文件处理
一、文件读写的读书笔记
(1)文件概述
文件包括两种类型:文本文件和二进制文件。
二进制文件直接由比特0和比特1组成,没有统一字符编码,文件内部数据的组织格式与文件用途有关。二进制文件和文本文件最主要的区别在于是否有统一的字符编码 无论文件创建为文本文件或者二进制文件,都可以用“文本文件方式”和“二进制文件方式”打开,打开后的操作不同。
textFile = open("7.1.txt","rt") #t表示文本文件方式 print(textFile.readline()) textFile.close() binFile = open("7-1.txt","rb") #r表示二进制文件方式 print(binFile.readline()) binFile.close()
输出结果为:
>>> 中国是个伟大的国家!
b'xd6xd0xb9xfaxcaxc7xb8xf6xcexb0xb4xf3xb5xc4xb9xfaxbcxd2xa3xa1'
(2)文件的打开与关闭
Python对文本文件和二进制文件采用统一的操作步骤,即“打开-操作-关闭”
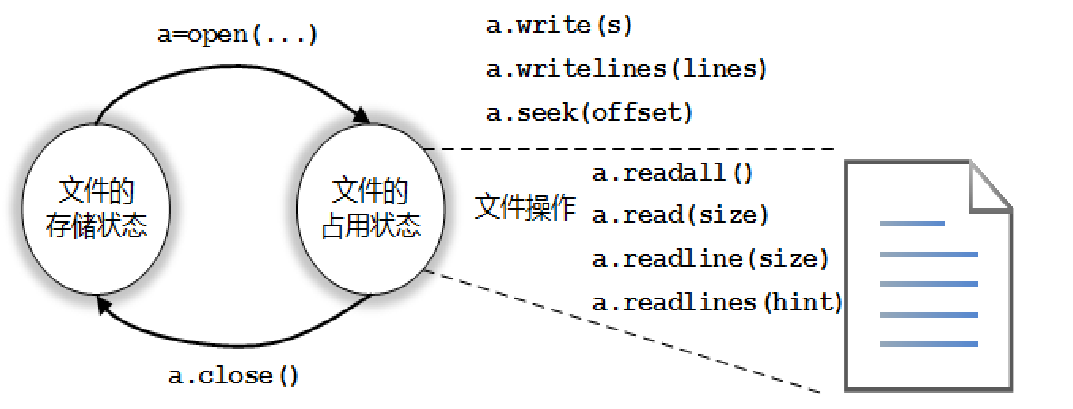
Python通过解释器内置的open()函数打开一个文件,并实现该文件与一个程序变量的关联,open()函数格式如下:
<变量名> = open(<文件名>, <打开模式>)
>>> f = open('test.txt', 'r')
r表示是文本文件,rb是二进制文件。(这个mode参数默认值就是r)
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
open()函数有两个参数:文件名和打开模式。文件名可以是文件的实际名字,也可以是包含完整路径的名字
open()函数提供7种基本的打开模式:

根据打开方式不同可以对文件进行相应的读写操作,Python提供4个常用的文件内容读取方法

- read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。如果文件大于可用内存,为了保险起见,可以反复调用
read(size)方法,每次最多读取size个字节的内容。 - readlines() 之间的差异是后者一次读取整个文件,象 .read() 一样。.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。
- readline() 每次只读取一行,通常比readlines() 慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用 readline()。
注意:以上三种方法会把每行末尾的' '读进来,它并不会默认的把' '去掉,需要我们手动去掉。
In[2]: with open('test1.txt', 'r') as f1:
list1 = f1.readlines()
In[3]: list1
Out[3]: ['111
', '222
', '333
', '444
', '555
', '666
']
去掉' '

In[4]: with open('test1.txt', 'r') as f1:
list1 = f1.readlines()
for i in range(0, len(list1)):
list1[i] = list1[i].rstrip('
')
In[5]: list1
Out[5]: ['111', '222', '333', '444', '555', '666']
对于read()和readline()也是把' '读入了,但是print的时候可以正常显示(因为print里的' '被认为是换行的意思)
例:文本文件逐行打印
fname = input("请输入要打开的文件: ")
fo = open(fname, "r")
for line in fo.readlines():
print(line)
fo.close()
遍历文件的所有行
fname = input("请输入要打开的文件: ")
fo = open(fname, "r")
for line in fo:
print(line)
fo.close()
如果程序需要逐行处理文件内容,建议采用上述代码格式:
fo = open(fname, "r")
for line in fo: # 处理一行数据
fo.close()
(3)文件的读写
Python提供3个与文件内容写入有关的方法,如表所示。

