如果你正在苦恼如何写一个正则的话,那么或许本文对你有所帮助
文中的这个例子或许同个字符串截取同样可以做到,但本文仅尝试以纯正则的角度解决问题
转载请注明出处 https://www.cnblogs.com/majianming/p/14590599.html
首先看一下这个例子
<br><br>D >> - MJ 1989<br>
<br>D - MJ 2000>><br>
<br>D - 17.05.2011>> - MJ 2013<br>
<br><br>D - MJ 2010>> - 01.11.2010<br>
<br>D - 24.06.2002>> - 25.08.2002<br>
<br><br><br><br><br><br>D - MJ 2011>> - MJ 2011<br>
需求是获取br标签中的MJ 2000 或者 25.08.2002 这个字符串;在>> 这个左边的是开始日期,右边是结束日期,最后的结果需要给出开始年份和结束日期的字符串,并且如果任意一个日期为空,也需要提取出来,因为需要提取出的一个是开始日期还是结束日期
在开始之前,我们假设一下我们最后可以的到的结果
分组1为开始年份 比如MJ 2000 或者为空串
分组2为开始年份 比如MJ 2013 或者为空串
好的 我们现在以这个结果去找寻可能的解决方案
首先我们可以观察得到这样的规律
这个字符串以若干的<br>开头和结尾,并且在开头的<br>结束之后会有个D
那么我们的开头为^<br>(这个地方先假设只有一个<br>),前文说到会有多个<br>,所以我们需要用量词来形容,并且我们需要形容的是整个<br> 所以需要用括号包裹起来,我们假设至少会有一个<br>
所以我们的式子变为^(<br>)+`
接下来匹配开头br 结束的D
式子为^(<br>)+`
同理可得结尾式子应该是(<br>)+$
然后我们先把首尾衔接起来,中间使用.* 先匹配所有文字,同时使用分组包裹 即(.*)
^(<br>)+D(.*)(<br>)+$
可以得到这样的匹配结果

我们会发现实际上我们只是为了<br>这个标签用量词进行形容,我们并不关心他里面是什么值将需要从不分组上获取到的,但是现在我们
