这是我4月份在BitTiger公开课听的王赟大牛《语音识别的前世今生》整理的笔记,本来打算整理通畅再发的,结果实在没时间就一拖再拖。笔记有些草率,不过应该可以看明白,希望可以对有用,也祝王赟大神好。





比较一下蓝色的波形和绿色、红色波形,哪个更接近,那就认为我说的是哪个词。
数学语言:
定义一个距离,分别比较,距离小的就是结果。
问题:
这里比较的对象是波形吗?
波形怎么比较呢?
一、特征提取

怎么样把波形表示出来,让它更适合比较?
把语音的波形展开,一部分是有规律的震动(这个波形前面1/3),还有一些噪声(后面2/3)
特征提取不能从整个的波形上来提取,必须把它分成一段一段的,从局部上来提取。否则各种特点全都混在一起,很难分辨。
特征提取一般是先把语音分成一帧一帧的单位,上图红框中的部分。
为什么选这个长度?
它在微观上是足够长的。它至少包含了2到3个周期的语音信号。这里还涉及到声音的频率。一般人说话的频率男性一般在100hz,女性一般在200Hz左右,所以,男性的周期在10ms,女性的周期在5ms左右。所以20--50ms至少能包含2个周期。这样就能把局部上周期性的特征提取出来。
宏观上:声音性质不会有太大的变化
音素:比如a o e这种,一个音素的时间往往比20-50ms要长一点

拿到一帧信号要怎么做呢?
我们对它进行一个傅里叶变换,傅里叶变换的目的是去分析一下这一帧信号里有哪些频率分量,得到的结果叫做频谱。频谱就是一个函数,如上图方框中的蓝线,就是这一帧信号的频谱。它的横轴是频率,纵轴是magnitude即强度或者幅度。它就是说,这一段信号里面有哪些频率的分量比较强。
精细结构:一个一个的小峰。精细结构中每个峰之间的距离就代表音高。
包络:就是频谱的大致形状,图上红线划出来的东西就是频谱的包络。
音色:你说话时候口腔的形状,舌头的位置等等,其实就是你发的是哪个音,这个是主要信息。
做特征提取,就是在频谱中把精细结构的信息尽可能的去掉,尽可能的保留包络的信息。
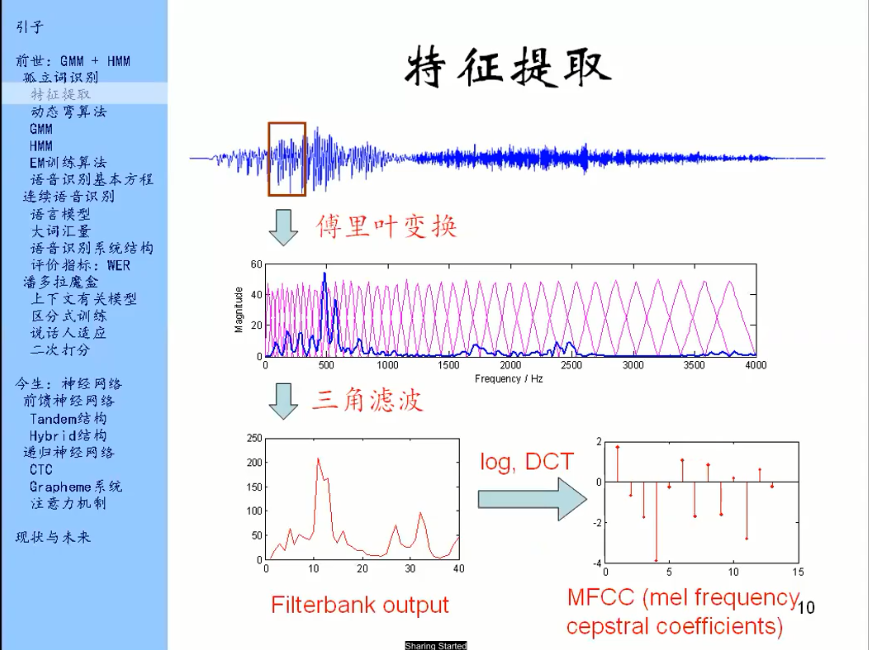
三角滤波指:计算一下每一个三角形里面的能量
计算出来的结果就是下面的红色的线条
三角滤波的作用:提取包络去掉精细结构。
一个三角形的宽度往往是会比精细结构上两个峰值之间的距离大,所以,计算这里面的总能量,结果就会发现精细结构就已经基本去掉了,剩下的这个形状基本就是包络的形状了。