写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
>>> f = open('test.txt', 'w') # 若是'wb'就表示写二进制文件
>>> f.write('Hello, world!')
>>> f.close()
注意:'w'模式:如果没有这个文件,就创建一个;如果有,那么就会先把原文件的内容清空再写入新的东西。所以若不想清空原来的内容而是直接在后面追加新的内容,就用'a'这个模式。
我们可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('test.txt', 'w') as f:
f.write('Hello, world!')
- write()方法和read()、readline()方法对应,是将字符串写入到文件中。
- writelines()方法和readlines()方法对应,也是针对列表的操作。它接收一个字符串列表作为参数,将他们写入到文件中,换行符不会自动的加入,因此,需要显式的加入换行符。
f1 = open('test1.txt', 'w')
f1.writelines(["1", "2", "3"])
# 此时test1.txt的内容为:123
f1 = open('test1.txt', 'w')
f1.writelines(["1
", "2
", "3
"])
# 此时test1.txt的内容为:
# 1
# 2
# 3
例:文件的读写
fname = input("请输入要写入的文件: ")
fo = open(fname, "w+")
ls = ["唐诗", "宋词", "元曲"]
fo.writelines(ls)
for line in fo:
print(line)
fo.close()
程序执行结果如下:
>>>请输入要写入的文件:
test.txt >>>
文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
>>> f.close()
下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 |
关闭文件。关闭后文件不能再进行读写操作。 |
| 2 |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 |
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 |
如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 |
返回文件下一行。 |
| 6 |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 |
读取整行,包括 " " 字符。 |
| 8 |
读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| 9 |
设置文件当前位置 |
| 10 |
返回文件当前位置。 |
| 11 |
截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 |
将字符串写入文件,返回的是写入的字符长度。 |
| 13 |
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
二、读excel文件,存为csv格式,并把优秀变为90分,良好80分,合格60分,不合格0分。
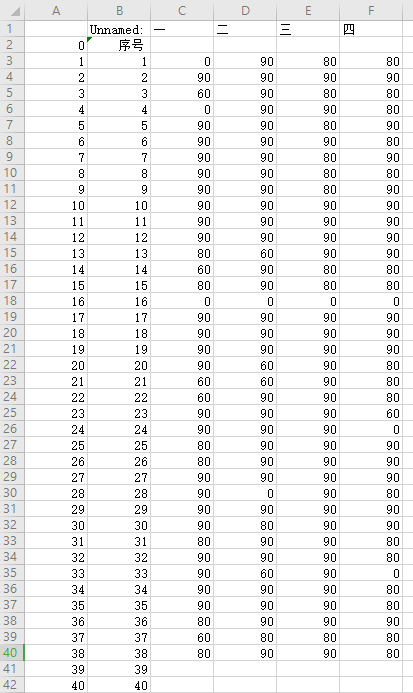
excel文件为

import pandas as pd df = pd.read_excel('file:Python成绩登记信计.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据 print(df) df1=df[:] df1['一']=df1['一'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['二']=df1['二'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['三']=df1['三'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['四']=df1['四'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1.to_csv('C:/Users\86134\.spyder-py3\成绩表.csv')
运行结果:
三、python123公开课
Python语言程序设计 (第11期)

19信计2班级《Python语言程序设计》

四、把第二题的csv文件转为html文件
import pandas as pd df = pd.read_excel('file:Python成绩登记信计.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据 print(df) df1=df[:] df1['一']=df1['一'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['二']=df1['二'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['三']=df1['三'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['四']=df1['四'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1.to_csv('C:/Users\86134\.spyder-py3\成绩表1.html')
运行结果:

file:///C:/Users/86134/.spyder-py3/%E6%88%90%E7%BB%A9%E8%A1%A81.html