1.视图
什么是视图
本质上是一个虚拟的表,即看得见但是不实际存在
为什么需要虚拟表?
使用场景
| 场景 | 作用 |
|---|---|
| 场景1 | 我们希望某些查询语句只能查看到某个表中的一部分记录 |
| 场景2 | 简化sql语句的编写 |
使用方法
# 语法:
# 创建视图
create [or replace] view view_name as 查询语句;
or replace:如果视图已经存在了,就替换里面的
# 修改视图
alter view view_name as 新的语句;
# 删除视图
drop view view_name;
# 查看表结构
desc view_name;
# 查看某个视图的语句
show create view view_name;
# 限制可以查看的记录
create table salarys(id int, name char(10), money float);
insert into salarys values(1, '张三丰', 500000),(2, '张无忌', 40000);
# 创建视图,限制只能查看张无忌的工资
create view zwj_view as select * from salarys where name='张无忌';
#准备数据
create table student(
s_id int(3),
name varchar(20),
math float,
chinese float
);
insert into student values(1,'tom',80,70),(2,'jack',80,80),(3,'rose',60,75);
create table stu_info(
s_id int(3),
class varchar(50),
addr varchar(100)
);
insert into stu_info values(1,'二班','安徽'),(2,'二班','湖南'),(3,'三班','黑龙江');
# 正常查看编号,名字,班级
select student.s_id, name, class from student join stu_info on student.s_id=stu_info.s_id;
# 创建视图包含编号,名字,班级,便于查询
create view stu_view as select student.s_id, name, class from student join stu_info on student.s_id=stu_info.s_id;
select * from stu_view;
# 注意,视图表中不能存在相同字段
修改原表,视图也会随之发生变化。修改视图,原表也会变化,但不要这样做,视图仅用来查询就可以了。
2.触发器
- 触发器是一段与某个表相关的sql语句,会在某个时间点,满足某个条件后自动触发执行
其中两个关键因素:
- 时间点
- 事件发生前,before | 事件发生后 after
- 事件
- update delete insert
在触发器中自动的包含两个对象:
- old: update delete 中可用
- new: update insert 中可用
用途:
- 当表的数据被修改时,自动记录一些数据,执行一些sql语句
# 语法
create trigger t_name t_time t_event on table_name for each row
begin
# sql语句...
end
案例:
# 准备数据
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, # 提交时间
success enum ('yes', 'no') # 0代表执行失败
);
# 错误日志表
CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
);
# 需求:插入cmd表时,如果执行状态失败,那么就将信息插入errlog表中
create trigger cmd_insert after insert on cmd for each row begin
if new.success='no' then
insert into errlog values(null, new.cmd, new.sub_time);
end if
end;
# 报错,错误原因遇到分号自动提交了,需要重新定义行结束符
# 将结束符设置为|
delimiter |
create trigger cmd_insert after insert on cmd for each row begin
if new.success='no' then
insert into errlog values(null, new.cmd, new.sub_time);
end if;
end |;
# 将结束符还原
delimiter ;
# 插入数据
insert into cmd values(null, 'root', 'lala', 'rm ', now(), 'no'); # 会自动插入到表errlog中
insert into cmd values(null, 'root', 'haha', 'ls ', now(), 'yes'); # 不会插入到表errlog中
# 注意:如果要使用,后面不要跟引号,类似于Python中的转义符
# 修改比较麻烦,可以删了重写
# 删除触发器
drop trigger cmd_insert;
# 查看触发器
show triggers;
# 查看某个触发器的语句
show create trigger cmd_insert;
注意:
当触发器所对应的的表被删除时,触发器自动删除
当触发器内包含其他表,如案例中的errlog被删除时,触发器启动时会报错
3.事务 *****
什么是事务:
- 事务就是一系列sql语句的组合,是一个整体
事务的特点(ACID):
- 原子性:指的是这个事务中的sql语句是一个整体,不能拆分,要么一起都执行成功,要么全都失败
- 一致性:事务执行结束后,表的关联关系一定是正确的(满足各种约束),完整性不会被破坏
- 隔离性:事务之间相互隔离,数据不会互相影响,即使操作了同一个表,本质就是加锁,根据锁的粒度不同,分为了几个隔离级别
- 持久性:事务执行成功后,数据将永久保存,无法恢复
事务的应用场景:
- 转账操作
- 把转出账户的钱扣掉
- 再给转入账户的余额做增加操作
注意:在官方提供的cmd的mysql客户端中,事务是默认就开启,会将每一条sql语句,自动提交
# 可以使用SET来改变MySQL的自动提交模式
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
手动使用事务示例:
# 语法
# 1.开启事务
start transaction;
#sql语句....