图上也能看出,三角形画的并不均匀,左密右梳,这个是相当于仿生学,模仿人耳的特性。人耳在低频处分辨率比较高,在高频处分辨率比较低。所以三角形的设计也是在低频处比较密集,在高频处比较疏松。
三角滤波处理完得到的结果叫做滤波器组输出。
有了这个之后,还要经过一步数学上的变换。细节不讲,得到的结果是一个比Filterbank output长度更小的序列。Filterbank output一般是取40个左右,经过这一系列数学变换之后一般是取13个左右。得到的结果叫做MFCC
一帧信号经过一系列变换,变成了一个长度为13的向量。
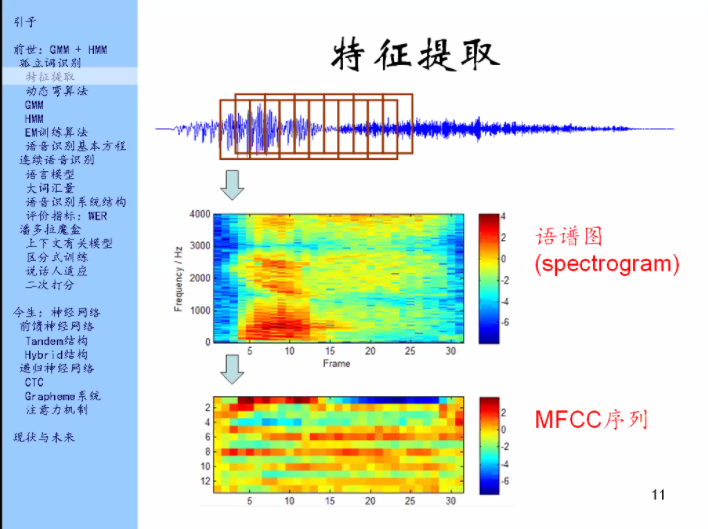
可以对一帧信号做一系列的事情,那么一整段语音是可以分成许多许多帧的,这些帧往往它们之间是取了有重叠。那么我们对每一帧都做一下这件事情。对每一帧都做一下傅里叶变换,然后把每一帧的傅里叶变换用颜色表示出来(竖着画,如图),然后每一帧的傅里叶变换给它并排起来,这种得到的图叫做语谱图。
经过训练之后,看语谱图就能知道说的是什么话。
把语谱图中的每一帧的频谱经过变换之后得到MFCC向量,把每一帧的向量排起来得到MFCC序列。这个序列就是整段语音的特征。
第一代的语音识别都是以MFCC序列为输入,即电脑听到/看到的都是语谱图,而不是波形。

二、
特征提取好之后,把一段语音表示成了一个向量序列。就像下面这样子,用不同的彩色表示不同的向量。 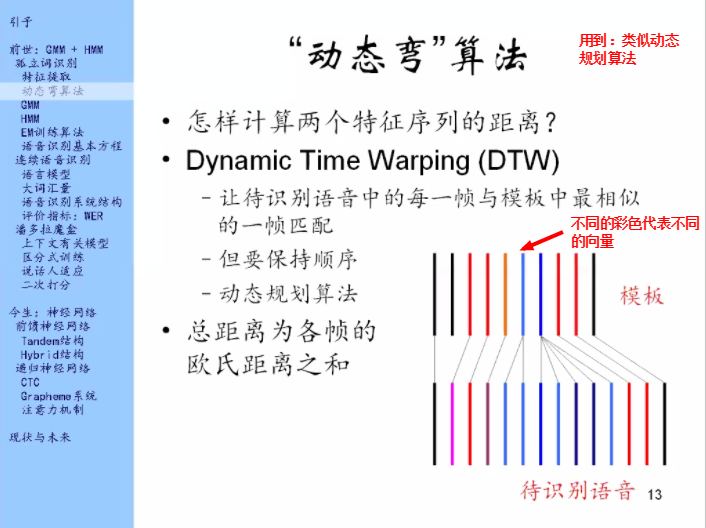



这里有一个很重要的问题是,它俩的长度不一定相等,那就没办法一帧对一帧的比较。
第一个问题就是,怎么计算这两个特征序列的距离?
动态弯算法:在保持顺序的条件下,去找跟每一帧匹配最好的的,可以用动态规划算法来解决。
欧氏距离:两个向量相减平方开根号
这样就做出来了一个孤立词系统。
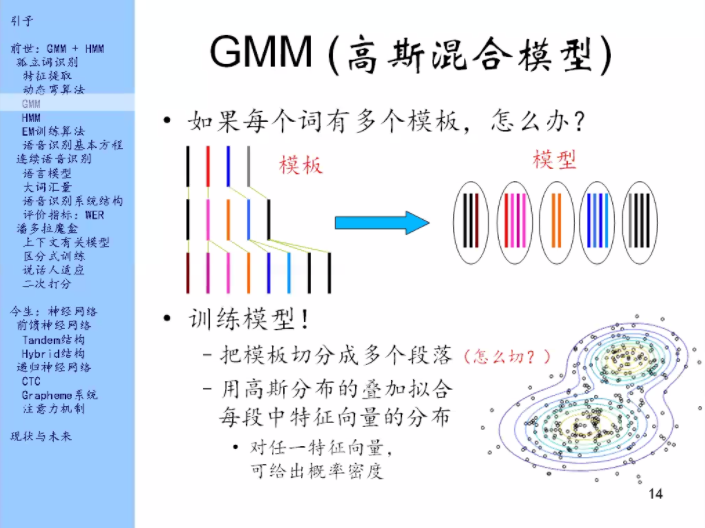
解决方案:
从模板中提炼一个模型出来。把每个模板切成多个段落,比如图上把每个模板切成5段,把每一段里的特征向量给规模起来,这几个向量把它提炼成一个分布,就是用一个高斯分布的叠加来拟合这些向量在空间中的分布。
很多个高斯分布在空间中叠加,其实是可以模拟任何分布的,只要你的高斯分布的个数足够多。
对于模型中的每一段,就来训练一个高斯分布来拟合这里面的向量在空间中的分布,这样就得到了一个模型。
切分成多个段落之后,每一段怎么理解?