现在可以从看到实际上我们将这个标签的值获取到了分组,并且占用了分组1的位置,导致我们的结果获取到了不必要的文本(如果可以接受分组1 并不是我们需要的结果 也可以忽略)
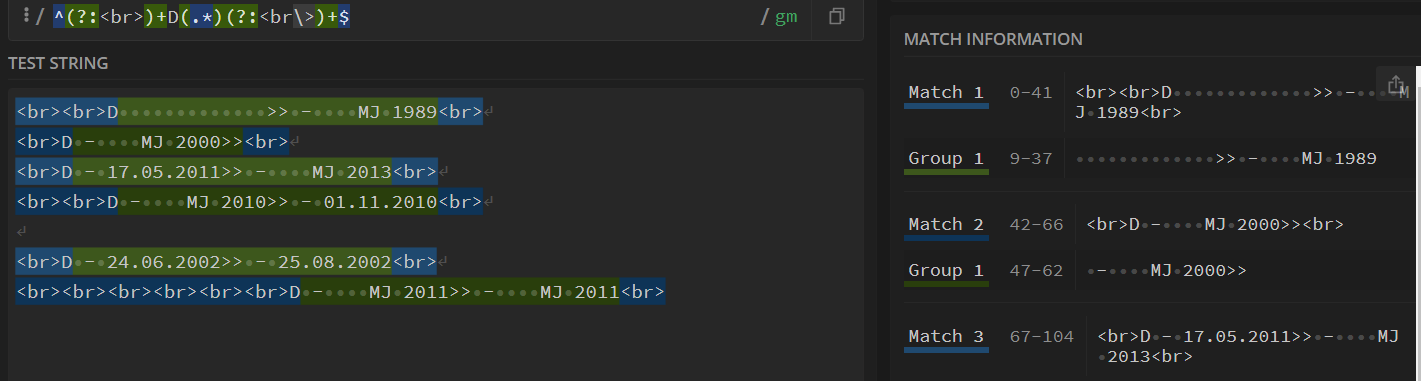
所以我们使用非捕获组(?:)来包裹一个式子 用来表示这个我们只是想对整体进行一些操作,但是我们并不关心这个式子是什么内容
所以我们的式子变成^(?:<br>)+D(.*)(?:<br>)+$
我们也可以看到我们现在获取到了整个除了br的文本内容
通过>>可以将文本内容分为开始时间和结束时间
所以分两部分提取内容 式子为 ^(?:<br>)+D(.*)>>(.*)(?:<br>)+$
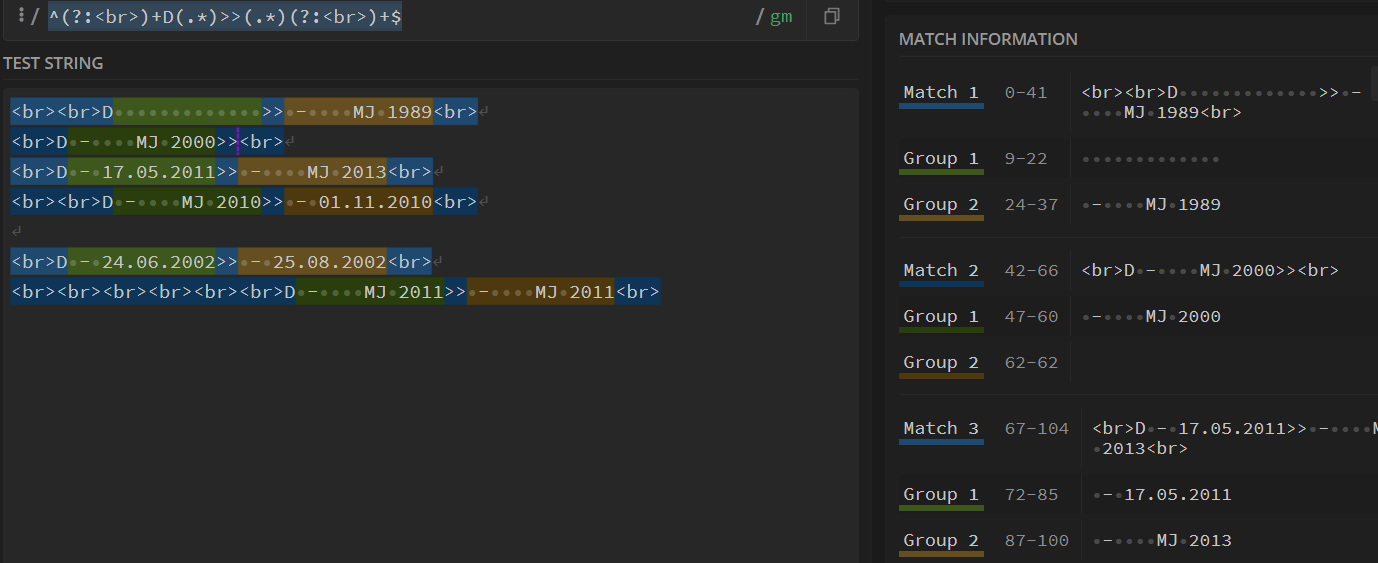
可以看到每个匹配的项中都有且只有两个分组,并且分组中含有我们需要的日期
那么我们接下来需要做的就是在这个文本中提起我们需要的部分
先看左边
有三种情况空的 、MJ 2000以及24.06.2002 三种情况 并且存在一些空格
