
使用原理
mysql采用table和结构化的sql语句来处理数据,需要预先定义字段名,数据结构,并定义表中数据字段的关系
mongoDB采用类JSON的documents来存储数据,采用动态数据模型,类似于字典,不需要预先定义表的数据类型和字段名,也就是说可以轻松增加新的字段名或者删除旧的字 段 。
设计特征
基本概念
- 数据库
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为"db",该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
MongoDB 中存在以下系统数据库。● Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。● Local 数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。● Config 数据库:当MongoDB 使用分片模式时,config 数据库在内部使用,用于保存分片的信息。 - 文档
文档是 MongoDB 中数据的基本单位,类似于关系数据库中的行(但是比行复杂)。多个键及其关联的值有序地放在一起就构成了文档。
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点
例如:
{“greeting”:“hello,world”}这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。例如:{“greeting”:“hello,world”,“foo”: 3}文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。{“foo”: 3 ,“greeting”:“hello,world”}
需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有� (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
- 集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"} {"site":"www.google.com","name":"Google"} {"site":"www.runoob.com","name":"菜鸟教程","num":5}当第一个文档插入时,集合就会被创建。
合法的集合名
- 集合名不能是空字符串""。
- 集合名不能含有�字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
怎么用?
|
|
小于 |
|
|
|
大于 |
|
|
|
小于等于 |
|
|
|
大于等于 |
|
|
|
不等于 |
|
|
|
在范围内 |
|
|
|
不在范围内 |
|
|
|
匹配正则表达式 |
|
|
|
|
属性是否存在 |
|
|
|
|
类型判断 |
|
|
|
|
数字模操作 |
|
年龄模5余0 |
|
|
文本查询 |
|
|
|
|
高级条件查询 |
|
自身粉丝数等于关注数 |
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
数据库连接
import pymongo # 连接 mongodb://admin:123456@localhost:27017/test myclient = pymongo.MongoClient("mongodb://localhost:27017/") # 指定数据库 mydb = myclient["runoobdb"] # 不存在则创建 # 判断数据库是否存在 print("runoobdb" in myclient.list_database_names()) # 指定集合 mycol = mydb["sites"] # 不存在则创建,但是只有在内容插入后才会被真正创建 # 判断集合是否存在 print("sites" in mydb.list_collection_names())
添加数据
# 插如一条记录 x1 = mycol.insert_one({ "name": "Google", "alexa": "1", "url": "https://www.google.com" }) # 打印这条数据的 id print(x1.inserted_id) # 插入多条记录,并指定id mylist = [ { "_id": 1, "name": "RUNOOB", "address": "菜鸟"}, { "_id": 2, "name": "Google", "address": "Google 搜索"}, { "_id": 3, "name": "Facebook", "address": "脸书"}, { "_id": 4, "name": "Taobao", "address": "淘宝"}, { "_id": 5, "name": "Zhihu", "address": "知乎"} ] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值 print(x.inserted_ids) # TODO 没有指定 id 值的数据可以重复擦入,系统会自动生成唯一的 id 值,指定 id 值的数据不能重复插入
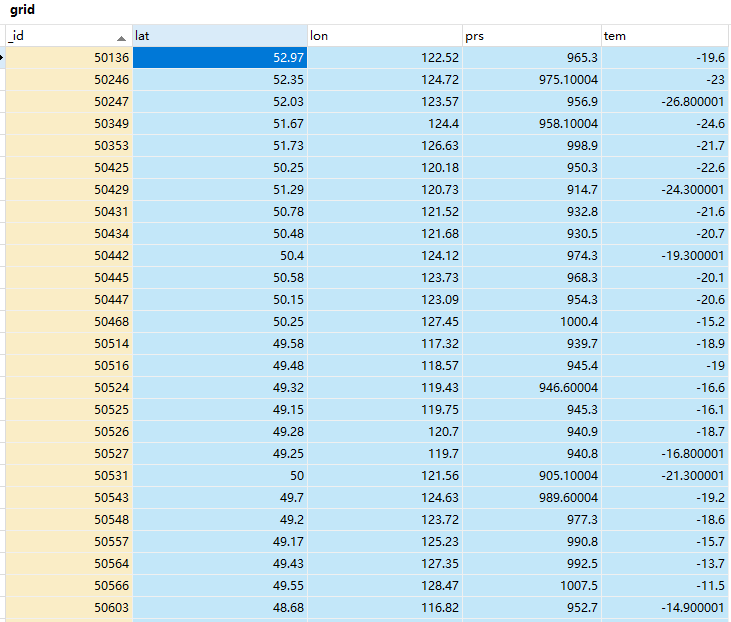