常见的理解是:把每一段理解成为一个音素。但也不强制要求如此。
有了模型之后就要看怎么取识别未知的语音。即如何计算待识别语音和模型之间的距离。
还是用动态弯算法来把模型和待识别的语音对齐。模型里面是5个段落,也叫5个状态。
待识别语音里面就是很多帧。我们也是在保持顺序的条件下,去找每一帧对应的是哪个状态。
这个模型因为每一个状态里面有一个高斯混合模型的分布(GMM),由这个分布可以去算一下在这个特征向量的位置它的概率密度有多大。概率密度越大,说么这一帧的特征越像这个状态。与距离是相反的,距离是越小越好。
然后把各帧的概率密度乘起来。这个东西就当成是整个待识别语音在这个模型下的密度。当然概率相乘是要假设独立的。
这个是如何在有很多模型的情况下做孤立词识别。
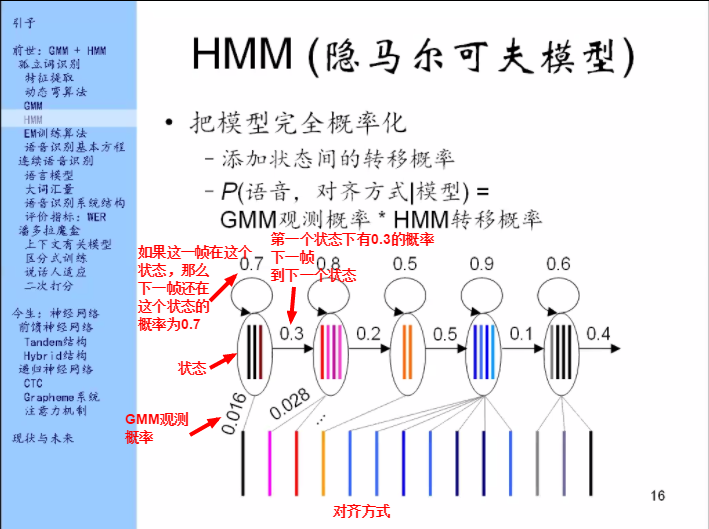
思路:刚刚的GMM把距离换成概率了,概率是个好东西,那我能不能把这个模型整个都概率了?
我添加一个东西叫做状态间的转移概率,其实是比较弱的在对状态的持续时间来建模。如果一个状态它自己头上的圈上的概率比较大,那就是说这个状态它持续的比较久。
有了这个模型之后如何去计算概率呢?
HMM怎么用呢?它里面有三大问题。
第一个问题叫做求值问题。就像之前我们做孤立词识别的时候我们来计算,计算的是给了一个模型求它们之间的距离,或者求它们之间的概率密度。那在HMM里面我们同样也做这间事情。就是求给定模型之后语音的概率。
那刚刚我们说HMM模型它本身定义的是什么呢?是给了模型之后语音和对齐方式的联合概率。
那我们怎么把对齐方式给去掉呢?
因为我们不知道对齐方式,所以就枚举一下所有的对齐方式,然后把这些联合概率全都加起来。根据全概率公式,它就是给定模型之后语音的概率。
对齐方式可能会有很多,不可能一个一个去枚举,这里又有一个动态规划算法。
解决了这个问题之后也就解决了孤立词识别的问题。
把这个模型训练,如果训练好了,那么我们来段语音,我们就用m求值问题的forward algorithm去算一下每一个模型语音的概率,然后求出最大值。
第二个问题是解码。这个其实就是前面讲过的动态弯算法的升级版。因为动态弯算法只考虑了观测概率,HMM中多了状态之间的转移概率,但是解决方法还是一样的,还是用到了动态规划算法。
这个动态规划算法还有个名字叫做Viterbi decoding
这里边有一个结论:最佳对齐方式的概率,可以作为总概率的近似
就是说,虽然对齐方式可以有成千上万种,但是其中最佳对齐方式的概率是比其他对齐方式的概率大得多的。所以只拿最大的这个就能近似所有的和。这个是语音识别里面常用到的一个近似。
第三个问题就是训练问题。
上面的求值问题和解码问题说的都是这个模型已经训练的很好了,参数都有了,我们怎么用它来做语音识别。
训练问题就是说我现在有了很多语音,然后这个模型的结构知道了,就像刚才那个的单向结构,但是没有参数,那我怎么来训练这些参数呢?
这里的问题就是如果知道了每一条的对齐方式,那就好了,怎么个好呢?
