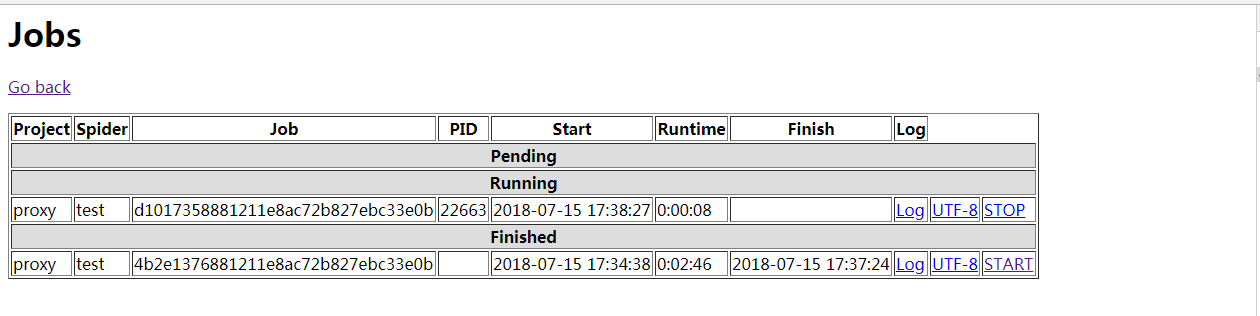
0.提出问题
Scrapyd 提供的开始和结束项目的API如下,参考 Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码,准备继续在页面上进一步添加 START 和 STOP 超链接。
http://scrapyd.readthedocs.io/en/stable/api.html#schedule-json
Example request:
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
Example response:
{"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"}
http://scrapyd.readthedocs.io/en/stable/api.html#cancel-json
Example request:
$ curl http://localhost:6800/cancel.json -d project=myproject -d job=6487ec79947edab326d6db28a2d86511e8247444
Example response:
{"status": "ok", "prevstate": "running"}
1.解决思路
尝试直接通过浏览器地址栏 GET 请求页面 http://localhost:6800/schedule.json?project=myproject&spider=somespider
返回提示需要使用 POST 请求
{"node_name": "pi-desktop", "status": "error", "message": "Expected one of [b'HEAD', b'object', b'POST']"}
那就继续通过 URL 查询对传参,通过 JS 发起 POST 异步请求吧
2.修改 Scrapyd 代码
/site-packages/scrapyd/website.py
改动位置:
(1) table 添加最后两列,分别用于 UTF-8 和 STOP/START 超链接,见红色代码
def render(self, txrequest): cols = 10 ######## 8 s = "<html><head><meta charset='UTF-8'><title>Scrapyd</title></head>" s += "<body>" s += "<h1>Jobs</h1>" s += "<p><a href='..'>Go back</a></p>" s += "<table border='1'>" s += "<tr><th>Project</th><th>Spider</th><th>Job</th><th>PID</th><th>Start</th><th>Runtime</th><th>Finish</th><th>Log</th>" if self.local_items: s += "<th>Items</th>" #cols = 9 ######## cols += 1 ########
(2) 有两处需要添加 UTF-8 超链接,分别对应 Running 和 Finished,见红色代码
前面 Running 部分添加 UTF-8 超链接后继续添加 STOP 超链接,见蓝色代码
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job) s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ######## s += "<td><a href='/logs/scrapyd.html?opt=cancel&project=%s&job_or_spider=%s' target='_blank'>STOP</a></td>" % (p.project, p.job) ########
后面 Finished 部分添加 UTF-8 超链接后继续添加 START 超链接,见蓝色代码
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job) s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ######## s += "<td><a href='/logs/scrapyd.html?opt=schedule&project=%s&job_or_spider=%s' target='_blank'>START</a></td>" % (p.project, p.spider) ########
(3) 完整代码


from datetime import datetime import socket from twisted.web import resource, static from twisted.application.service import IServiceCollection from scrapy.utils.misc import load_object from .interfaces import IPoller, IEggStorage, ISpiderScheduler from six.moves.urllib.parse import urlparse class Root(resource.Resource): def __init__(self, config, app): resource.Resource.__init__(self) self.debug = config.getboolean('debug', False) self.runner = config.get('runner') logsdir = config.get('logs_dir') itemsdir = config.get('items_dir') local_items = itemsdir and (urlparse(itemsdir).scheme.lower() in ['', 'file']) self.app = app self.nodename = config.get('node_name', socket.gethostname()) self.putChild(b'', Home(self, local_items)) if logsdir: self.putChild(b'logs', static.File(logsdir.encode('ascii', 'ignore'), 'text/plain')) if local_items: self.putChild(b'items', static.File(itemsdir, 