__(self,id,name,age):
self.id = id #这种属性叫做实例属性
self.name = name
self.age = age
StudentInfo.count+=1
def print_all_info(self):
print(self.id,self.name,self.age)
stu1 = StudentInfo(1,"xiaoming",18)
stu2 = StudentInfo(2,"xiaohong",18)
stu1.print_all_info()
print(StudentInfo.count)
无论是类属性还是实例属性,都是可以动态添加的。
class StudentInfo(object):
count = 0
def __init__(self,id,name,age):
self.id = id #这种属性叫做实例属性
self.name = name
self.age = age
StudentInfo.count+=1
def print_all_info(self):
print(self.id,self.name,self.age)
self.abc = 125
stu1 = StudentInfo(1,"xiaoming",18)
stu1.address = "北京昌平"
print(stu1.address)
stu2 = StudentInfo(2,"xiaohong",18)
stu1.print_all_info()
print(StudentInfo.count)
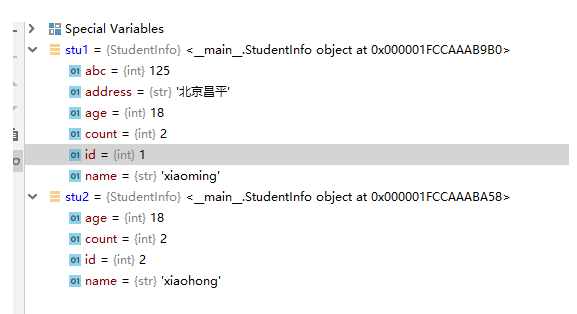
可以看出stu1的实例属性增多了。
class StudentInfo(object):
count = 0
def __init__(self,id,name,age):
self.id = id #这种属性叫做实例属性
self.name = name
self.age = age
StudentInfo.count+=1
def print_all_info(self):
print(self.id,self.name,self.age)
StudentInfo.abc = 100
print(StudentInfo.abc)
类属性,也是可以动态添加的。
函数:
1 普通方法
2 类方法
class StudentInfo(object):
count = 0
Teacherlist = ["万","高","...."]
def __init__(self,id,name,age):
self.id = id #这种属性叫做实例属性
self.name = name
self.age = age
StudentInfo.count+=1
def print_all_info(self):
print(self.id,self.name,self.age)
@classmethod
def PrintAllTeacher(cls):
for ele in cls.Teacherlist:
print(ele)
StudentInfo.PrintAllTeacher()
3 静态方法
class StudentInfo(object):
count = 0
Teacherlist = ["万","高","...."]
def __init__(self,id,name,age):
self.id = id #这种属性叫做实例属性
self.name = name
self.age = age
StudentInfo.count+=1
def print_all_info(self):
print(self.id,self.name,self.age)
@classmethod
def PrintAllTeacher(cls):
for ele in cls.Teacherlist:
print(ele)
@staticmethod
def Test():
print(StudentInfo.Teacherlist)
print("hello world")
StudentInfo.PrintAllTeacher()
StudentInfo.Test()
类方法和静态方法没有本质的不同,只是使用习惯上的区别:
1 类方法一般用于需要使用类属性的情况
2 静态方法一般用于不需要使用类属性的情况。
python中的权限控制要求:
以单下划线开头(_)表明成员是保护属性
以双下划线开头(__)表明成员是私有属性。
但是以上的限定仅仅类似于一个约定俗成的规矩,并没有语法上的强制限制。
双下划线开头()的成员是做了一个名称的变换:_类名成员名。
还是可以访问到的。
XXX:类似于这种的名称都是python内置的属性,我们定义成员名的时候,禁止使用这种形式。
常见的__开头结尾的属性:
print(StudentInfo.__name__)
print(StudentInfo.__doc__)
print(StudentInfo.__bases__)
print(StudentInfo.__dict__)#所有的类属性
print(StudentInfo.__module__)

单下划线(_)开头的全局变量,全局的函数,不能够被import XXX from* 导入。
python中的继承:
子类拥有父类的所有成员及方法。
class Human(object):
def __init__(self,name ,age):
self._name = name
self._age = age
def print_human_info(self):
print(self._name,self._age)
class StudentInfo(Human):
count = 0
Teacherlist = ["万","高","...."]