有了对齐方式,我们就可以数一数,通过数数来训练参数。
数一数当这一帧在这个状态的时候下一帧有多少次还是在这个状态,有多少次跑到下一个状态去了,然后这个比例就作为转移到自己的概率和转移到下一个状态的概率。
同样GMM也是,如果我知道了对齐方式,我就知道这些特征里面哪些帧的特征是来自于第一个状态的,那我就把这些帧的状态拿出来,然后用GMM训练算法等等,把这个参数训练出来,那这就好办了。
但问题是我们不知道对齐方式。






























经过EM算法得到的模型参数做了一件什么事情呢? 它是最大化的一个算法,它最大化的目标函数是在模型参数之下,所有训练语音的总的概率。这个东西叫做参数的似然值,所以它叫最大似然估计。
用链式法则来拆一句话的概率。
着重看Bigram,这个是在语言模型中最常使用的模型。
比如说我们刚才考虑到的是孤立词的语音识别,只考虑yes和no,这个词汇量只有2
那么可以再考虑一下别的模型,比如说打电话,那么词汇量是10
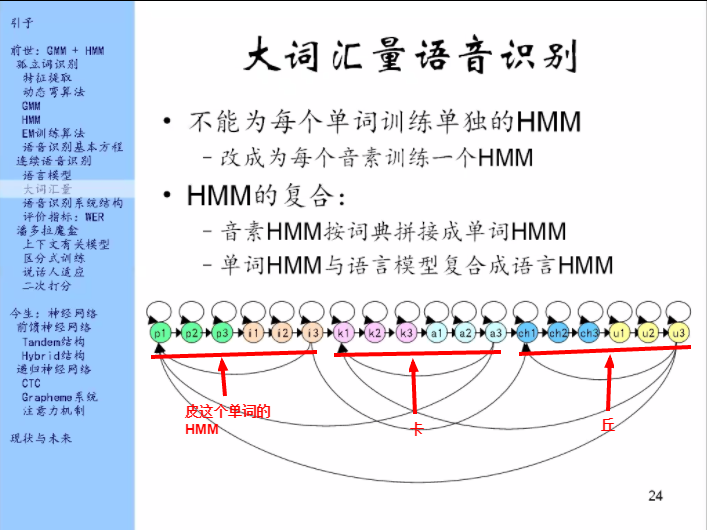
一门人类语言的词汇量一般是在万到十万这个数量级上。如果对每个单词训练一个单独的HMM,这个模型的体积就非常大了。而且为了训练一个单词的HMM,需要录入100个这个单词的发音,那对一门语言的一万个单词,每个都录入100遍,这是不现实的。
所以在大词汇量的情况下,就不能给每个单词都训练HMM了。那就要找更小的单位,就是因素这个单位。
为每个音素训练一个HMM
音素的HMM可以复合成单词的HMM,复合方法就是直接串起来。
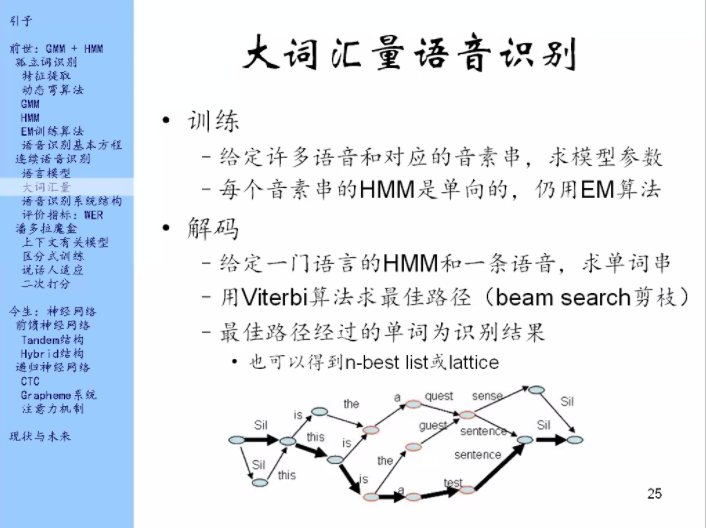
那这个东西怎么用?也是分为训练和解码两个部分。
解码:在这样一个语言的HMM里面,去求最佳路径,就是说我一边走,一边让这些状态去产生特征向量,那么我走哪些状态能够让产生实际观测到的这条语音里的特征数的特征向量的概率最大。在这个过程中可能还需要一个剪枝的手段。
这个方法不仅可以找最好的一个路径,也可以找最好的N条路径。
Read Speech:朗读的读音,质量比较高的语音。
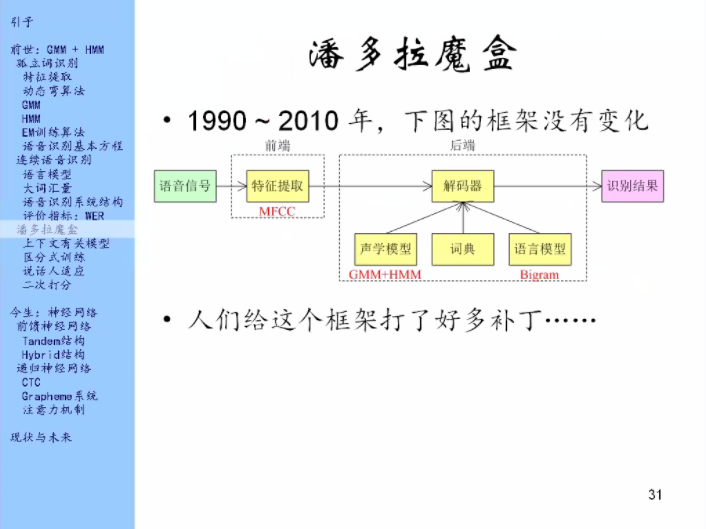
以下讲几个有代表性的补丁。
一层神经网络就是在这层网络里面放很多个神经元,每个神经元接收到信息之后,它的加工方式(参数W,b)是不一样的。
写成向量的形式。
W为4*3的矩阵
最简单的神经网络结构叫做前馈神经网络
非线性就是如果大家知道复杂系统或者蝴蝶效应或者混沌之类的就会知道,非线性多了之后就会呈现出来一些很神奇的现象。
为什么多层的非线性有巨大的?
