author: lunar
date: Wed 28 Oct 2020 07:11:15 PM CST
location: Shanghai
内存管理
本章主要了解内核中的内存分配,一般操作系统书籍讲解的都是用户空间的内存分配。在内核中内存比较紧张,并且内核不能睡眠,处理内存分配错误也更加困难。
页
内核把物理页作为内存管理的基本单位。在32位系统上页的大小为4KB,64位系统页的大小为8KB。
页的数据结构
struct page {
unsigned long flags; //页状态,总共有32种
atomic_t _count; //页的引用次数
atmoic_t _mapcount;
unsigned long private;
struct address_space* mapping;
pgoff_t index;
struct list_head lru;
void* virtual; //页的虚拟地址。有些内存并不永久地映射到内核地址空间,此时virtual为null
};
区
内核并不是对于所有的页一视同仁,有些页位于内存中特定的物理地址上,用于执行一些特定的任务。因此,内核把页划分为不同的区(zone)。
linux必须处理由于硬件缺陷而引起的两类内存寻址问题:
- 一些硬件只能用某些特定的内存地址来执行DMA(Direct Memory Access)
- 一些体系结构内存的物理地址范围大于虚拟地址的寻址范围,导致一些物理内存永远无法使用。
因此,内核使用四种区:
- ZONE_DMA:该区的页可以执行DMA操作
- ZONE_DMA32:这些页与上一个类似,但是只能被32位设备访问
- ZONE_NORMAL:包含正常映射的页
- ZONE_HIGHEM:包含“高端内存”,其中的页永远不能映射到内核地址空间

32位x86的体系结构下,各个区的内存范围如图所示。32位系统支持的最大内存为4GB,其中内核地址空间占1GB。
获得页
提前声明,所有的这些内存分配,如果分配失败会返回NULL指针。在使用之前,务必检查是否分配成功。
内核提供了一种请求内存的底层机制,并提供了对它进行访问的几个接口,所有这些接口都以页为单位分配内存。最核心的函数为
struct page* alloc_pages(gfp_t gfp_mask, unsigned int order);
该函数分配 (2^{order}) 个连续的物理页,并返回一个指向第一页的page结构体的指针。
可以用下面这个函数将页转换为它的逻辑地址:
void* page_address(struct page* page);
还有一个包含上述两个步骤的函数
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
还有下面两个只分配一页的函数
struct page* alloc_page(gfp_t gfp_mask);
unsigned long __get_free_page(gfp_t gfp_mask);
注意函数名单复数的区别。

释放页
当不需要页时,可以通过以下函数释放:
void __free_pages(struct page* page, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);
void free_page(unsigned long addr);
kmalloc()
编写过内核程序的同学应该都对这个函数不陌生,kmalloc()就相当于用户空间的 malloc() 。但是是专门用于在内核空间分配内存。
同时,kmalloc() 还可以传入不同的 flag 用于不同情况的内存分配。
函数原型为
void* kmalloc(size_t size, gfp_t flags);
