一、背景介绍
1. 使用工具
Pycharm
2. 安装的第三方库
requests、BeautifulSoup
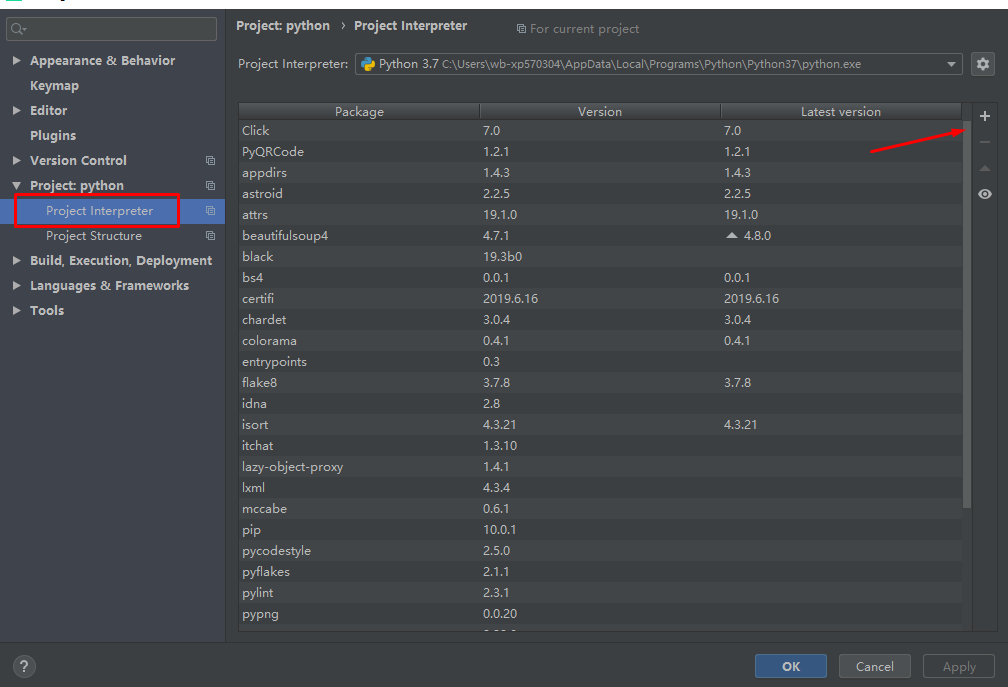
2.1 如何安装第三方库
File => Settings => Project Interpreter => + 中搜索你需要的插件
3. 可掌握的小知识
1. 根据url 获取页面html内容
2. 解析html内容,选出自己需要的内容
二、代码示例
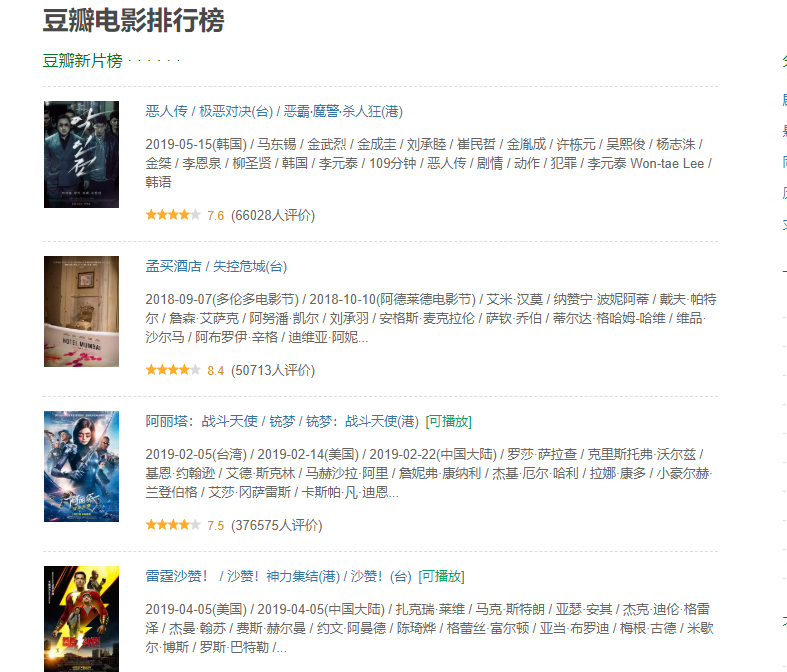
网页的样子是这个,获取排行榜中电影的名字
1 import requests 2 from bs4 import BeautifulSoup 3 4 def getHtml(): 5 url = 'https://movie.douban.com/chart' 6 # Get获取改页面的内容 7 html = requests.get(url) 8 # 用lxml解析器解析该页面的内容 9 soup = BeautifulSoup(html.content, "lxml") 10 getFilmName(soup) 11 # print(soup) 12 13 14 def getFilmName(html): 15 for i in html.find_all('a', class_="nbg"): 16 img = i.find('img') 17 print(img['alt']) 18 19 20 getHtml()
返回值:
恶人传
孟买酒店
阿丽塔:战斗天使
雷霆沙赞!
夏目友人帐
地久天长
调音师
三夫
寄生虫
地狱男爵:血皇后崛起
三、结语
先从简单的入手,帮助自己,也希望能帮助未入门的同学