'text/plain')) self.putChild(b'jobs', Jobs(self, local_items)) services = config.items('services', ()) for servName, servClsName in services: servCls = load_object(servClsName) self.putChild(servName.encode('utf-8'), servCls(self)) self.update_projects() def update_projects(self): self.poller.update_projects() self.scheduler.update_projects() @property def launcher(self): app = IServiceCollection(self.app, self.app) return app.getServiceNamed('launcher') @property def scheduler(self): return self.app.getComponent(ISpiderScheduler) @property def eggstorage(self): return self.app.getComponent(IEggStorage) @property def poller(self): return self.app.getComponent(IPoller) class Home(resource.Resource): def __init__(self, root, local_items): resource.Resource.__init__(self) self.root = root self.local_items = local_items def render_GET(self, txrequest): vars = { 'projects': ', '.join(self.root.scheduler.list_projects()) } s = """ <html> <head><meta charset='UTF-8'><title>Scrapyd</title></head> <body> <h1>Scrapyd</h1> <p>Available projects: <b>%(projects)s</b></p> <ul> <li><a href="/jobs">Jobs</a></li> """ % vars if self.local_items: s += '<li><a href="/items/">Items</a></li>' s += """ <li><a href="/logs/">Logs</a></li> <li><a href="http://scrapyd.readthedocs.org/en/latest/">Documentation</a></li> </ul> <h2>How to schedule a spider?</h2> <p>To schedule a spider you need to use the API (this web UI is only for monitoring)</p> <p>Example using <a href="http://curl.haxx.se/">curl</a>:</p> <p><code>curl http://localhost:6800/schedule.json -d project=default -d spider=somespider</code></p> <p>For more information about the API, see the <a href="http://scrapyd.readthedocs.org/en/latest/">Scrapyd documentation</a></p> </body> </html> """ % vars return s.encode('utf-8') class Jobs(resource.Resource): def __init__(self, root, local_items): resource.Resource.__init__(self) self.root = root self.local_items = local_items def render(self, txrequest): cols = 10 ######## 8 s = "<html><head><meta charset='UTF-8'><title>Scrapyd</title></head>" s += "<body>" s += "<h1>Jobs</h1>" s += "<p><a href='..'>Go back</a></p>" s += "<table border='1'>" s += "<tr><th>Project</th><th>Spider</th><th>Job</th><th>PID</th><th>Start</th><th>Runtime</th><th>Finish</th><th>Log</th>" if self.local_items: s += "<th>Items</th>" #cols = 9 ######## cols += 1 ######## s += "</tr>" s += "<tr><th colspan='%s' style='background-color: #ddd'>Pending</th></tr>" % cols for project, queue in self.root.poller.queues.items(): for m in queue.list(): s += "<tr>" s += "<td>%s</td>" % project s += "<td>%s</td>" % str(m['name']) s += "<td>%s</td>" % str(m['_job']) s += "</tr>" s += "<tr><th colspan='%s' style='background-color: #ddd'>Running</th></tr>" % cols for p in self.root.launcher.processes.values(): s += "<tr>" for a in ['project', 'spider', 'job', 'pid']: s += "<td>%s</td>" % getattr(p, a) s += "<td>%s</td>" % p.start_time.replace(microsecond=0) s += "<td>%s</td>" % (datetime.now().replace(microsecond=0) - p.start_time.replace(microsecond=0)) s += "<td></td>" s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job) s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ######## s += "<td><a href='/logs/scrapyd.html?opt=cancel&project=%s&job_or_spider=%s' target='_blank'>STOP</a></td>" % (p.project, p.job) ######## if self.local_items: s += "<td><a href='/items/%s/%s/%s.jl'>Items</a></td>" % (p.project, p.spider, p.job) s += "</tr>" s += "<tr><th colspan='%s' style='background-color: #ddd'>Finished</th></tr>" % cols for p in self.root.launcher.finished: s += "<tr>" for a in ['project', 'spider', 'job']: s += "<td>%s</td>" % getattr(p, a) s += "<td></td>" s += "<td>%s</td>" % p.start_time.replace(microsecond=0) s += "<td>%s</td>" % (p.end_time.replace(microsecond=0) - p.start_time.replace(microsecond=0)) s += "<td>%s</td>" % p.end_time.replace(microsecond=0) s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job) s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ######## s += "<td><a href='/logs/scrapyd.html?opt=schedule&project=%s&job_or_spider=%s' target='_blank'>START</a></td>" % (p.project, p.spider) ######## if self.local_items: s += "<td><a href='/items/%s/%s/%s.jl'>Items</a></td>" % (p.project, p.spider, p.job) s += "</tr>" s += "</table>" s += "</body>" s += "</html>" txrequest.setHeader('Content-Type', 'text/html; charset=utf-8') txrequest.setHeader('Content-Length', len(s)) return s.encode('utf-8')
3.新建 scrapyd.html
根据 http://scrapyd.readthedocs.io/en/stable/config.html 确定 Scrapyd 所使用的 logs_dir,在该目录下添加如下文件
<html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>scrapyd</title> </head> <body> <p>仅用于内网环境下执行 scrapyd API</p> <div id="result"></div> <script> function parseQueryString(url) { var urlParams = {}; url.replace( new RegExp("([^?=&]+)(=([^&]*))?", "g"), function($0, $1, $2, $3) { urlParams[$1] = $3; } ); return urlParams; } function curl(opt, project, job_or_spider) { console.log(opt); console.log(project); console.log(job_or_spider); var formdata = new FormData(); formdata.append('project', project); if(opt == 'cancel') { formdata.append('job', job_or_spider); } else { formdata.append('spider', job_or_spider); } var req = new XMLHttpRequest(); req.onreadystatechange = function() { if (this.readyState == 4) { if (this.status == 200) { document.querySelector('#result').innerHTML = this.responseText; } else { alert('status code: ' + this.status); } } else { document.querySelector('#result').innerHTML = this.readyState; } }; req.open('post', window.location.protocol+'//'+window.location.host+'/'+opt+'.json', Async = true); req.send(formdata); } var kwargs = parseQueryString(location.search); if (kwargs.opt == 'cancel' || kwargs.opt == 'schedule') { curl(kwargs.opt, kwargs.project, kwargs.job_or_spider); } </script> </body> </html>
4.实现效果
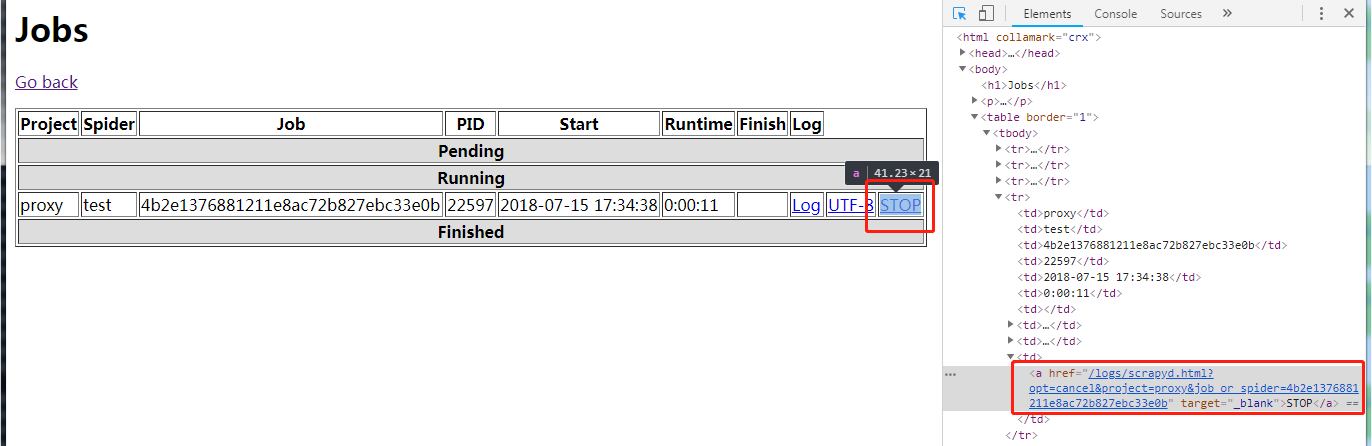
(1) 点击 STOP 超链接

(2) 返回 Jobs 页面
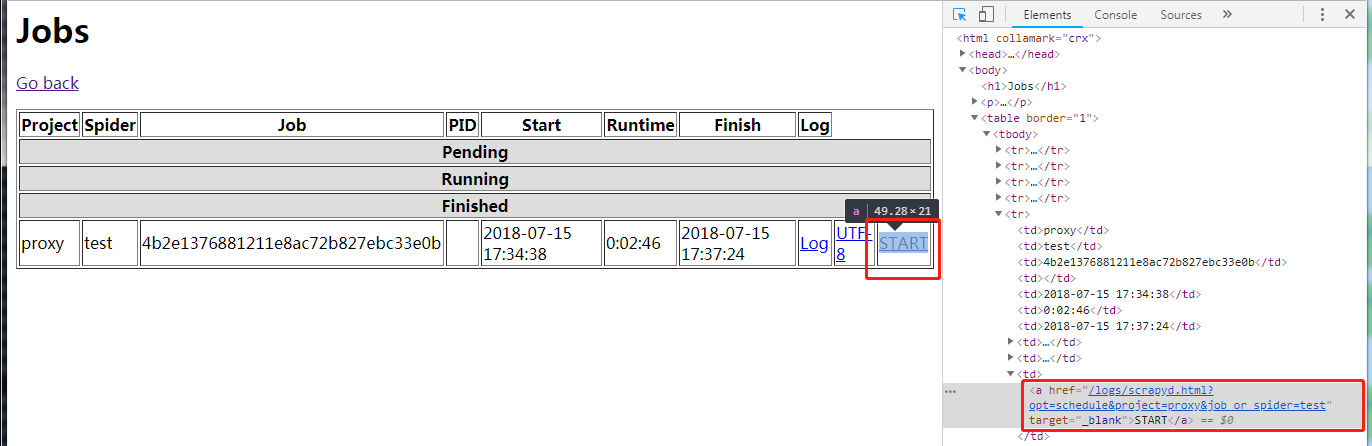
(3) 点击 START 超链接

(4) 返回 Jobs 页面