比如在Google里面猫狗图片,
第一层:看花纹
第二层:看器官眼睛啊什么的
第三层:看出脸
然后判断是猫是狗
每一层可以识别不同抽象程度的特征,越靠近输入它识别的是一些底层的特征,高层就识别这种更高层的抽象的特征。这跟人类大脑的工作也是近似的,只不过人们有意识的是最高的那层,至于底层眼睛是怎么看的,耳朵是怎么听的,你并不是有意识的知道。
设计一个损失函数,比如前面提到过的WER就可以作为一个损失函数,当然它有些缺点,比如不可导之类的。所以大家一般是用最大似然值来做损失函数。
在损失函数中把参数看做是自变量,要找到一组参数使得损失函数值最小。这里的优化方法常用的是梯度下降算法。
梯度下降法在做的时候是要求导的,函数求导有一个链式法则,神经网络是一层一层的,正好适用于链式法则,在算的时候损失函数放在输出端,用链式法则把它放在输入端一层一层的去求导,这个事情叫做反向传播。
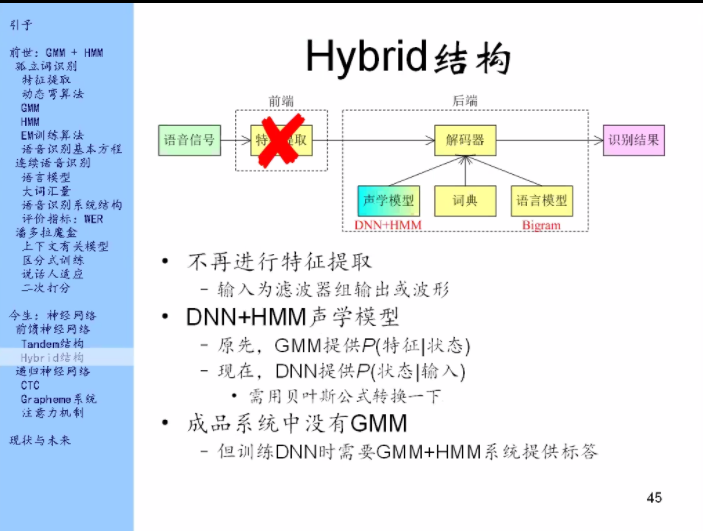
现在看神经网络在语音识别中是怎么用的,它是怎么一点点的把GMM和HMM给吃掉的。
神经网络小试牛刀——用神经网络做一下特征提取吧
为什么要做这件事?
因为上一个十年大家都在研究特征怎么样做能够尽可能的去避免各种不利因素的影响,比如回音、噪音。用深度神经网络(DNN)代替了MFCC
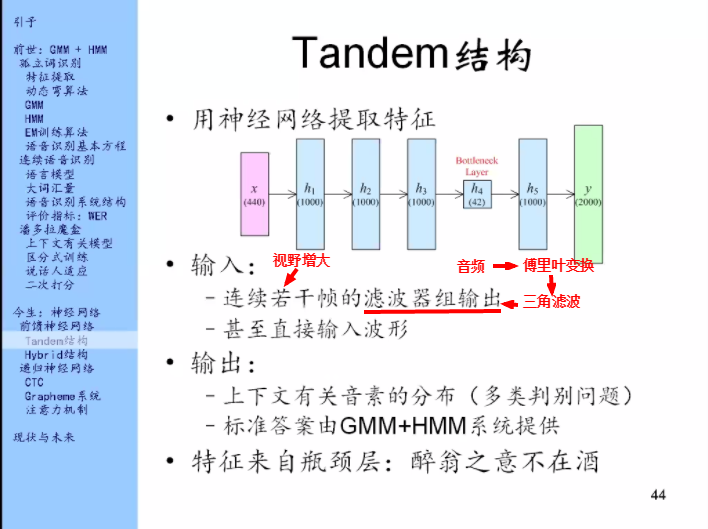
一帧的滤波器组输出是40位,就是有40个三角形滤波器,那么同时给它11帧的滤波器组输出,那就形成一个440位的滤波器组输出,它作为神经网络的输入。
y(2000):上下文有关因素
神经网络就来解决这样一个问题:我拿到一帧和它周围的信号,无论是波形也好还是滤波器组输出也好,我来判别一下,在这一段中间的是哪一个因素,是哪个上下文有关因素。
标准答案:我知道完整的句子,可是我不知道对应的每一帧的答案是什么。这又是一个对齐问题。标准答案由GMM+HMM系统提供。
训练出来这样一个神经网络之后,特征从哪儿来呢?
