- 介绍了Spark中最重要的概念RDD
- 介绍了RDD的基本操作(Transformation & Action)
- 介绍了RDD的血缘关系(Lineage)
- 介绍了RDD的依赖类型(Narrow & Shuffle)
- 介绍了RDD的阶段(Stage)
- 介绍了RDD的缓存(Cache)
- 实战:Loading Data
- 实战:Hello World with Scala
Spark Core - RDD
Resilient Distributed Dataset 弹性分布式数据集
...collection of elements partitioned across the nodes of ther cluster that can be operated on in parallel...
RDD是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。它有以下特性:
- 只读:不能修改,只能通过转换操作生成新的 RDD。
- 分布式:可以分布在多台机器上进行并行处理。
- 弹性:计算过程中内存不够时它会和磁盘进行数据交换。
- 基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
理解:RDD是Spark中非常重要的一个抽象概念。我们可以这样理解:一个List,里面有许多Int类型数据,比如1000万条,现在要对其求平均值。于是我们把这个List分割成1000份,分别计算求和,然后再累加起来求平均。这个List就是RDD。
运用于之后的计算。
通过使用RDD,用户不必担心底层数据的分布式特性,只需要将具体的应用逻辑表达为一系列转换处理,就可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 I/O 和数据序列化的开销。
RDD - 基本操作
其实,RDD的操作和Java Stream API很像,后者也是类似地用pipeline进行map-reduce操作。如下:
someList.stream()
.filter(...) -- map
.collect(...); -- reduce
相应地,RDD也有类似的操作,称为Transformation和Action。
Transformation
- map
- filter
- ...
转化操作,就是从一个RDD产生一个新的RDD,但是这里不计算。
Action
- collect
- count
- reduce
- ...
行动操作,就是进行实际的计算。
RDD - 血缘关系
RDD的最重要的特性之一就是血缘关系(Lineage),它描述了一个RDD是如何从父RDD计算得来的。如果某个RDD丢失了,则可以根据血缘关系,从父RDD计算得来。
把这种关系画出来,就是DAG(direct acyclic graph),有向无环图。

RDD - 依赖类型
- 窄依赖 Narrow:父RDD的每个分区都只被子RDD的一个分区所使用
- 宽依赖 Shuffle:父RDD的每个分区都被多个子RDD的分区所依赖。
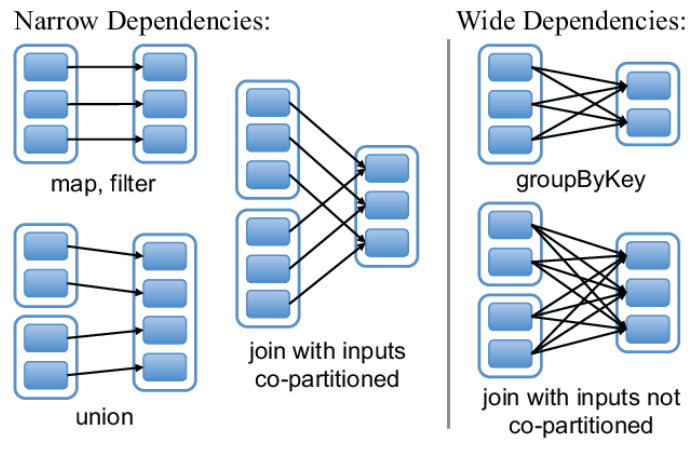
当处理数据时,
- 窄依赖 支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter
- 宽依赖 必须等RDD的parent partition数据全部ready之后才能开始计算
当需要失败恢复时
- 窄依赖 更为高效,它只需要根据父RDD分区重新计算丢失的分区即可
- 宽依赖 开销较大,需要重新计算父RDD的所有分区
从操作上来分
map,filter,union等操作是窄依赖groupByKey,reduceByKey等操作是宽依赖
RDD - 阶段
对于宽依赖,spark的设计是让parent RDD将结果写在本地,完全写完之后,通知后面的RDD。后面的RDD则首先去读之前的本地数据作为input,然后进行运算。
分为两个阶段(stage)去做:
- 第一个阶段(stage)需要把结果shuffle到本地,例如reduceByKey,首先要聚合某个key的所有记录,才能进行下一步的reduce计算,这个汇聚的过程就是shuffle
- 第二个阶段(stage)则读入数据进行处理。
同一个stage里面的task是可以并发执行的,下一个stage要等前一个stage ready
RDD - 缓存
Spark RDD是惰性求值的,而有时候希望能多次使用同一个RDD。如果简单地对RDD调用行动操作,Spark每次都会重算RDD及它的依赖,这样就会带来太大的消耗。为了避免多次计算同一个RDD,可以让Spark对数据进行持久化。
Spark可以使用persist和cache方法将任意RDD缓存到内存、磁盘文件系统中。
Exercise - Loading Data
有三种常见操作可以创建RDD,列举如下:
1.使用集合
这里主要使用了parallelize和makeRDD。
scala> val arr = Array(1,2,3)
scala> val rdd = sc.parallelize(arr)
scala> val rdd = sc.makeRDD(arr)
scala> rdd.collect
res0: Array[Int] = Array(1, 2, 3)
另外,parallelize还支持并行操作,通过传入参数,将dataset切分成n个partition,比如,sc.parallelize(data, 10))。
2.读取外部文件系统
这里主要使用了textFile。
scala> val rdd2 = sc.textFile("hdfs://hadoop01:9000/dummy.txt")
scala> val rdd2 = sc.textFile("file:////root/dummy.txt")
scala> rdd2.collect
res2: Array[String] = Array(a, b, c)
3.从父RDD转换成新的子RDD
这里主要使用了transformation类的方法/算子,如map, fliter等。
scala> rdd.collect
res3: Array[Int] = Array(1, 2, 3)
scala> val rdd = sc.parallelize(arr)
scala> val rdd2 = rdd.map(_*100)
scala> rdd2.collect
res4: Array[Int] = Array(100, 200, 300)
注:
- 调用transformation类的算子,都会生成一个新的RDD。RDD中的数据类型,由传入给算子的函数的返回值类型决定。
- 调用action类的算子,不会生成新的RDD。
Exercise - Spark with Scala
之前我们已经试过了在spark-shell里面使用命令行执行一些操作,下面试一下用project的形式运行。
主要需要准备两个文件,一是app文件。
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val spark = SparkSession.builder.appName("Simple Application").config("spark.master", "local").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}
二是build文件。这里用了sbt。
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.0.0"
当然也可以用maven,常用的dependency如下:
groupId = org.apache.spark
artifactId = spark-core_2.11
version = 2.1.1
groupId = org.apache.hadoop
artifactId = hadoop-client
version = <your-hdfs-version>
然后,就可以package + run。
# Package a jar containing your application
$ sbt package
...
[info] Packaging {..}/{..}/target/scala-2.12/simple-project_2.12-1.0.jar
# Use spark-submit to run your application
$ YOUR_SPARK_HOME/bin/spark-submit
--class "SimpleApp"
--master local[4]
target/scala-2.12/simple-project_2.12-1.0.jar
...
Lines with a: 46, Lines with b: 23