多任务:
多任务就是可以让一台电脑同时执行多个命令,多个CPU一起执行
以前的单核cpu是怎么做到同时执行多个命令的?(时间片轮转)
——其实以前的单核CPU是让操作系统交替执行命令,每个任务执行0.01秒,这样看起来就像是在同时执行多个命令。就跟手翻动画一样。这就是并发
所以:并行是真的多任务;并发是假的多任务
线程:
使用:
1.创建对象 t1 = threading.Thread(target = sing) 应该把函数名sing给target,不能用sing(),sing()表示调用函数
2.创建线程 t1.start()
threading.enumerate() 用来获取当前所有的线程(得到的好像是对象)
线程的运行是没有先后顺序的,如果子线程没有延时,很快就执行完,那么当你调用时,获得的列表只有主线程
PS:在创建对象时 线程没有创建,当调用 xx.start() 时线程才创建并开始执行
知识点:
1.一个程序运行,一定有一个执行代码的东西,这个东西称作 《线程》
2.就像光标一行一行的往下移动,执行每一行代码,而多个线程,就会出现多个光标,分为主线程和子线程
3.当主线程执行完所有代码,就要等子线程,当子线程执行完,主线程才能结束(帮子线程处理垃圾)。只有主线程结束,程序才结束。不是程序结束,主线程才结束。
4.当调用的方法比较复杂时,可以把他封装成类,start会自动调用run方法,然后在run里面调用类里面的其他方法
xx.start()只创建了一个线程,执行 run() 如果里面有其他方法,在run()里调用
例子:


1 import time 2 import threading 3 4 class MyThread(threading.Thread): 5 def run(self): 6 self.sing() 7 self.dance() 8 9 def sing(self): 10 '''唱歌''' 11 for i in range(5): 12 print('正在唱歌') 13 time.sleep(1) 14 def dance(self): 15 '''跳舞''' 16 for i in range(5): 17 print('正在跳舞') 18 time.sleep(1) 19 20 def main(): 21 t = MyThread() 22 t.start() 23 24 if __name__ == '__main__': 25 main()
5.多线程的全局变量是共享的(03py),因为多线程一般是配合使用,如果不共享,那么就要等到一个线程执行完,再把变量传递给另一个线程,就变成单线程了
即:你在一个函数中设定变量x并加一,另一个函数打印变量x,当使用线程执行两个函数时,打印结果为加一后的变量
6.但是如果多个线程同时需要修改一个全局变量,就会出现资源竞争,如果变量X=1,两个函数都执行X+1
由于操作都要交给CPU执行,而CPU会让每个程序交替运行,导致全局变量还没存放进去,另一个线程又拿出来,于是另一个线程所拿出来的全局变量还没改变,导致变量只执行了一次 +1 所以全局变量是 2
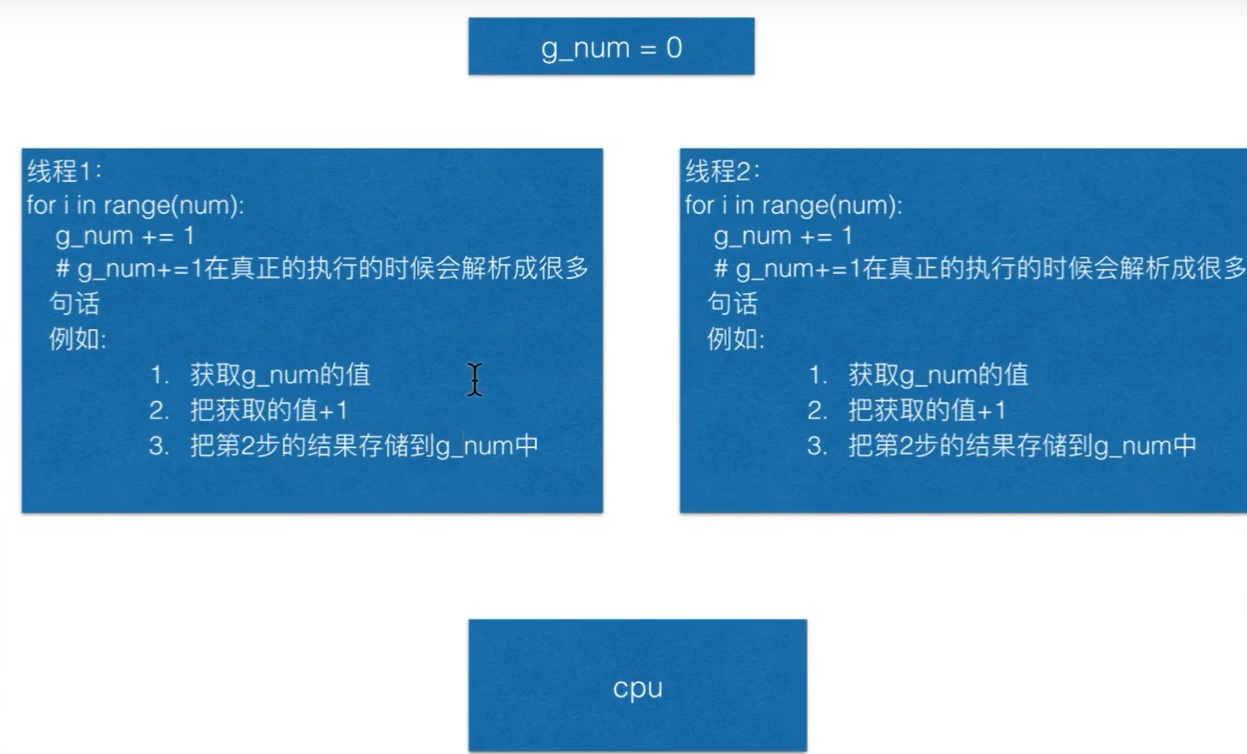
所以这时就需要用到原子性操作(同步),要么做完,要么不做(概念 :同步就是协同步调,按预定的先后次序运行)
所以可以在创建对线的时候,把变量放进去
t1 = threading.Thread(target=test1,args=(num,)) # args = (记得是元组,如果只有一个数据就加逗号)
例子:
1 import threading 2 import time 3 4 def test1(temp): 5 temp.append(33) 6 print('__test1 %s' % str(temp)) 7 def test2(temp): 8 print('__test1 %s' % str(temp)) 9 10 num = [11,22] 11 def main(): 12 # target 指定将来这个线程要去执行哪个函数 13 # args 指定将来调用这个函数的时候,传递什么数据进去 14 t1 = threading.Thread(target=test1,args=(num,)) # args = (记得是元组如果只有一个就加逗号) 15 t2 = threading.Thread(target=test2,args=(num,)) 16 t1.start() 17 time.sleep(1) #保证test1先执行 18 t2.start() 19 print('__main %s'% num) 20 21 if __name__ == '__main__': 22 main()