所以我们用(MJ d{4}) 和 (d{2}.d{2}.d{4}) 和 () 三个分组提取内容
即()|(MJ d{4})|(MJ d{4})|(d{2}.d{2}.d{4})
因为可能在日期之前存在空格或者横杠 所以我们用[- ]+来匹配
接下来我们用[- ]*(()|(MJ d{4})|(MJ d{4})|(d{2}.d{2}.d{4})) 来替换第一个左边的.*
得到^(?:<br>)+D([- ]*(()|(MJ d{4})|(d{2}.d{2}.d{4})))>>(.*)(?:<br>)+$
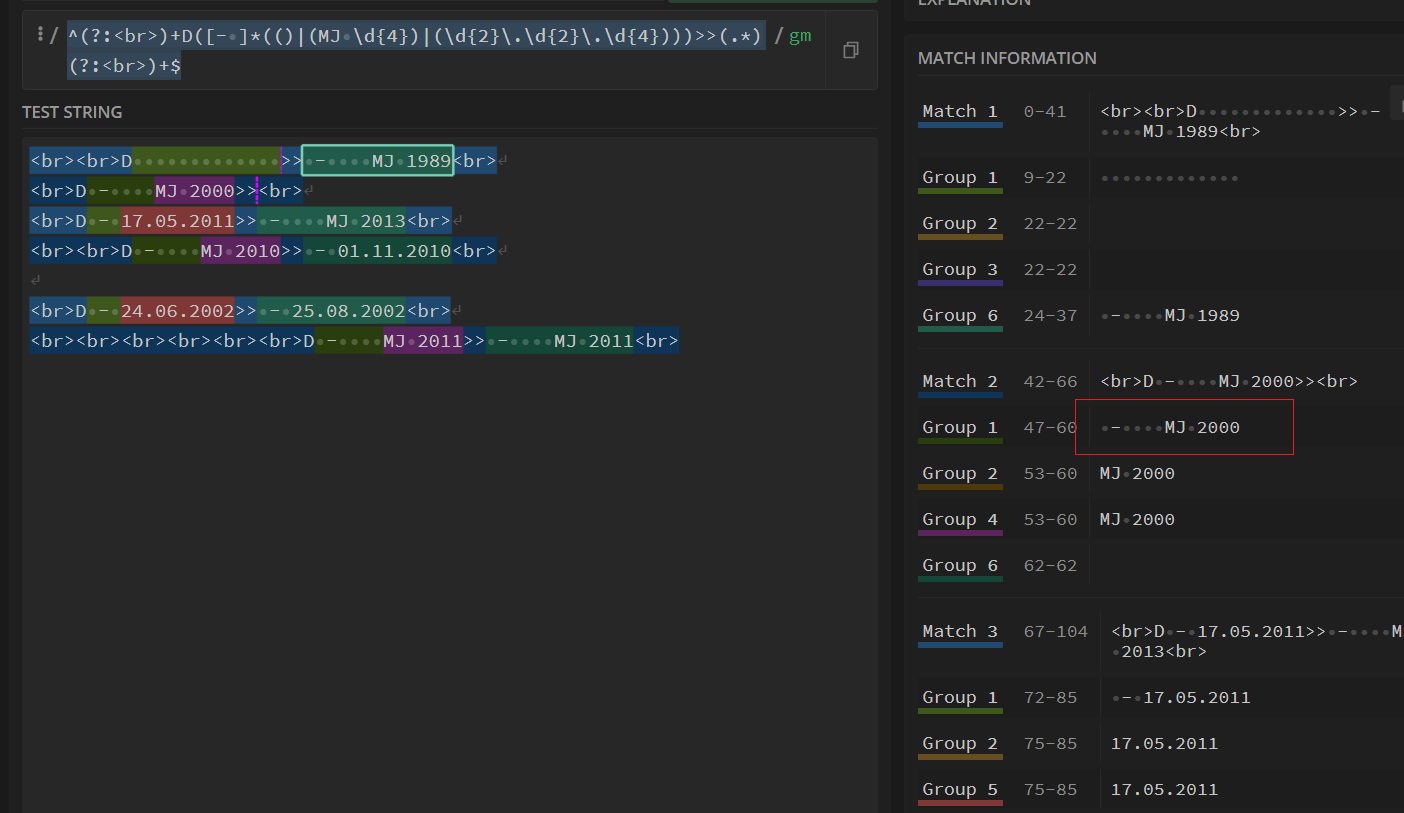
发现实际上再一次因为组的关系我们捕获了整串左边的文本,所以我们再次使用非捕获组来修复这个问题
^(?:<br>)+D(?:[- ]*(()|(MJ d{4})|(d{2}.d{2}.d{4})))>>(.*)(?:<br>)+$

我们又发现实际上分组1和分组2是相同的内容
这个地方有两种处理方式
第一种,将匹配每一种日期情况的分组去除或者改为非捕获组
^(?:<br>)+D(?:[- ]*(|MJ d{4}|d{2}.d{2}.d{4}))>>(.*)(?:<br>)+$
^(?:<br>)+D(?:[- ]*((?:)|(?:MJ d{4})|(?:d{2}.d{2}.d{4})))>>(.*)(?:<br>)+$
第二种,将包裹所有日期可能的分组改为非捕获组(这个地方可以思考测试一下为什么不能把这个分组去除
无论哪种情况 都可以得到这个结果
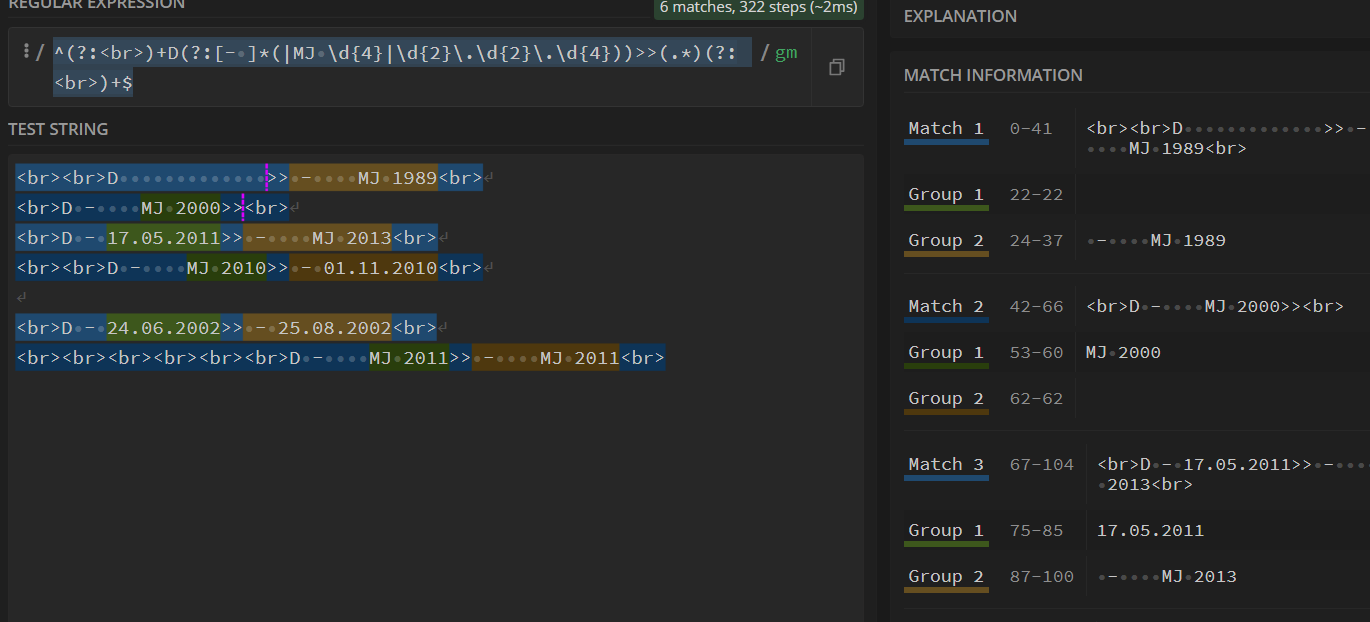
同理将左边的表达替换到右边 就可以得到最后的结果
^(?:<br>)+D(?:[- ]*(|MJ d{4}|d{2}.d{2}.d{4}))>>(?:[- ]*(|MJ d{4}|d{2}.d{2}.d{4}))(?:<br>)+$
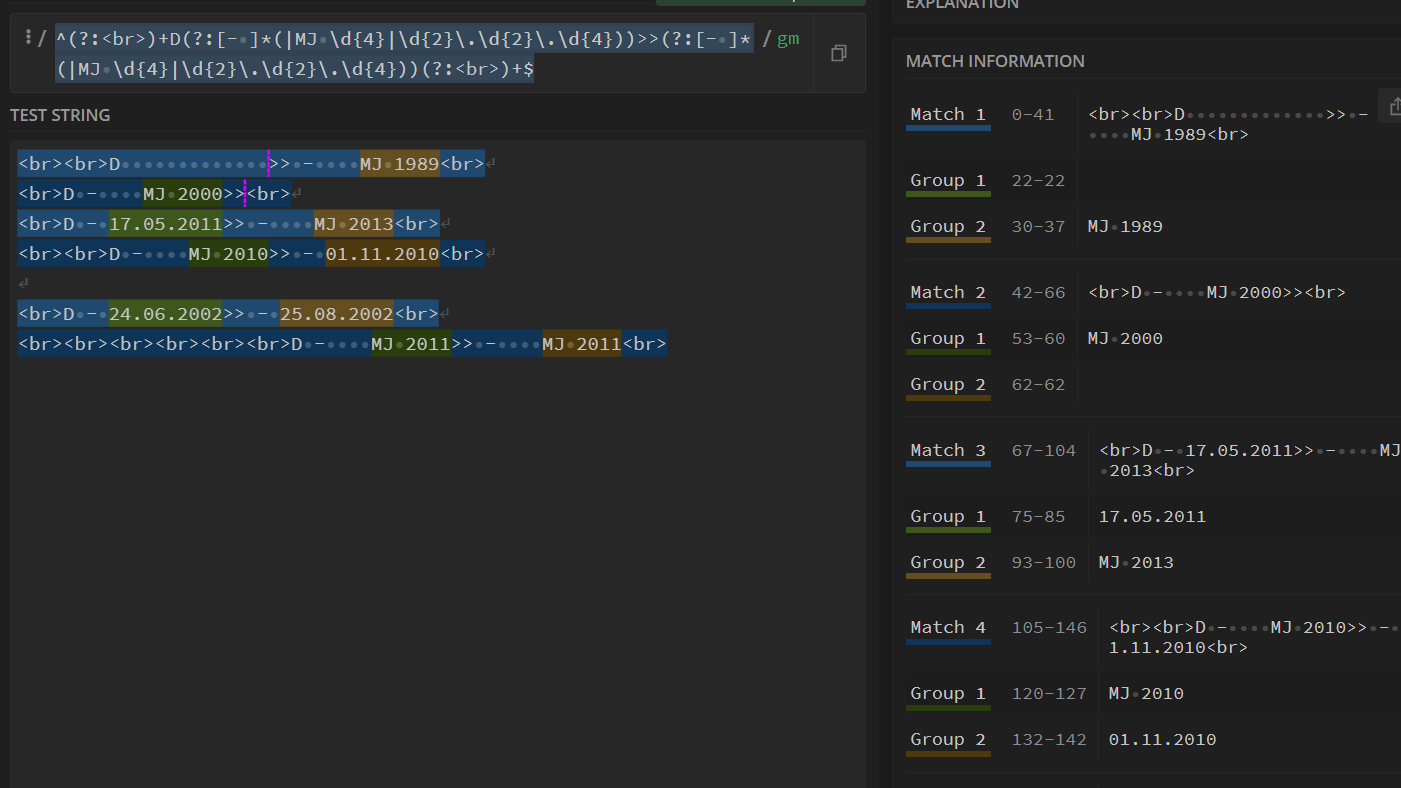
即分组1 是开始日期 分组2是结束日期
转载请注明出处 https://www.cnblogs.com/majianming/p/14590599.html
使用到的工具网址
https://regex101.com/