它是从中间这层来的。中间有层特别窄(比如图中的h4)叫做瓶颈层。
训练好这个神经网络之后就把输入输进去,对于每一帧把瓶颈层拿出来当特征,用它来代替原来的MFCC
训练这个系统的时候需要传统系统来提供标准答案,所以还是依赖传统系统的。
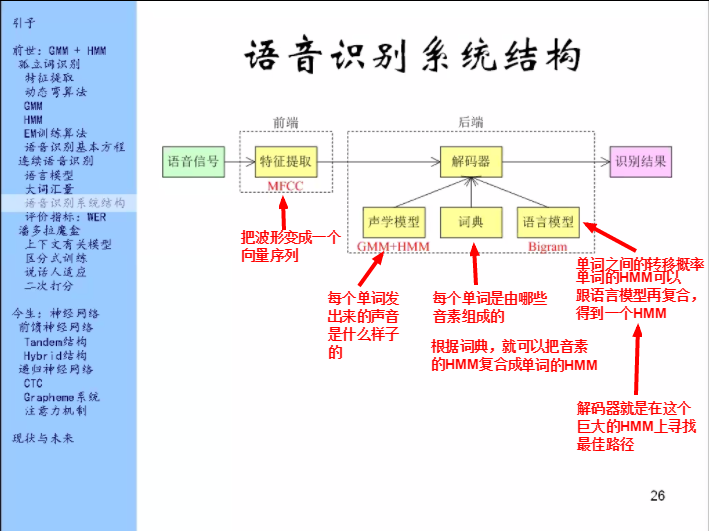
声学模型:就是用来建立音素和声音之间的关系的。
原先声学模型这里是用GMM来做的,它给出的结果是每个状态,就是在给的这个状态下,这个特征的概率是多少。
现在这个DNN就是按照上页的这个形式,我输入一个东西,给出的结果是上下文有关音素的分布,这些音素我可以把它转化成状态,那我就能得到给定输入时候输出的每个状态的概率。
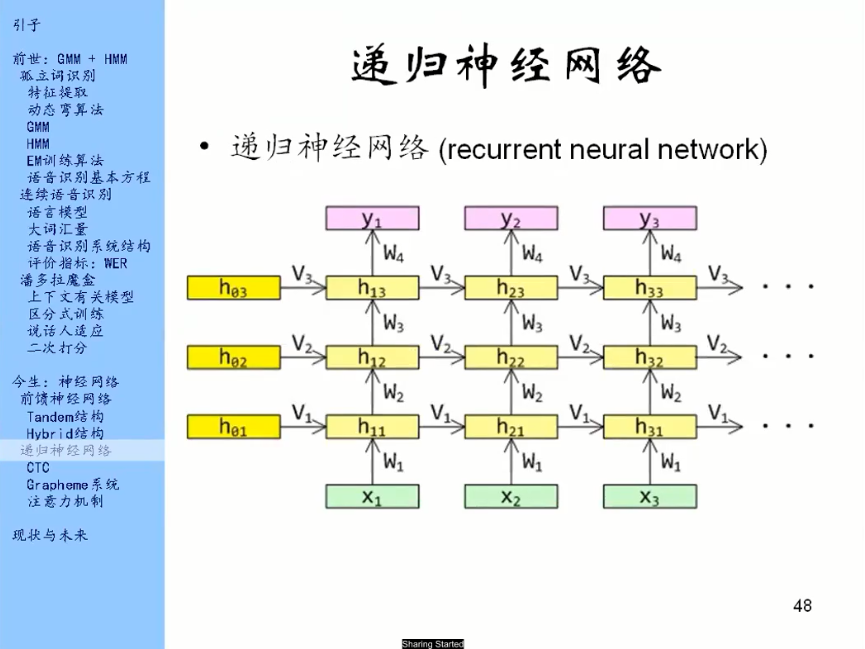
语音识别问题是一个序列问题,它是一个时间序列。前馈神经网络是一层一层的往前走,现在把这一层给竖起来,现在的横轴代表时间,x1,x2,x3代表每一帧的输入(滤波器组输出,甚至就是波形)。
不同时间下对应的参数都是相同的,但是它们都是独立处理的。所以有可能我只输入一帧的特征,它感觉上下文少了点儿,所以我要输入连续11帧的特征。
有了上图之后会很自然的想到,我为什么不像下图这么干呢?
就是让神经网络里的每一个元素,不仅仅是从底下那一层来接收信息,它还从它前面的一步的同一层来接收信息。那这样子不就是能看到历史了么?