gfp_mask 标志
从前面的知识看来,不管是在低级页分配函数还是在kmalloc() 中,都要用到分配器标志,现在来了解一下这些标志。
这些标志可分为三类:行为修饰符、区修饰符和类型。
行为修饰符表示内核分配内存的方式,比如中断程序就要求内核分配内存时不能睡眠。区修饰符表示内核应该在上面提到的几个区中的哪个区分配内存。类型标志则组合了行为修饰符和区修饰符,一个类型标志既规定了分配内存的方式,又规定了从哪个区分配内存。
1. 行为修饰符
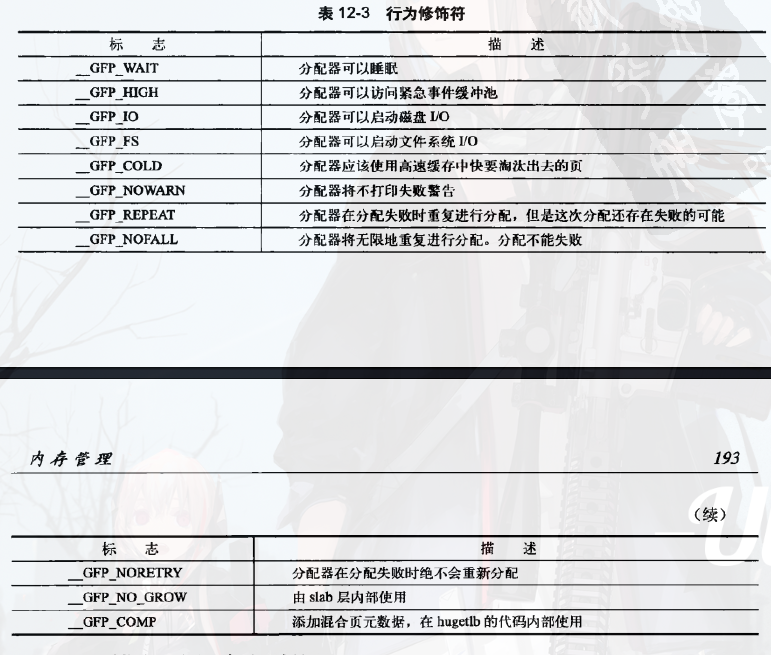
老规矩,可以通过|来同时制定多个标志,因为这些标志所对应的二进制都只在某一位上为1,最终结果的某一位为1就表明相应的标志被给出。
2. 区修饰符

尽量使用ZONE_NORMAL区的内存。不能给返回逻辑地址的函数制定从ZONE_HIGHMEM分配内存,因为这个区的内存可能还没有映射到内核的地址空间,根本没有逻辑地址。
3. 类型标志

最常用的标志是 GFP_KERNEL,对内核如何获取内存完全没有约束,分配成功可能性最高。
另一个相反的标志是 GFP_ATOMIC,因为它要求内核不能睡眠,导致在没有一块连续的内存可用时,内核不能让调用者睡眠、交换、刷新一些页到磁盘来获取内存,所以分配成功可能性低。
另外一些标志了解一下就行了,在编写的绝大多数代码中,要么是 GFP_KERNEL,要么是 GFP_ATOMIC。
kfree()
释放 kmalloc() 分配的内存块
void kfree(const void* ptr);
vmalloc()
vmalloc() 同样用于在内核中分配内存,但是其与kmalloc()的区别在于前者分配的内存在物理内存上不必连续,而kmalloc()在物理内存上也是连续的。
所以其实vmalloc() 与 malloc() 更加相似。
虽然 vmalloc() 看起来更好用,但是会带来性能损失,通过 vmalloc() 获得的页必须一个个地进行映射,导致比直接内存映射大得多的TLB抖动。所以,vmalloc() 一般在获取大块内存时使用。
void* vmalloc(unsigned long size);
void vfree(const void* addr);
slab 层
数据结构的分配和回收是很多内存都要面临的一个操作,通常会通过一个链表来管理要分配的数据结构。当分配新的数据结构时,就从链表中取出一个直接放入新数据,而不用进行任何内存操作。
但是,有时在内存吃紧时,会希望释放一部分这些链表中的数据结构来增加内存。但是缺少一个全局控制这些链表的方式。
于是,Linux内核提供了 slab层(slab分配器)。
slab 层的设计
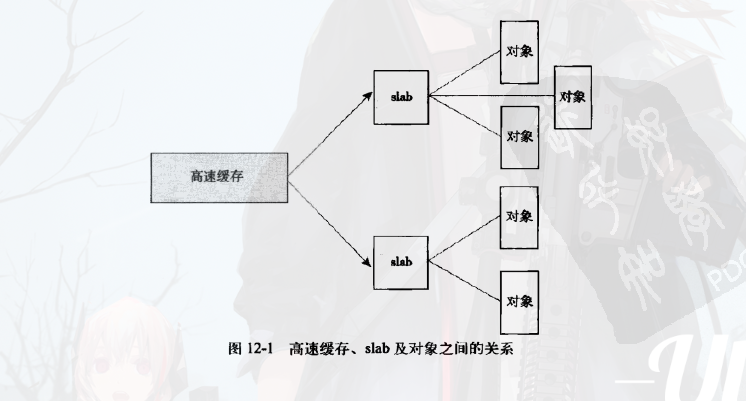
slab层把不同的对象划分为所谓的高速缓存组,其中每个高速缓存都存放不同类型的对象。每种对象类型对应一个高速缓存。
然后,这些高速缓存又被划分为slab。slab由一个或多个物理上连续的页组成,一般情况下,slab也就仅仅由一页组成。
每个slab都包含一些对象成员,这里的对象指的就是被缓存的数据结构。每个slab处于三种状态之一:满、空、半满。
每个高速缓存都使用kmem_cache结构体来表示,这个结构包含了三个链表:slabs_full、slabs_partial、slabs_empty,均存放在 kmem_list3 结构内。
kmem_cache 的结构体为:
/* slab分配器中的SLAB高速缓存 */
struct kmem_cache {
/* 指向包含空闲对象的本地高速缓存,每个CPU有一个该结构,当有对象释放时,优先放入本地CPU高速缓存中 */
struct array_cache __percpu *cpu_cache;