#sql语句...
rollback; # 回滚操作 即撤销没有提交之前的所有操作
#sql语句...
commit; # 提交事务 一旦提交就持久化了
create table account(
name char(10), money float);
insert into account values
('一只穿云箭', 1000), ('千军万马', 0);
start transaction;
update account set money=money-100 where name = '一只穿云箭';
update account set money=money+100 where name = '千军万马';
commit;
# 何时应该回滚:当一个事务执行过程中出现了异常时
# 何时提交:当事务中所有语句都执行成功时
# 保存点:可以在rollback指定回滚到某一个savepoint,也就是回滚一部分
update account set money=money-100 where name = '一支穿云箭';
savepoint a;
update account set money=money-100 where name = '一支穿云箭';
savepoint b;
update account set money=money-100 where name = '一支穿云箭';
savepoint c;
# 回滚至某个保存点
rollback to 保存点名称;
事务的隔离级别
数据库使用者可以控制数据库工作在哪个级别下,就可与防止不同的隔离性问题
-
read uncommitted(读未提交) ---- 最低的隔离级别,允许读取尚未提交的数据变更,可能会出现脏读,幻读,和不可重复读
-
read committed(读已提交) ---- 允许读取并发事务已经提交的数据,可以防止脏读,不能防止不可重复读,和幻读,
-
Repeatable read(可重复度) ---- 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以防止脏读,不可重复读,不能防止幻读(InnoDB默认的隔离级别)
-
Serializable(串行) ---- 高的隔离级别,完全服从ACID的隔离级别。数据库运行在串行化实现,所有问题都没有,就是性能低。
脏读:读到脏数据,也就是读取到了别人修改了但是还没有提交的数据
幻读:你在读取的时候别人在执行插入和删除,那么第二次查询时,就会多了一些原本不存在的记录,就像出现幻觉一样
不可重复读:在同一个事物中多次读取同一个数据,而别人正在做更新操作,这是你两次读取的数据不一致
幻读和不可重复读的区别在于,幻读是别人对表执行了插入和删除操作,也就是修改了表中记录的数量,而不可重复读是对你在读的那一条数据进行更新操作,是修改了记录的内容.
查看/修改隔离级别
# 查看当前隔离级别
SELECT @@tx_isolation;
# 修改全局的
set global transaction isolation level Repeatable read;
#或者:
set @@tx_isolation='repeatable-read'
# 修改局部
set session transaction isolation level read committed;
@@系统内置变量
@表示用户自定义的变量
注意
这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 REPEATABLE-READ(可重读)事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的SERIALIZABLE(可串行化)隔离级别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读)并不会有任何性能损失。
InnoDB 存储引擎在 分布式事务 的情况下一般会用到SERIALIZABLE(可串行化)隔离级别。
4.存储过程 ***
什么是存储过程?
- 是任意的sql语句的组合,被放到某一个存储过程中,类似于一个函数,有一个函数,参数,函数体
用来干什么?
- 其中可以包括任何的sql语句,逻辑处理,事务处理,所以的我们学过的sql语句都可以放到里面去
三种数据处理的方式
-
应用程序只关注业务逻辑,所有与数据相关的逻辑封装到mysql中
-
优点:应用程序要处理的事情变少了,可以减少网络传输次数
-
缺点:增加了人力成本,沟通成本,降低整体开发效率
-
-
应用程序既要处理业务逻辑,还要自己编写sql语句
-
优点:降低了人力,沟通的成本
-
缺点:网络传输增加,sql语句的编写非常繁琐,易出错
-
-
通过ORM框架(对象关系映射)自动生成sql语句并执行
- 优点:不需要编写sql语句,明显提升开发速度
- 缺点:灵活性差,应用程序开发者和数据库完全隔离,可能导致仅关注上层应用,而忽视了底层的原理,在出现一些问题时不能够进行良好的应变。
使用存储过程
# 语法
create procedure p_name(p_type p_name p_data_type)
begin
#sql语句...
