Word embeding
给word 加feature,用来区分word 之间的不同,或者识别word之间的相似性.

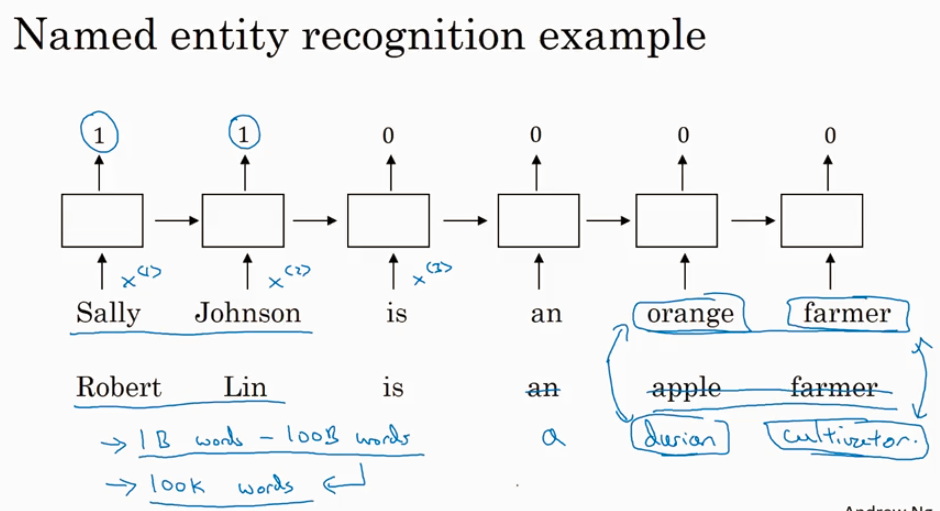
用于学习 Embeding matrix E 的数据集非常大,比如 1B - 100B 的word corpos. 所以即使你输入的是没见过的 durian cutivator 也知道和 orange farmer 很相近. 这是transfter learning 的一个case.


因为t-SNE 做了non-liner 的转化,所以在原来的300维空间的平行的向量在转化过后的2D空间里基本上不会再平行.

看两个向量的相似性,可以用cosine similarity.


说了这么久 word embeding E 有这么大的用处,那E是怎么得到的呢?下面讲怎么learn embeding.
Learning embedings:Word2Vec&GloVe
就是怎么得到 E。
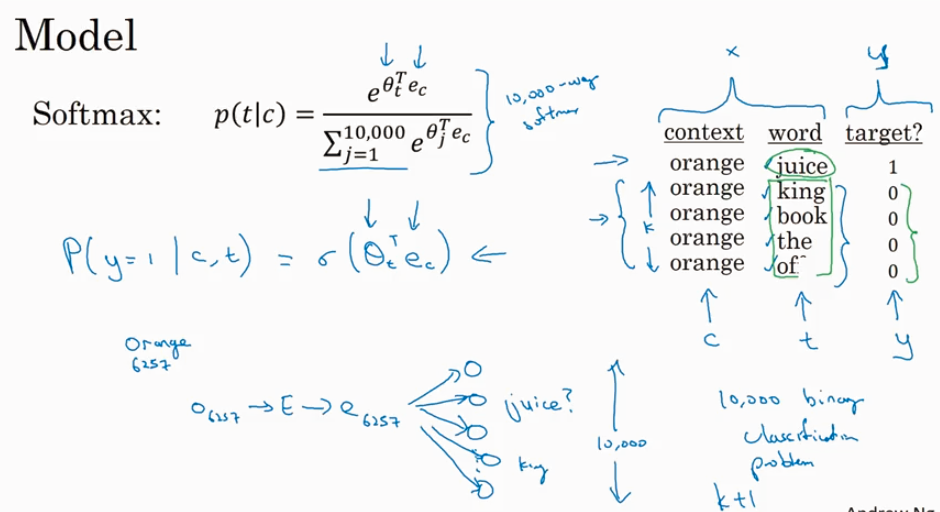
下图提到的在附近找一个词来做context 预测 target 词,就是Skip Gram 算法.
研究人员发现如果你真想要 build language model, 很自然的选择最近的一些words 作为context; 如果你是为了learn word embeding, 你可以选择任意下面的context都能得到很好的结果.

