树的遍历也一直都是重点,主要是在建造了一棵树之后,如何将这棵树输出来确定创建的树是否正确就成了问题。网上现在也有很多的方法来输出树,python也有专门的包来可视化,不过今天主要总结最基础的遍历算法。
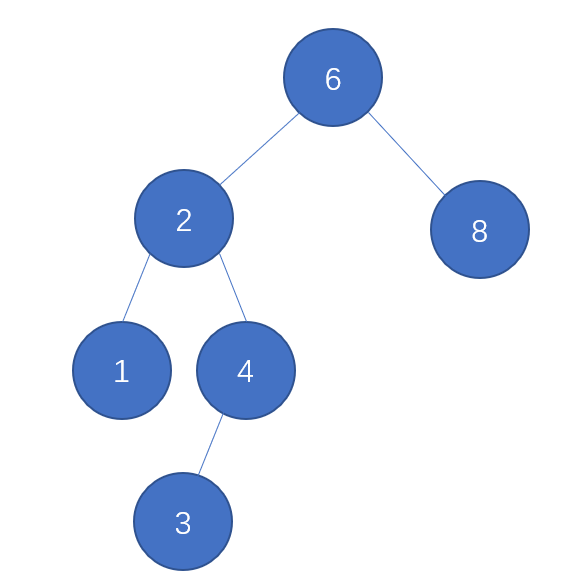
树的遍历主要根据访问根节点的时机来分为先序、中序、后序和层次遍历。其中要掌握了十种算法,分别是先序递归和先序非递归(深度优先搜索)、中序递归和中序非递归、后序递归和俩种后序非递归(单栈和双栈)、层次遍历(广度优先搜索),Morris遍历以及改善版。下面八种对图1的树进行遍历。
先序
首先访问根节点、然后访问左子树,最后访问右子树。如果用递归实现这个思想非常简单,代码如下
// 前序遍历,递归
private void printTree(TreeNode node) {
if(node != null) {
System.out.print(node.node_value + ", ");
// 访问左子树
printTree(node.left_node);
// 访问右子树
printTree(node.right_node);
}
}
对于非递归的思想,先来看一下对于图1中的先序遍历的过程,就是先访问根节点6,之后访问6的左子树,再访问左子树的根2,之后访问根2的左子树1,之后再访问根2的右子树的根4,再访问根4的左子树3,这时已经访问完根6的左子树,可以访问根6的右子树的根8。所以最后得到的顺序是6,2,1,4,3,8。
这时的过程有点类似DFS(深度优先搜索),都是一条路走到底,因此使用DFS来实现。其中使用到了栈来存储中间过程,主要注意的就是压入栈的顺序,是先将右节点压进去,再将左节点压进去,这时因为栈是先进后出。
// 深度遍历,使用的是栈,前序遍历得非递归实现
private void printTree(TreeNode node) {
Stack<TreeNode> tree_stack = new Stack<TreeNode>();
tree_stack.push(node);
while(!tree_stack.empty()) {
TreeNode stack_element = tree_stack.pop();
if(stack_element.right_node != null) tree_stack.push(stack_element.right_node);
if(stack_element.left_node != null) tree_stack.push(stack_element.left_node);
System.out.print(stack_element.node_value + ", ");
}
System.out.println();
}
中序
首先访问左子树,然后访问根节点,最后访问右子树。下面先用递归来实现中序算法。
// 中序遍历,递归
private void printTree(TreeNode node) {
if(node != null) {
printTree(node.left_node);
System.out.print(node.node_value + ", ");
printTree(node.right_node);
}
}
先来看看中序在具体树上是怎么遍历的,先访问根6的左子树,再访问左子树2的左子树1,访问完1,就是访问左子树根2,再访问左子树2的右子树,直接到2的右子树的左子树3,之后访问2的右子树的根4,这时根6的左子树已经全部访问完,可以访问根6,最后访问右子树8,最后遍历的顺序是1,2,3,4,6,8。
还是用栈这个结构,先将根压入栈中,然后不断地将左子树压进去,直到叶节点,之后可以对栈中的每个节点访问,访问完一个节点之后,再看这个节点是否有右子树,如果有,先压入栈中,再判断这个右子树是否有左子树,如果还有左子树,那么就一直压入栈中,如果没有左子树,那么继续取栈中的元素,之后再判断是否有右子树。如此过程,一直进行下去。整个过程就是判断这个节点是不是null,是的话,就拿栈中下一个节点,不是的话,就压入栈中,之后判断节点左子树是不是null。
// 中序遍历,非递归
// 思想就是用栈,先把当前节点的左子树压进去,之后拿出节点,再把右子树压进去
private void printTree(TreeNode node) {
Stack<TreeNode> tree_stack = new Stack<TreeNode>();
while(node != null || !tree_stack.empty()) {
// 判断节点是否存在,主要是为了判断左子树是不是存在
if(node != null) {
tree_stack.push(node);
node = node.left_node;
}else {
// 如果节点不存在,那么拿出栈中元素
TreeNode current_node = tree_stack.pop();
System.out.print(current_node.node_value + ", ");
node = current_node.right_node;
}
}
}
后序
首先访问左子树,之后访问右子树,最后访问根节点。用递归思想依旧很容易。
// 后序遍历,递归
private void printTree(TreeNode node) {
if(node != null) {
printTree(node.left_node);
printTree(node.right_node);
System.out.print(node.node_value + ", ");
}
}
先来看看后序具体的过程,先访问根6的左子树,再访问根6左子树的左子树1,访问完1之后,再看左子树2的右子树4,然后访问左子树2的右子树4的左子树3,访问完3之后,可以访问根4,然后就可以访问左子树的根2,这时根6的左子树全部访问完成,再访问根6的右子树8,最后访问根6,最后的访问顺序就是1,3,4,2,6,8。
后序非递归思想是当中最难的,这时因为根节点最后才能访问,如果我们根据中序非递归的写法来看后序非递归,那么最起码还得有一个标识,标记节点的右子树是否被访问了,左子树就不用标记,因为栈中拿出来的就是左子树。如果访问过了,那么可以拿出来,如果没有,那么将右子树压进入。这时右子树的访问在根节点之前,那么只有看前一个访问过的节点是不是当前根节点的右节点就行。
// 后序遍历,非递归
// 使用一个栈,外加一个标志,这个标志就是说明右子树是否被访问了。
private void printTree(TreeNode node) {
Stack<TreeNode> tree_stack = new Stack<TreeNode>();
// 标记右子树是否被访问
TreeNode previsited_node = null;
while(node != null || !tree_stack.empty()) {
if(node != null) {
tree_stack.push(node);
node = node.left_node;
}else {
TreeNode right_node = tree_stack.peek().right_node;
// 查看是否有右子树或者右子树是否被访问
if(right_node == null || right_node == previsited_node) {
TreeNode current_node = tree_stack.pop();
System.out.print(current_node.node_value + ", ");
previsited_node = current_node;
node = null;
}else {
// 处理右子树
node = right_node;
}
}
}
}
但是如果使用俩个栈的话,这个非递归算法的思想就可以很简单了,如果我们先将右子树压进去,再将左子树压进去,那么这个栈中就是后序遍历顺序。不过这需要俩个栈,一个栈保存结果,一个栈拿出压进去的节点,看这个节点是不是有左子树,有的话,压入俩个栈中。
// 后序遍历,非递归
// 使用双栈遍历,思想其实和中序递归差不多。
// 一个栈是保存全部数据的,一个栈是把数据拿出来,找到它的左子树的,找到之后全部放入输出栈中
private void printTree(TreeNode node) {
Stack<TreeNode> tree_stack = new Stack<TreeNode>();
Stack<TreeNode> output_stack = new Stack<TreeNode>();
while(node != null || !tree_stack.empty()) {
if(node != null) {
// 如果节点存在,那么压入俩个栈中
tree_stack.push(node);
output_stack.push(node);
node = node.right_node;
}else {
TreeNode current_node = tree_stack.pop();
node = current_node.left_node;
}
}
// 输出栈中的元素就是后序
while(!output_stack.empty()) {
TreeNode temp_node = output_stack.pop();
System.out.print(temp_node.node_value + ", ");
}
}
BFS(广度优先搜索)层次遍历
层次遍历就是一层一层的输出节点,按照从左往右的顺序进行输出,图1树中输出的顺序就是6,2,81,4,3,这种类似于广度优先搜索算法,那么需要的是队列结构,这里就是先进先出,就是先将根节点进队,之后从队中拿出节点,看这个节点是否有左节点和右节点,有的话,就进队,然后不断地对队列中的树进行判断进队就行,直到队列中没有节点。
// 广度层次遍历,使用的是队列
private void printTree(TreeNode node) {
Queue<TreeNode> tree_queue = new LinkedList<TreeNode>();
tree_queue.offer(node);
// 查看队列中是否还有节点
while(!tree_queue.isEmpty()) {
// 拿出队列中的节点
TreeNode queue_element = tree_queue.poll();
if(queue_element.left_node != null) tree_queue.offer(queue_element.left_node);
if(queue_element.right_node != null) tree_queue.offer(queue_element.right_node);
System.out.print(queue_element.node_value + ", ");
}
System.out.println();
}
Morris遍历(线索二叉树)
上面的遍历一般都是使用递归、栈或者队列实现的,空间复杂度和时间复杂度都是(O(n)),因为遍历的话,你肯定需要访问每个元素依次,那么时间复杂度最少就是(O(n)),能优化的也只是空间复杂度。之前都是使用数据结构存储还未访问的节点,如果我们不存储呢,每次访问一个节点时候,如果有左子树,直接找出直接前驱,这个前驱肯定是个叶子节点,没有右子树,将这个前驱节点的右节点与当前节点链接,形成线索二叉树那样的链接,之后去掉当前节点的左链接,那么是不是直接将树结构变成单链表结构,并且还是中序遍历,如果遍历的是BST树,那么遍历出来的是从小到大的顺序的。
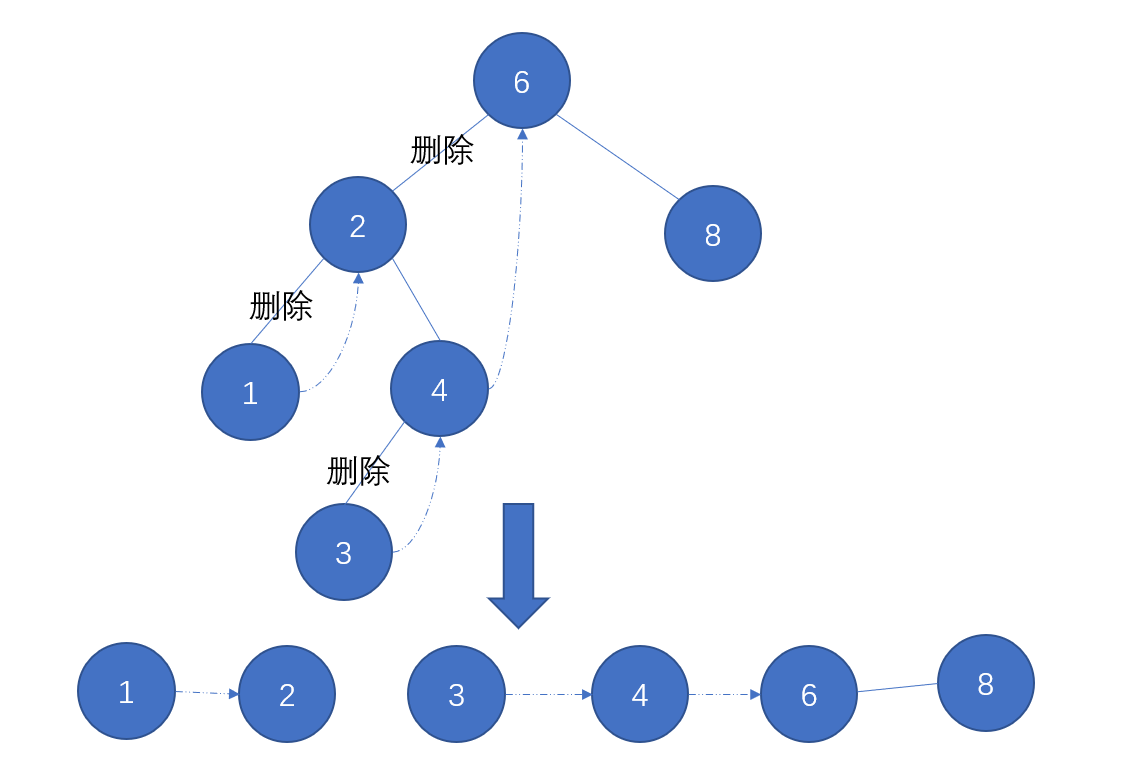
为了能够形象的展示遍历过程,将上面图的过程进行详细的表述:
- 节点6设置为当前节点;
- 查看节点6是否有左子树,发现有,那么找出左子树中的最右侧节点4,也就是当前节点的直接前驱,将最右侧节点4的右节点指向当前节点6;
- 将当前节点设置为节点6的左节点2,然后删除节点2和节点6的链接;
- 查看节点2是否有左子树,发现有,那么找出左子树中的最右侧节点1,将节点1的右节点指向当前节点2;
- 将当前节点设置为节点2的左节点1,然后删除节点2和节点1的链接;
- 查看节点1是否有左子树,发现当前节点1没有左子树,那么访问当前节点1,之后进入节点1的右链接中,到了节点2,节点2设置成当前节点;
- 查看当前节点2是否有左子树,发现没有,访问当前节点2,进入节点2的右子树中,到了节点4,将之设置成当前节点;
- 查看当前节点4是否有左子树,发现有,那么找出左子树中的最右侧节点3,将之右节点指向当前节点4;
- 将当前节点设置成节点4的左节点3,然后删除节点4和节点3的链接;
- 查看当前节点3是否有左子树,发现没有,访问当前节点3,之后进入节点3的右链接中,到了节点4,节点4设置成当前节点;
- 查看当前节点4是否有左子树,发现没有,访问当前节点4,之后进入节点4的右链接中,到了节点6,节点6设置成当前节点;
- 查看当前节点6是否有左子树,发现没有,访问当前节点6,之后进入节点6的右链接中,到了节点8,节点8设置成当前节点;
- 查看当前节点8是否有左子树,发现没有,访问当前节点8,之后进入节点6的右链接中,发现是null,那么退出循环;
// 使用线索二叉树的Morris遍历,但是会改变树的结构,直接变成单项升序链表形式
private void printTree(TreeNode node) {
TreeNode current_node = node;
while(current_node != null) {
// 左孩子不为空的话,就找到左子树的最右节点指向自己
if(current_node.left_node != null) {
TreeNode leftNode = current_node.left_node;
while(leftNode.right_node != null) {
leftNode = leftNode.right_node;
}
leftNode.right_node = current_node;
leftNode = current_node.left_node;
current_node.left_node = null;
current_node = leftNode;
}else {
System.out.print(current_node.node_value + ", ");
current_node = current_node.right_node;
}
}
}
上面最大的问题就是强行改变了树的结构,将之变成了单链表结构,这在实际应用中,往往是不可取的,但是在上面的程序中,是必须的,因为删除左孩子,是为了防止无限循环,因为判定条件都是节点是否有左孩子。我们加上一个条件来查看是否是第二次访问该节点。当查看当前节点是有左子树的时候,还要看直接前驱右链接是不是当前节点,如果是当前节点,那么删除直接前驱的右链接,并且将当前节点强制移动到右子树中。
// 上面那个会使得二叉树强行改变,不可取,因此有了这个。
private void printTree(TreeNode node) {
TreeNode current_node = node;
while(current_node != null) {
// 左孩子不为空的话,就找到左子树的最右节点指向自己
if(current_node.left_node == null) {
System.out.print(current_node.node_value + ", ");
current_node = current_node.right_node;
}else {
TreeNode leftNode = current_node.left_node;
while(leftNode.right_node != null && leftNode.right_node != current_node) {
leftNode = leftNode.right_node;
}
if(leftNode.right_node == null) {
leftNode.right_node = current_node;
current_node = current_node.left_node;
}else {
System.out.print(current_node.node_value + ", ");
leftNode.right_node = null;
current_node = current_node.right_node;
}
}
}
}
总结
其实这章我想等等再写,奈何在写BST树要输出,只好先把遍历这章全部写完,代码也和我得github中BST树的实现放在一起了。树遍历的算法很基础,但是也很重要,以前在本科时,都用C写过,奈何那时没有写博客的习惯,已经全部丢失,只好重新再写一边,就当复习。其中的非递归遍历算法都用到了栈这个数据结构,主要是因为遍历的特性,不过完全自己写的话,还真的很难写。