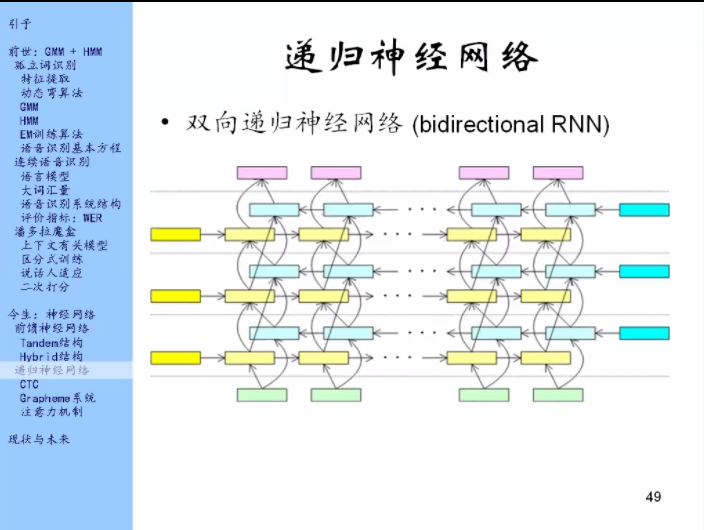
这样就有了递归神经网络。
上图中黄色的部分就是之前的递归神经网络,蓝色的部分是黄色的部分反过来,箭头是从右往左的,黄的和黄的之间、蓝的和蓝的之间有箭头相联系,同时蓝的和黄的,黄的和蓝的之间也有联系。
这个网络就厉害了!
所以每一帧的输出都能看到整个输入,这个的上下文理论上是无限的。
为什么可以不要HMM了呢?
因为HMM的两个作用,一个是在训练的时候提供对齐,现在我不要对齐了;另外一个是HMM本来是用来做帧之间的转移概率的,现在我说你这个建模很粗糙,我不要了。HMM就没用了。
CTC是怎么建模每个音素的持续时间的呢?
它其实根本及不去建模。它做了一个更加激进的假设:它假设各帧的输出的相互独立的。
你像HMM还假设各帧之间的转移是有概率的,相邻的帧之间还是有关系的,CTC干脆就假设各帧之间的输出是相互独立的。
为什么可以这样呢?
因为CTC的底下是一个RNN,RNN的上下文处理能力很强。那么它就认为RNN已经把上下文全部处理干净了,这里可以直接假设独立。
CTC是当前的主流。
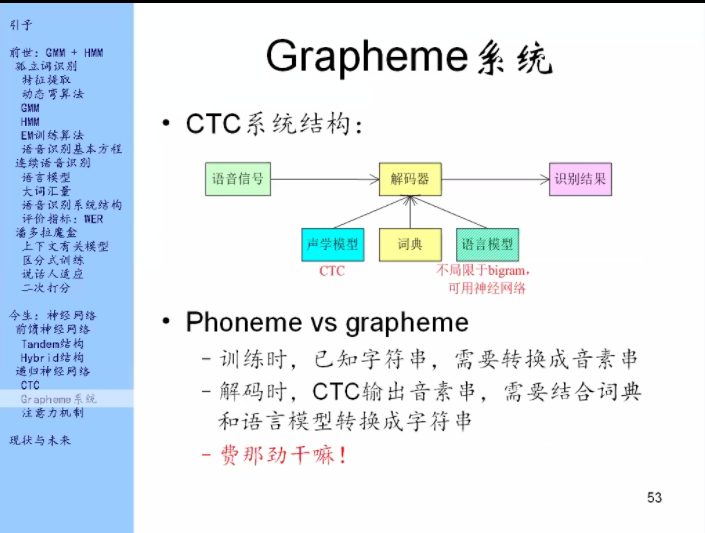
Grapheme的思想:输入和解码都直接以字符为单位,而不再以音素为单位。
Grapheme系统:进来一个语音信号,输出的直接就是字符。
为什么到了现在大家才这么做?