/* 1) Cache tunables. Protected by slab_mutex */
/* 要转移进本地高速缓存或从本地高速缓存中转移出去的对象的数量 */
unsigned int batchcount;
/* 本地高速缓存中空闲对象的最大数目 */
unsigned int limit;
/* 是否存在CPU共享高速缓存,CPU共享高速缓存指针保存在kmem_cache_node结构中 */
unsigned int shared;
/* 对象长度 + 填充字节 */
unsigned int size;
/* size的倒数,加快计算 */
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
/* 高速缓存永久属性的标识,如果SLAB描述符放在外部(不放在SLAB中),则CFLAGS_OFF_SLAB置1 */
unsigned int flags; /* constant flags */
/* 每个SLAB中对象的个数(在同一个高速缓存中slab中对象个数相同) */
unsigned int num; /* # of objs per slab */
/* 3) cache_grow/shrink */
/* 一个单独SLAB中包含的连续页框数目的对数 */
unsigned int gfporder;
/* 分配页框时传递给伙伴系统的一组标识 */
gfp_t allocflags;
/* SLAB使用的颜色个数 */
size_t colour;
/* SLAB中基本对齐偏移,当新SLAB着色时,偏移量的值需要乘上这个基本对齐偏移量,理解就是1个偏移量等于多少个B大小的值 */
unsigned int colour_off;
/* 空闲对象链表放在外部时使用,其指向的SLAB高速缓存来存储空闲对象链表 */
struct kmem_cache *freelist_cache;
/* 空闲对象链表的大小 */
unsigned int freelist_size;
/* 构造函数,一般用于初始化这个SLAB高速缓存中的对象 */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
/* 存放高速缓存名字 */
const char *name;
/* 高速缓存描述符双向链表指针 */
struct list_head list;
int refcount;
/* 高速缓存中对象的大小 */
int object_size;
int align;
/* 5) statistics */
/* 统计 */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/* 对象间的偏移 */
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEM
/* 用于分组资源限制 */
struct memcg_cache_params *memcg_params;
#endif
/* 结点链表,此高速缓存可能在不同NUMA的结点都有SLAB链表 */
struct kmem_cache_node *node[MAX_NUMNODES];
};
slab的结构体为:
struct slab {
struct list_head list; //满、部分或空链表
unsigned long colouroff; //着色偏移量
void* s_mem; //slab的第一个对象
unsigned int inuse; //slab中已分配的对象数
kmem_bufcti_t free; //第一个空闲对象
}
slab分配器还有很多复杂的具体细节,这里不展开细讲了。具体可以看这篇文章