end
# p_type表示参数的类型 in(输入) out(输出) inout(即可输出也可输入)
# p_name 参数的名字
# p_data_type 参数的数据类型 如 int float
案例:
# 案例
delimiter |
create procedure add1(in a float,in b float,out c float)
begin
set c = a + b;
end|
delimiter ;
# 调用
set @res = 0 # 定义变量
call add1(10, 20, @res);
select @res;
# 删除
drop procedure 名称;
# 查看
show create procedure 名称;
# 查看全部 day41库下的所有过程
select name from mysql.proc where db = 'day41' and type = 'PROCEDURE';
delimiter |
create procedure transfer(in aid int, in bid int, in m float, out res int)
begin
declare exit handler for sqlexception
begin
# 异常处理代码
set res = 99;
rollback;
end;
start transaction;
update account set money = money - m where id = aid;
update account set money = money + m where id = bid;
commit;
set res = 1;
end|
delimiter ;
5.函数
内置函数
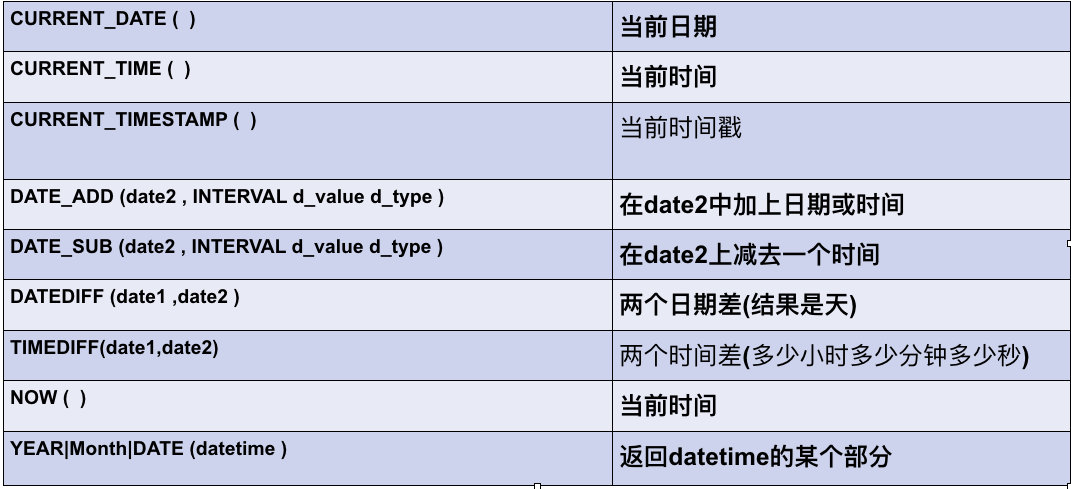
日期相关:
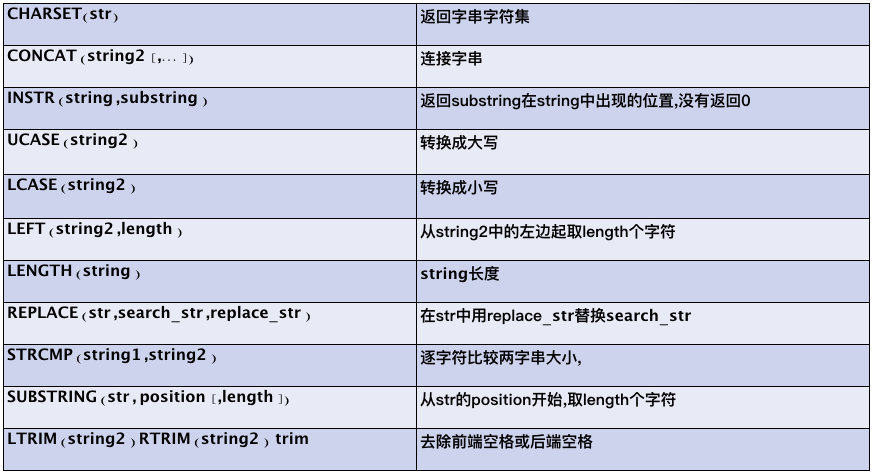
字符串相关:
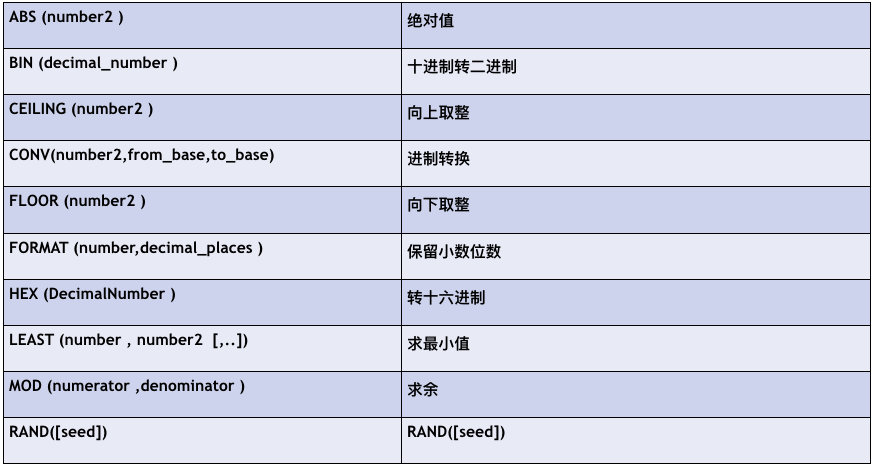
数字相关:
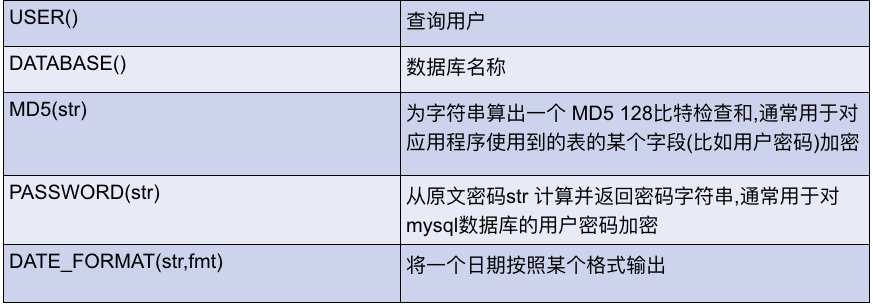
其他函数:
还有之前学的聚合函数
自定义函数
create function func_name(参数 类型)
函数体
returns 返回值的类型
return 返回值;
# 注意:函数体内不能是sql语句,只能是简单的运算
# 注意:必须有返回值,不能加begin和end
# 注意:returns后面不用加分号,return要加
delimiter |