def __init__(self,id,name,age):
#从父类继承来的属性,用父类的构造
super(StudentInfo,self).__init__(name,age)
#自己扩展的属性再自己添加
self.__age = age
StudentInfo.count+=1
def print_all_info(self):
print(self.id,self.name,self.age)
m = StudentInfo(2,"xiaoming",18)
m.print_human_info() #子类对象能够直接使用父类的函数
python支持多继承
class Human(object):
def __init__(self,name ,age):
self._name = name
self._age = age
def print_human_info(self):
print(self._name,self._age)
class Wolf(object):
def __init__(self, speed):
self._speed = speed
def run(self):
print("da da da ")
class WolfMan(Human,Wolf):
def __init__(self, speed):
super(WolfMan,self).__init__("xiaoming",18)
self._speed = speed
m = WolfMan(200)
m.print_human_info() #子类对象能够直接使用父类的函数
m.run()
pyhton中解决二义性问题,就是广度优先遍历,先找到谁算谁。
python中的多态:
多态实现的是(接口复用)
python是一种天然的支持多态的语言。因为是弱类型的。
class Human(object):
def __init__(self,name="xiaoming" ,age=18):
self._name = name
self._age = age
def SingASong(self):
print("la la la")
class Wolf(object):
def __init__(self, speed=200):
self._speed = speed
def SingASong(self):
print("ao wu ao wu ")
def StartSing(obj):
obj.SingASong()
m = Human()
n = Wolf()
StartSing(m)
StartSing(n)
python中的异常处理
python中大多数错误在运行的时候都能够检测出来。
try:
li = [1, 2, 3, 4]
li[4] = "hello world"
except IndexError:
print("越界了")
自己将可能出现的异常并且需要自己处理的,就写在except后面。处理几个异常,就写几个except。
对于需要清理的资源,清理代码可以写在finally中。
try:
a = 10
#print(b)
except IndexError:
print("越界了")
except NameError as info:
print(info)
finally:
print("有没有出现异常,都会执行我这里")
我们自己可以主动抛出异常:
try:
a = 10
b = 0
if b == 0:
raise ZeroDivisionError("wei 0 le")
c =a/b
except IndexError:
print("越界了")
except NameError as info:
print(info)
except ZeroDivisionError as info:
print(info)
finally:
print("有没有出现异常,都会执行我这里")
python的一些特殊的语法:
filter 能够根据你提供的规则 去过滤一个列表
例如:提取列表中的偶数
li = [213,21,321,4,435,45,56,7,657,51,34,123,43,4,45]
li2 = []
for i in li:
if i%2==0:
li2.append(i)
print(li2)
更为高级的方法:
li = [213,21,321,4,435,45,56,7,657,51,34,123,43,4,45]
def fun(num):
if num%2==0:
return True
else:
return False
li2 = list(filter(fun,li))
print(li2)
li = [213,21,321,4,435,45,56,7,657,51,34,123,43,4,45]
li2 = list(filter(lambda x:not (x%2),li))
print(li2)
reduce 能够将序列中的元素按照某一种规则,迭代的去运算。
li = [1,2,3,4,5]
def Add(a,b):
return a+b
resault = reduce(Add,li)
print(resault)
resault = reduce(lambda a,b:a+b,list(range(0,100)))
print(resault)
map 能够将序列中的元素按照某一种规则映射出一份新的列表
li = [1,2,3,4,5]
def Shift(a):
return 2*a-1
li2 = list(map(Shift,li))
print(li2)
li = [1,2,3,4,5]
li2 = list(map(lambda a:a*2,li))
print(li2)
匿名函数: