主要内容
-
消息的存储原理
-
Parition的副本机制原理
-
副本数据的同步原理
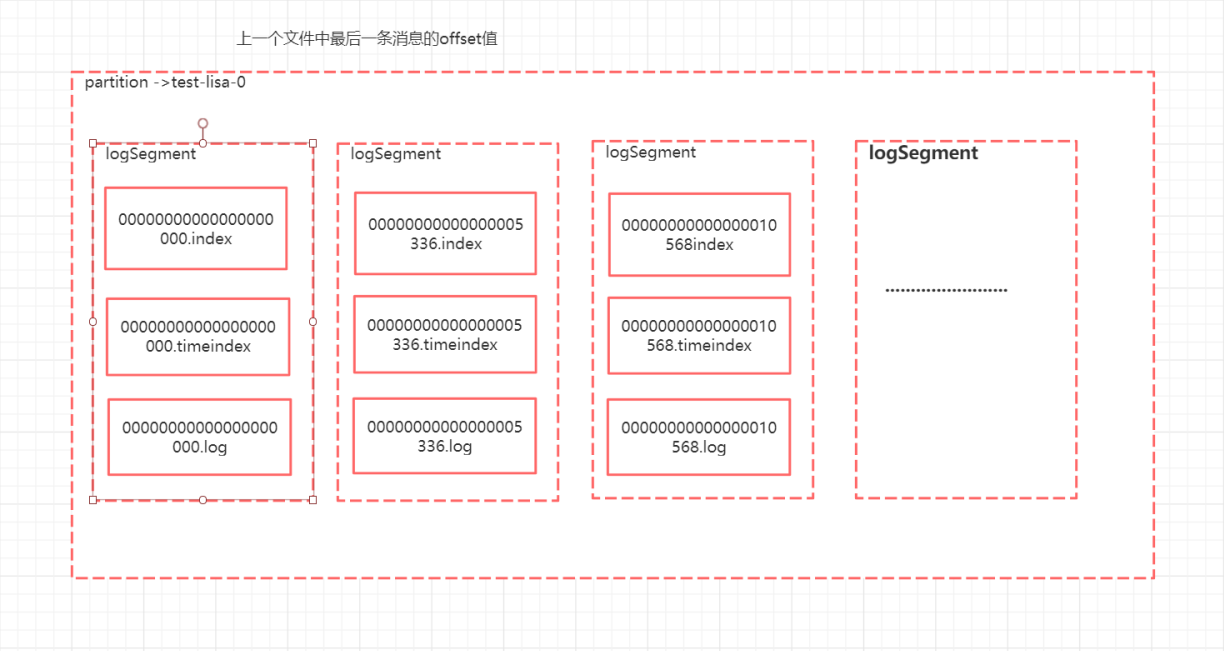
日志分段
LogSegment ->
日志文件默认大小 1G,当前log日志文件到达阈值1G的时候才会生成下一个分段
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /temp/kafka-logs/test-lisa-0/00000000000000000000.log --print-data-log sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /temp/kafka-logs/test-lisa-0/00000000000000000000.index --print-data-log sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /temp/kafka-logs/test-lisa-0/00000000000000000000.timeindex --print-data-log
log文件中的内容
offset 是逻辑位置,postion是物理位置
日志清理和日志压缩
日志默认保留是7天,可以修改配置
根据时间来保存
根据大小
-
log.cleanup.policy=delete启用删除策略
-
直接删除,删除后的消息不可恢复。可配置以下两个策略:
-
清理超过指定时间清理:
-
log.retention.hours=168
-
超过指定大小后,删除旧的消息:
-
log.retention.bytes=1073741824
partition副本机制概念
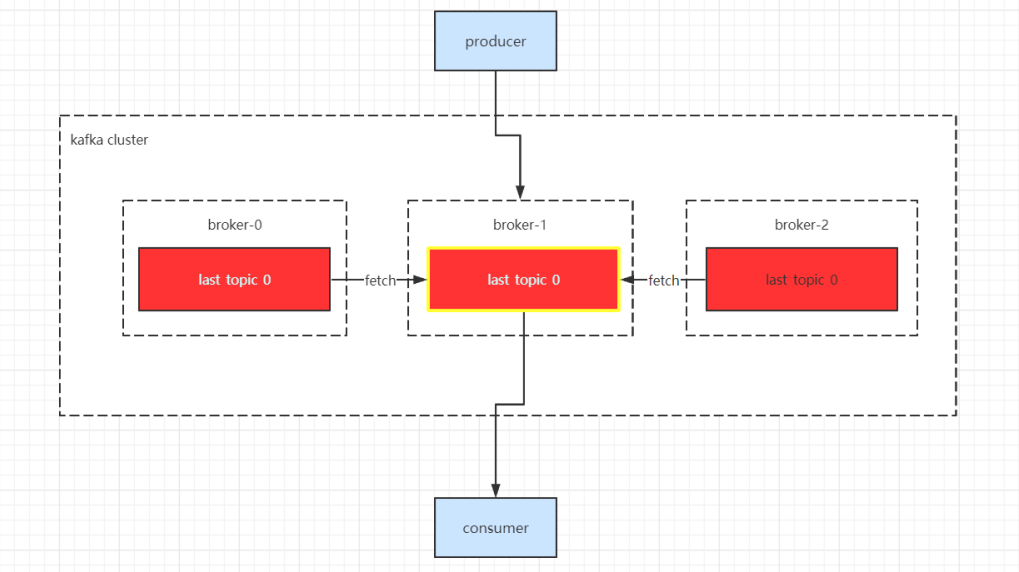
partition的副本被称为replica,每个分区可以有多个副本,并且在副本集中会存在一个leader副本,所有的读写请求都会通过leader完成,follower复制只负责备份数据。
副本会均匀分配到多台broker上,当leader节点挂掉之后,会从副本集中重新选出一个副本作为leader继续提供服务
副本分配算法
n个broker 将第i个partition的第j个副本分配到第((i+j)mod n)个broker上

get /brokers/topics/test-lisa/partitions/0/state
{"controller_epoch":13,"leader":0,"version":1,"leader_epoch":1,"isr":[0]}
isr 维护当前分区的所有副本集。(in sync repilcas),follower副本必须要和leader副本的数据在阈值范围内保持一致
leader 副本负责接收客户端的消息写入和消息读取请求
follower 副本负责从leader副本读取数据 (不接受客户端的任何请求),如果follow副本和leader副本数据同步速度过慢,该follow将会被T出ISR副本
ISR集合中的副本必须满足的条件:
-
副本所在的节点与zk相连
-
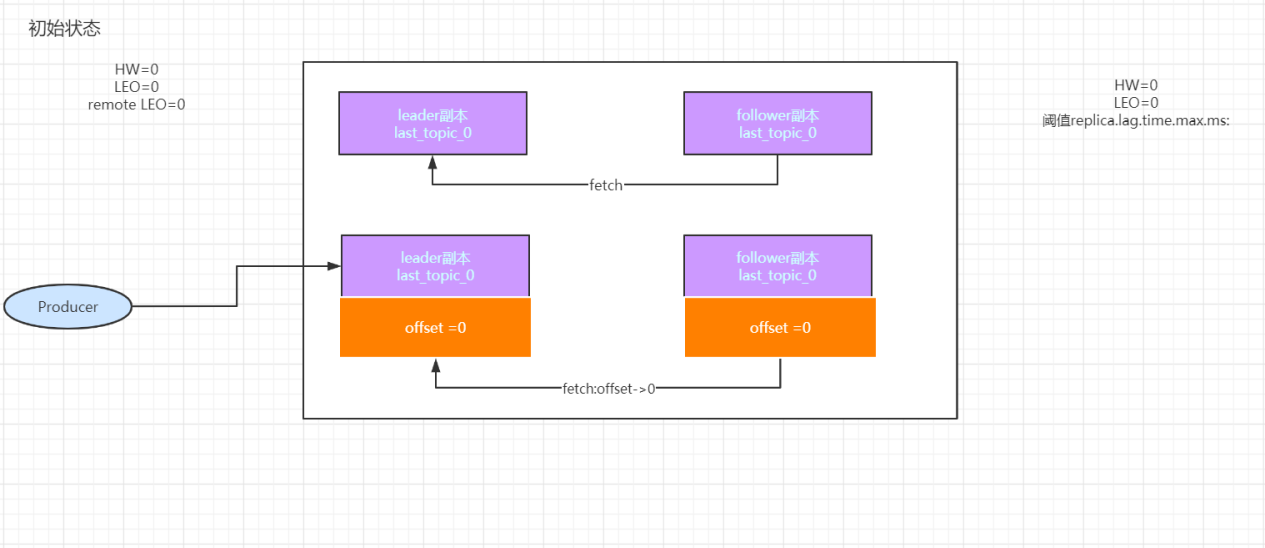
副本的最后一条消息和leader副本的最后一条消息的差值不能超过阈值replica.lag.time.max.ms:如果该follower在此时间间隔之内没有追上leader,则该follower将会被T出ISR
副本同步时的两个重要概念
LEO(Last end offset) 记录了该副本底层日志中的下一条消息的offset,例如LEO为10,那么当前的offset为9
HW (High water)标记着可消费的消息,对于同一个副本而言HW不会大于LEO,小于等于HW的消息将会被认为是已备份的。
1、把消息写入到对应分区的log文件中,同时更新leader副本LEO
如果ISR为空怎么办?leader副本也挂了
1、等待ISR中的任意一个replica活过来,重新选举leader
2、选择一个活过来的replica 作为leader

1、分区应该设置多少合适
没有标准,根据实际吞吐量来进行设置
Kafka监控工具:kafka monitor 、kafka offset monitor /kafka-manager
kafka高性能
-
采用操作系统层面页缓存来缓存数据
-
-
partition的水平分区的概念,能够把一个topic拆分多个分区
-
发送到和消费贷都可以采用并行的方式来消费分区中的消息
设置50000个分区。->批量发送batch.size,linger.ms(针对同partition 而言) ->内存占用过高
50000个消费者->多线程(怎么分配consumer的消费能力)
文件句柄。logsement->index/log文件
副本-> 1个副本 50000个分区落到10个broker上,每个broker 5000个分区,存在5000个分区需要选leader
1、硬件资源
2、消息大小
3、目标吞吐量
《峰值消息大小》一个topic一个分区的情况下,针对目录硬件资源压测->tps发送端的tps和消费端tps