添加数组
mycol = mydb["grid"] # f = nc.Dataset(r'C:UsersxixiDocumentsFsdownloadwen_chkkl_ewenEWEN_REAL_GROUND_STATION_OBS_20201206002000.nc', 'r') var_key = list(f.variables.keys()) sta = f.variables['sta'][:] lat = f.variables['lat'][:] lon = f.variables['lon'][:] prs = f.variables['PRS'][:] tem = f.variables['TEM'][:] print(var_key) print(sta) data = [] for i,v in enumerate(sta): # 添加数据类型 float np类型不行 d = {'_id':int(v), 'lat': float('%s' % lat[i]), 'lon':float('%s' %lon[i]), 'prs':float('%s' %prs[i]), 'tem':float('%s' %tem[i])} data.append(d) f.close() print(data[1]) data=[{ '_id':20201206002000, 'lat':lat.tolist(), 'lon':lon.tolist(), 'prs':prs.tolist(), 'tem':tem.tolist(), }] x = mycol.insert_many(data) print(len(x.inserted_ids))
查询数据
# 查询查询一条数据
x = mycol.find_one() print(x)
# 查询集合中所有数据
x = [i for i in mycol.find()] print(x)
# 选择列是否输出 1 输出 0 不输出 # 除了 _id ,你不能在一个对象中同时指定 0 和 1,如果你设置了一个字段为 0,则其他都为 1,反之亦然
for x in mycol.find({},{ "_id": 0, "name": 1, "alexa": 1 }): print(x)
# 查询字段 指定类型 2 代表 string
print([i for i in mycol.find({'alexa':{'$type': 2}})]) print([i for i in mycol.find({'alexa':{'$type': 'string'}})])
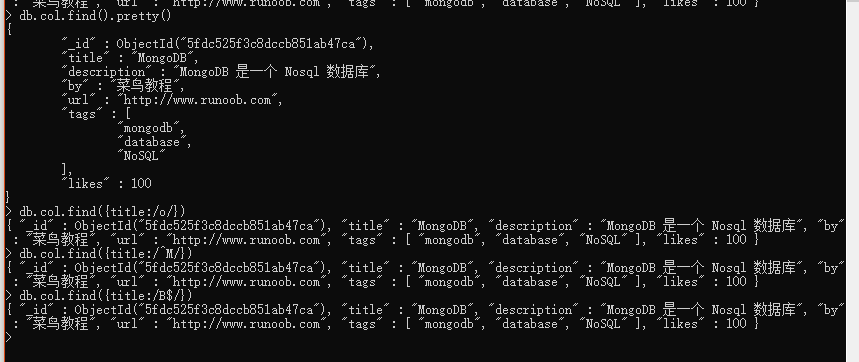
# 模糊查询 写法适用于 cmd命令行 (代码可以用正则)
db.col.find({title':/M/}) # 中间有 M
db.col.find({title':/^M/}) # 以 M 开头
db.col.find({title':/M$/}) # 以 M 结尾
# 查询 指定字段名
myquery = {"name": "RUNOOB"}
mydoc = mycol.find(myquery)
print([i for i in mydoc])
# 条件查询,id > 2 并且 alexa=123 或 name = yitianqi
# myquery = {"_id": {'$gt':2}, '$or':[{'alexa':'123'}, {'name':'yitianqi'}]} myquery = {"_id": {'$gt':2}, '$or':[{'alexa':123}, {'alexa':222}]} mydoc = mycol.find(myquery) print([i for i in mydoc])
# 查询 指定字段名的集合
myquery = {"name": {'$in':["RUNOOB", 'Google']}}
mydoc = mycol.find(myquery, {"_id": 0, "name": 1, "alexa": 1})
print([i for i in mydoc])
# 返回指定条数记录 skip 跳过前 2 条
for i in mycol.find().skip(2).limit(1): print(i)
聚合查询
# $match: 查找条件匹配 # $project: 字段筛选, 也可以用来重命名字段 # $group: 集合规则(_id: 需要分类的字段, count:求和,计算总数) # $sort: 排序 # $limit 限制管道输出的结果个数 # $skip 跳过制定数量的结果,并且返回剩下的结果 # $unwind 将数组类型的字段进行拆分 # 指定集合 mycol = mydb["surf"] # 不存在则创建,但是只有在内容插入后才会被真正创建 x = mycol.aggregate([ {'$match':{'surf_chn_basic_info_id':'54654'}}, {'$group': {"_id": "$surf_chn_basic_info_id", 'max_t': {'$max': '$observe_time'}}}, {'$project': {"_id": 