Word2Vec
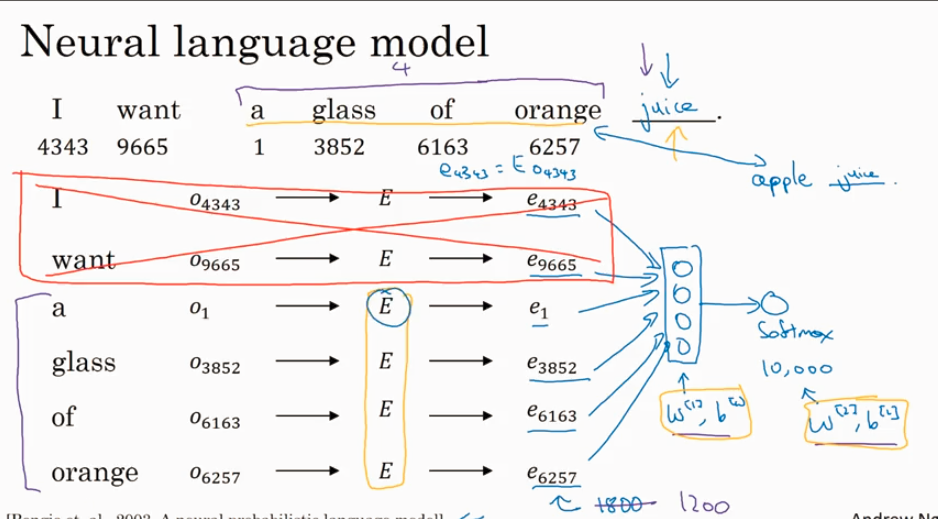
前面讲了使用前4个word来学习参数 E 进而预测target word, 这里讲用1个word 来学习E并用来预测target word. 下图就是Word2Vec 的 Skip-grams model,还有一个叫 CBow.
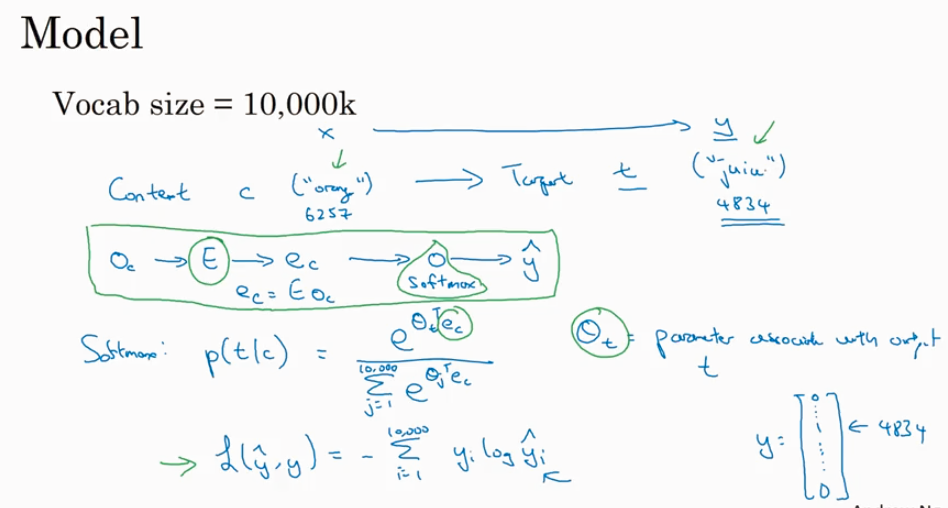
Word2Vec 最大的问题就是计算p(t|c) 时候计算量很大.下图提到了hierachial softmax 的概念是一个解决的思路.

接下里有两种算法来解决上面讲到的softmax计算量大的问题
Negagtive Sampling

这个negative sampling model 把一次性计算softmax (在我们的例子里softmax 输出的维度是10k), 改成了多(10k)次(1个positive example, 4个随机选取的negative example)计算sigmoid.
到底怎么随机选取negative sampling 呢?去绝对随机,还是有什么方法?有两种极端,一种是根据经验取常见的word, 还有一种是在vacab 里绝对的随机选取,都不好, 下面给出了一个经验公式.但是我没搞懂那个p(wi) 怎么用到实际的选取中.

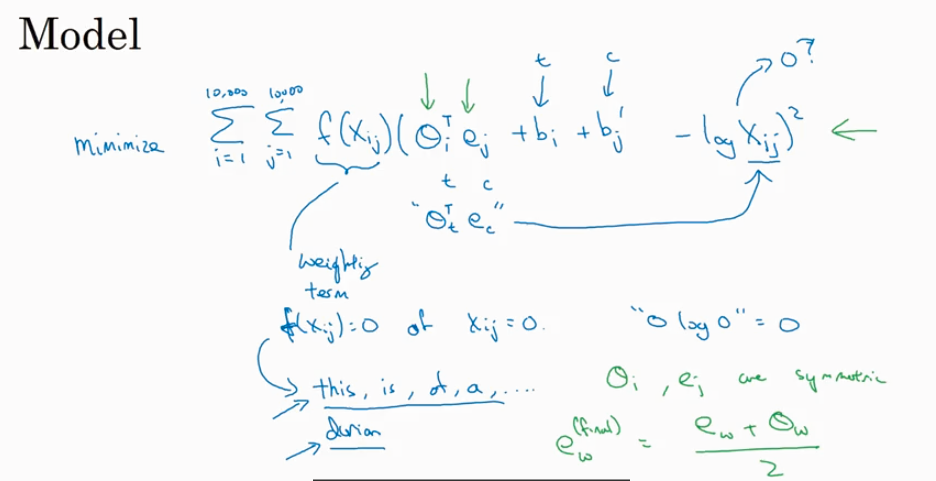
GloVe


Sentiment Classification
情感分析一个大问题是没有足够的label dataset.


Ref:
我觉得这个课程里面的 skip-gram 没有这个文章 讲得清楚