create function add2(a int, b int)
returns int
return a + b|
delimiter ;
# 调用
select add2(1, 2);
# 查看创建语句
show create function f_name;
# 查看所有函数的状态
show function status;
# 查看某个库下所有函数
select name from mysql.proc where db = '库名称' and type = 'FUNCTION';
# 删除
drop function f_name;
6.备份与恢复
# 备份
mysqldump.exe
mysqldump -u用户名 -p密码 数据库 表1 表2 ... > 文件路径...
# 注意 第一个表示数据库 后面全是表名
# 示例:备份day41库中的student表
mysqldump -uroot -p123 day41 student > x1x.sql
# 备份多个数据库
mysqldump -uroot -p123 --databases day41 day40 > x2x.sql
# 指定 --databases 后导出的文件包含创建库的语句,而不指定的不包含。
# 备份所有数据
mysqldump -uroot -p123 --all-databases > alldata.sql
# 自动备份
linux 中 crontab 指令可以定时执行某一个指令
# 恢复数据
没有登录mysql
mysql < 文件路径
已经登陆mysql
source 文件路径;
# 会使用client配置文件,
# 注意:如果导出的sql中没有函数选择数据库的语句,未登录的恢复需要手动添加到备份文件中,登录后的恢复会自动恢复到当前库中。
7.流程控制
delimiter |
create procedure showjishu()
begin
declare i int default 0;
aloop: loop
set i = i + 1;
if i >= 101 then leave aloop; end if;
if i % 2 = 0 then iterate aloop; end if;
select i;
end loop aloop;
end|
delimiter ;
补充: 正则匹配
当模糊匹配不能满足需求时使用
# 语法:
select * from 表名 where 字段名 regexp '表达式';
# 基本和python元字符使用方式一致,但是不能使用类似w这样的符号,需要找其他符号来替代