0, "max_t": 1}}, ]) print([i for i in x]) mycol = mydb["sites"] # 查询最大 x = mycol.find().sort('alexa', -1).limit(1) print([i for i in x]) x = mycol.aggregate([ {'$match':{'name':'Google'}}, {'$group': {"_id": "$name", 'max_t': {'$max': '$alexa'}}}, # {'_id': {'fName':'$fName','user':'$user'}}, # {'$limit':1} ]) print([i for i in x])
修改数据
# 调用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。 # 如果查找到的匹配数据多于一条,则只会修改第一条
myquery = {"_id": 2}
newvalues = {"$set": {"alexa": 222}}
x = mycol.update_one(myquery, newvalues) # upsert 如果不存在update的记录, 则插入为新记录
print(x.matched_count, x.modified_count, "文档已修改")
# 调用update_many()方法,则会将所有符合条件的数据都更新 # 使用正则($regex)将查找所有以 F 开头的 name 字段,并将匹配到所有记录的 alexa 字段修改为 123
myquery = {"name": {"$regex": "^F"}}
newvalues = {"$set": {"alexa": 123}}
x = mycol.update_many(myquery, newvalues) # 它会自动判断是否已经为 123 ,如果已经都为 123 则,打印的修改数为 0
# 匹配的数据条数 影响的数据条数
print(x.matched_count, x.modified_count, "文档已修改")
排序数据
# 对字段 alexa 按升序排序 mydoc = mycol.find().sort("alexa") for x in mydoc: print(x) # 对字段 alexa 按降序排序 mydoc = mycol.find().sort("alexa", -1) for x in mydoc: print(x)
删除数据
# 删除name==Taobao的记录 myquery = {"name": "Taobao"} mycol.delete_one(myquery) # 删除正则表达式 name 以 F 开头的记录 myquery = {"name": {"$regex": "^F"}} x = mycol.delete_many(myquery) print(x.deleted_count, "个文档已删除") # 删除集合中的所有数据 mycol.delete_many({})
删除集合
# 如果删除成功 drop() 返回 true,如果删除失败(集合不存在)则返回 false mycol.drop()
创建索引
# background 后台执行创建 unique 是否唯一 name 索引名 expireAfterSeconds 指定一个以秒为单位的数值,设定集合的生存时间 ds = mycol.create_index([("name", pymongo.ASCENDING)], background=True) print(ds) # 返回索引名
# 查看集合索引 # db.col.getIndexes() # 查看集合索引大小 # db.col.totalIndexSize() # 删除集合所有索引 # db.col.dropIndexes() # 删除集合指定索引 # db.col.dropIndex("索引名称") # 利用 TTL 集合对存储的数据进行失效时间设置:经过指定的时间段后或在指定的时间点过期,MongoDB 独立线程去清除数据。类似于设置定时自动删除任务, # 可以清除历史记录或日志等前提条件,设置 Index 的关键字段为日期类型 new Date()。 # 例如数据记录中 createDate 为日期类型时: # 设置时间180秒后自动清除。 # 设置在创建记录后,180 秒左右删除。 # db.col.createIndex({"createDate": 1},{expireAfterSeconds: 180}) # 由记录中设定日期点清除。 # 设置 A 记录在 2019 年 1 月 22 日晚上 11 点左右删除,A 记录中需添加 "ClearUpDate": new Date('Jan 22, 2019 23:00:00'),且 Index中expireAfterSeconds 设值为 0。 # db.col.createIndex({"ClearUpDate": 1},{expireAfterSeconds: 0}) # 其他注意事项: # 索引关键字段必须是 Date 类型。 # 非立即执行:扫描 Document 过期数据并删除是独立线程执行,默认 60s 扫描一次,删除也不一定是立即删除成功。 # 单字段索引,混合索引不支持
代码仅供参考,欢迎评论交流