理解reduceByKey操作,有助于理解Shuffle
reduceByKey
reduceByKey操作将map中的有相同key的value值进行合并,但是map中的数据键值对,并不一定分布在相同的partition中,甚至相同的机器中。
所以需要将数据取到相同的主机进行计算-同地协作。
单一task操作在单一partition上,为了组织所有数据进行单一的redueceByKey reduce 任务执行,Spark需要完成all-to-all(多对多)操作,所以必须在所有partitions中寻找所有values为了所有keys。
然后将每一个key对应的值从不同的partitions中放到一起进行最终的计算。这就是Shuffle.
Shuffle
1、数据完整性
2、网络IO消耗
3、磁盘IO消耗
回顾MapReduce的shuffle
MapReduce的shuffle操作

Shuffle阶段在map函数的输出到reduce函数的输入,都是shuffle阶段,
Split与block的对应关系可能是多对一,默认是一对一。每个map任务会处理一个split,如果block大和split相同,有多少个block就有多少个map任务,hadoop的2.*版本中一个block默认128M。

Map阶段的shuffle操作:

得到map的输出,然后进行分区,默认的分区规则:key值计算hash然后对应reduce个数取模;分区个数与reduce个数一致
map分区后的结果会放入到内存的环形缓冲区,它的默认大小是100M,配置信息是mapreduce.task.io.sort.mb,当缓冲区的大小使用超过一定的阀值(mapred-site.xml:mapreduce.map.sort.spill.percent,默认80%),一个后台的线程就会启动把缓冲区中的数据溢写(spill)到本地磁盘中(mapred-site.xml:mapreduce.cluster.local.dir),与此同时Mapper继续向环形缓冲区中写入数据。
环形缓冲区将数据溢写到磁盘,在溢写过程中对数据进行sort和Combiner,排序默认是针对key进行排序,combiner如果指定是优化的一种,类似将reduce的操作在map端进行,避免多余数据的传输,比如在分区中有3个("Hadoop",1),可将数据进行合并("Hadoop",3)。溢写到磁盘小文件大小为80M。
然后将多个小文件合并成一个大文件,在这个过程中,还是会进行sort和combiner,因为即使小文件的内容是已经排序的,合并以后数据也还是需要排序的。不然数据还是无序的。
Reduce阶段的shuffle操作:
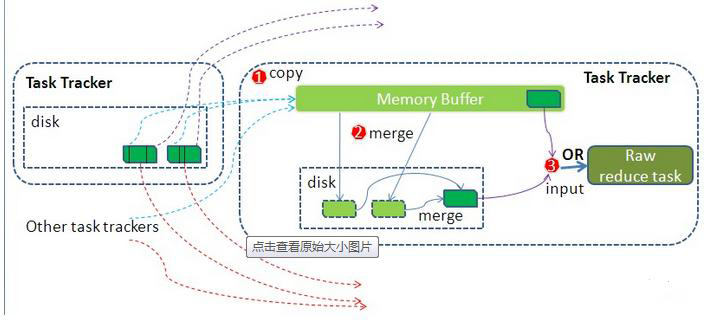
Reduce从Task Tracker中取数据,使用http协议取数据,copy过来的数据放入到内存缓存区中,这里的内存缓冲区的大小为JVM的heap大小。
然后对数据进行merge,这里的merge也会进行sort和combiner,如果设置了combiner。merge也会进行默认的分组,将key进行分组。
Spark Shuffle
HashBaseShuffle
缺点:小文件过多,数量为task*reduce的数量
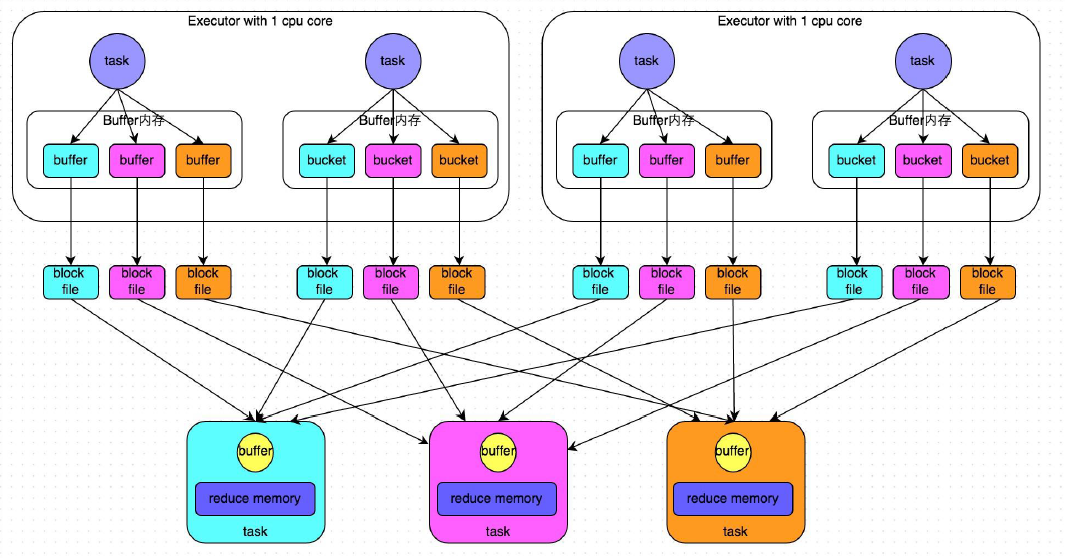
数据到内存buffer是进行partition操作,对key求hash然后根据reduce数量取模。buffer的大小不大32k,不是很大,buffer的数据会随时写到block file,这个过程没有sort。
reduce端通过netty传输来取数据,然后将数据放到内存。通过hashmap存储。
优化:使用spark.shuffle.consolidateFiles机制,修改值为true,默认为false,没有启用。
文件数量为:reduce*core
在一个core里面并行运行的task其中生成的文件数为reduce的个数。一个core里面并行运行的task,将数据都追加到一起。

SortBaseShuffle
现在默认的shuflle为SortBaseShuffle
自带consolidateFiles机制
自带sort

不用sort排序可以通过配置实现
1、spark.shuffle.sort.bypassMergeThreshold 默认值为200 ,如果shuffle read task的数量小于这个阀值200,则不会进行排序。
2、或者使用hashbasedshuffle + consolidateFiles 机制
修改shuffle方法:
spark.shuffle.manager 默认值:sort
有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。tungsten-sort慎用,存在bug.

参考:http://langyu.iteye.com/blog/992916