上一代大家也这么做过,但是效果不好,这里涉及到英语的特点:拼写、发音不规则。如果以音素为基本单位,同一个音素就算它有不同的上下文,它的发音也都是差不多的。但如果要用字符做基本单位的话,那么同一个字符在不同的上下文中的发音是非常不一样的。这个就是声学模型建模上的很大的一个困难。
CTC最大的好处是:它用的是递归神经网络。递归神经网络能够处理上下文,所以它就不怕拼写不规则。所以Grapheme系统有了神经网络之后就有了比较好的效果。
系统的优点:
1. 简洁,没有那么多模块了,就一个神经网络从头到尾,这就叫端到端的模型(end to end)
2. 不需要语言知识,比如之前要做一个英语语言系统,就需要知道英语里边有哪些音素(音标),有了Grapheme系统就不需要,只需要知道英语有26个字母就足够了。
3. 不怕生词。之前的系统,输出的单词都只能是词典里的单词,出来生词的时候它就不认识了,比如在04年的时候Obama就是个生词,无法识别,08年之后这些系统才把Obama这个词放到词典里面去。Garpheme系统不怕生词,它可以去猜这个单词怎么拼。
4. 可进行端到端的训练:之前的魔性有两个模块——声学模型和语言模型,它们分别训练,就存在劲儿不往一块儿使的问题。Grapheme只有一个模块,就不存在这个问题。
缺点:
1. 因为什么事儿都由一个网络来做,它包揽了一切,这里边尤其像词典这种比较困难的学习任务它也要学。就是它需要同时学好多科目,所以它就需要更大量的数据来训练它。
2. 语言模型是包含在解码器里面,不是显示在外挂,语言模型的训练是比声学模型的训练容易的,为什么?因为声学模型的训练需要同时有语音和文字,而语言学习的训练只要有文字就够了,文字是比语音更容易获得的。比如我去网上把维基百科爬下来,这就是很大量的文本数据,它是没有语音的,它可以用来训练语言模型。现在语言模型在解码器里分离不出来,那么就要求训练语言的数据也都是语音的才行,那这个内置的语言模型就不如外挂的强了。
所以,这种字符系统在用的时候一般会再外挂一个语言模型,这个模型就是拿纯文本的数据训练出来的,它和解码器里隐含的语言模型是共同作用。这个结果就比只用一个CTC的效果要好。外挂的语言模型一般也是神经网络的。
最早在14年左右用在机器翻译上的。
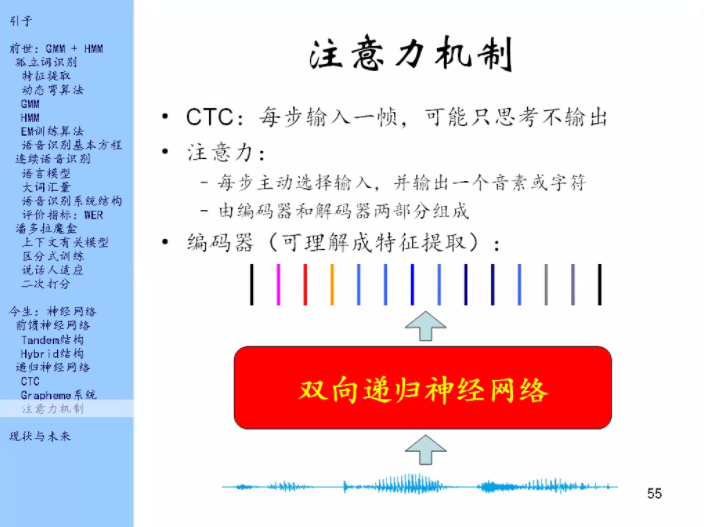
CTC每一步输入一帧,输出有的时候是输出音素,有的时候是输出空白,它输出空白的时候我们就可以认为它在思考。
然后我们会发现它有很多帧在思考,很浪费。那我们就想办法,让它不需要每一步输入一帧,可以让它每步输入很多东西,然后每步输出一个音素或字符。就是不让它思考了。比如它本来要思考5帧,那我们就一次性把这5帧都输入进去,那么给输出一个音素或字符出来。
这里它会主动的选择输入。这就是在模仿人的注意力机制,就是说这句话我看到这里之后,我会主动的想我下边想从哪里去获取我的这个信息。
注意力机制也是通过神经网络来实现的。这个神经网络分为编码器和解码器两个部分。
编码器可以理解为特征提取,它就是一个双向递归神经网络,它的输入就是波形/滤波器组输出,输出就是一大堆向量的序列。编码器不是注意力机制的重点。
重点是在解码器上。
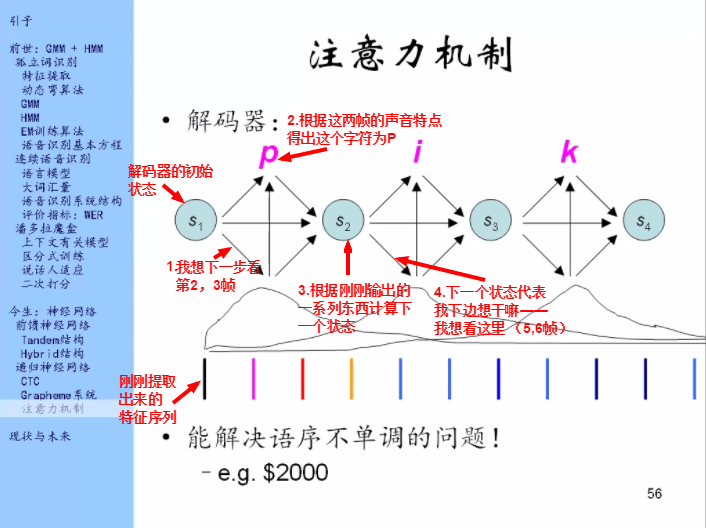
解码器的工作原理如图。
能解决语序不单调的问题,这个在机器翻译里面特别重要。比如英语和汉语就有一些语序不一样的地方,比如说地址的时候汉语是从大到小,英语是从小到大,这就是语序不一样。那在做地址翻译的时候,比如下面是汉语句子,上面是英语句子,那就不能像上图这样每一步往前看,你应该是一开始就看结尾,然后每一步往后看。
在语音识别里面这个问题不是那么的重要,但是偶尔也有。比如说$2000,但是我们在读的时候是two thousand dollars,dollars是最后发音,这里也有一些语序不单调的问题,那么注意力机制及很擅长解决这个问题。