'''******************导入数据包*********************************'''
import pandas as pd
import numpy as np
import random
from sklearn import preprocessing
'''***************导入数据与数据处理*****************************'''
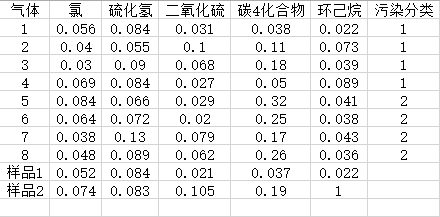
address = 'F:/python code/network_perceotron/basedata.csv'
file = pd.read_csv(address,encoding='GBK',header=None)
data = np.array(file)
data = data[1:9,1:6]
data = np.array(data,dtype=float)
add = np.ones(8)
x_train = np.column_stack((data,add))
x_train = preprocessing.scale(x_train)
'''********************封装感知器*********************************'''
class perceptron:
# 初始化参数
def __init__(self):
self.X = x_train
self.W = np.zeros(6).reshape(6,1)
# 预测
def predict(self,W,X):
z = np.tanh(np.dot(X,W))
return z
# 计算误差
def loss(self,label,z):
label = y_train
output = z
error = label - output
return error
# 更新权重
def update(self,W,X,error):
lr = np.random.rand()
self.W += lr*(np.dot(X.T,error))
return W
'''***************************训练数据***************************************'''
net = perceptron()
W = net.W
X = net.X
y_train = np.array([-1,-1,-1,-1,1,1,1,1]).reshape(8,1)
itr_num = int(input("请输入迭代次数:"))
for i in range(itr_num):
# 预测
y = net.predict(W,X)
# 计算损失
los = net.loss(y_train,y)
# 更新权重
W = net.update(W,X,los)
'''**************************——————测试————**********************************'''
# 输入测试数据集
X_test = np.array([[0.052,0.084,0.021,0.037,0.022,1],
[0.074,0.083,0.105,0.19,1,1]])
# 预处理数据
X_test = preprocessing.scale(X_test)
W_best = W
prdit_y = net.predict(W_best,X_test)
print(prdit_y)
数据集