7. 互斥锁:
当多个线程几乎同时修改某一共享数据的时候,需要运行同步控制,最简单的同步机制是引入互斥锁。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定",其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
使用:
1.mutex = threading.Lock() #创建锁,默认未上锁 也可以有多个锁
2.mutex.acquire() #锁定,如果之前没有上过锁,那么此时上锁成功,如果之前已经上过锁,堵塞,等待这个锁被解开,然后上锁
3.mutex.release() #释放
温馨提示:
1: 被锁的语句越少,越好。但是如果没检查好,中间的过程可能会出错,但最终结果不会出错
2: 如果有多个锁,可能会出现死锁现象。就像两个吵架的朋友,都在等对方先道歉,结果~~~~(导致程序未响应)
解决方法:1.程序设计时尽量避免(银行家算法(https://www.bilibili.com/video/av56898207?p=10)7:00)
2.添加超时时间 等
进程:
1.进程和程序的关系:
1.程序是静态的;进程是动态的
2.通俗来讲程序是死的不变的,进程是活的改变的。一个程序在没运行之前是程序,运行之后是进程
3.程序是一种电脑能识别的2进制代码,当你一直运行程序的时候,会出现多个进程(相当于菜谱和菜,照这菜谱可以做多道菜)
4.程序没有资源,当程序中需要用到的的摄像头,键盘等。程序是不能用的,只有变成进程时可以用。
5.一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元,不仅可以通过线程完成多任务,进程也可以
2.进程的一生: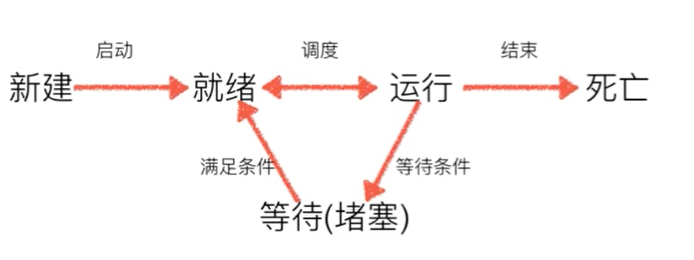
3.缺点:虽然多个进程效率高,但过多的进程会导致程序交替时间变长,每个进程都需要分配内存来存取数据,所以会导致资源浪费
虽然共享同一份代码,但各自需要改变的数据不同,所以如果不能共享的数据操作系统会帮你复制一份。(写时拷贝)
4.进程间的通信:
1.可以用socket进行进程间的通信
2.可以用同一文件来进行通信,即在同一个文件中进行读写操作的交流(但是在硬盘上读取和写入比较慢,内存运行太快了)
3.Queue队列(记得是队列) 在同一内存中通信:
因为进程之间不能共享全局变量,所以通过创建队列,把队列当成实参传入函数
使用:
1.multiprocessing.Queue() 创建队列,括号里面可以填数字代表最多存放几个,不填的话,系统自动把你选择最大的
2.可以用 x.put(XX) 来存入数据,什么数据都行,如果是满的,就堵塞
3.可以用 x.get(XX) 来取出数据,什么先放就先取出来,如果是空的,就堵塞
4.可以用 x.get_nowait() 来取数据。如果没有,直接发出异常,x.put_nowait()同理
5.可以用 x.full() / x.empty() 来检验队列是否为 慢/空,返回 False或 True
目的:用来解耦,比如下载数据,可以写两个函数,一个负责下载数据,一个负责处理数据
如:
1 import multiprocessing 2 import time 3 4 5 def down(q): 6 '''下载数据''' 7 # 模拟从网上下载下来的数据 8 data = [11,22,33,44] 9 10 # 向队列中写入数据 11 for i in data: 12 q.put(i) 13 14 print('下载完毕') 15 16 17 def deal(q): 18 '''处理数据''' 19 save = list() # 跟save = [] 一样,但比较好看出目的 20 while True: 21 data = q.get() 22 save.append(data) 23 if q.empty(): 24 print('处理完毕') 25 print(save) 26 time.sleep(5) 27 break 28 29 def main(): 30 # 因为进程变量不共享,所以创建一个队列当成实参 31 q = multiprocessing.Queue() # 括号里面可以填数字代表最多存放几个 32 # 不填的话,系统自动把你选择最大的 33 34 # 创建两个进程 一个负责下载,一个负责处理 35 p1 = multiprocessing.Process(target = down, args = (q,)) 36 p2 = multiprocessing.Process(target = deal, args = (q,)) 37 p1.start() 38 p2.start() 39 40 41 if __name__ == '__main__': 42 main()
5.进程池 Pool
1.作用:缓存,可以让人们重复利用进程池里的进程,因为进程的创建和销毁需要大量资源
2.概念:就像开饭店一样,每个座椅都是一个进程,总不能来一个人买一套座椅,然后再卖掉,再来一个人再买再卖;所以只能预先买好座椅。
但如果来100个人,难道要买一百套吗? 不!可能只买20套就是最好的(需要根据测试),这样就能即快速,又经济地服务所有人
3.使用
1.创建进程池:PO=multiprocessing.Pool(3) 最大进程数3,但如果在短时见内加入多个进程,即不会失败也不会堵塞,而会把多出来的进程存储起来
2.使用进程池:
1.创建函数-----买椅子 def worker(msg):
2.使用函数-----使用椅子:
for i in range(0, 10):
po.apply_async(worker, (i,))
3.关闭进程池:x.close() # 关闭进程池
x.join() # 进程池的主进程不会等待池里的进程结束才结束,会自己结束,所以要调用 x.join() 来等待池中的子进程结束,必须放在close语句后
温馨提示:
1.试了一下发现多进程需要在main函数中使用,如果直接在外面创建使用就不行,只能加main函数,然后在main中调用
2.如果想要让主进程和进程池进行通信,就要用 multiprocessing.Manager.Queue() 创建队列
进程和线程的区别:
功能:图片
进程:能够完成多任务,比如 在一台电脑上能够运行多个QQ-------一份资源有一个执行的剪头,有多份资源就可以执行多个语句
线程:能够完成多任务,比如 在一个QQ中的多个聊天窗口---------一份资源有多执行的剪头,有多个剪头就可以执行多个语句
全局变量:
线程共享全局变量,但进程不共享全局变量,每个流水线上的资源不能共享
“辈分”:
一个进程里,至少有一个主线程;先创建进程,再创建线程来执行进程。所以先有进程,后有线程
协程:https://www.cnblogs.com/otome/p/12391512.html
进程、线程、协程的一些总结:
1.进程是资源分配的单位
2.线程是操作系统调度的单位
3.进程切换需要的资源最大,效率很低
4.线程切换需要的资源一般,效率一般(在不考虑GIL的情况下)
5.协程切换任务资源很小,效率很高
6.多进程,多线程根据CPU核数不一样可能是并行,但协程是在一个线程中,所以是并发
打个比方:
1.有一个老板想要开个工厂进行生产某件商品(例如剪子)
2.他需要花一些财力物力制作一条生产线,这个生产线上有很多的器件以及材料这些所有的为了能够生产剪子而准备的资源称之为:进程
3.只有生产线是不能够进行生产的,所以老板的找个工人来进行生产,这个工人能够利用这些材料最终一步步的将剪子做出来,这个来做事情的工人称之为:线程
4.这个老板为了提高生产率,想到3种办法:
1.在这条生产线上多招些工人,一起来做剪子,这样效率是成倍增长,即单进程多线程方式
2.老板发现这条生产线上的工人不是越多越好,因为一条生产线的资源以及材料毕竟有限,所以老板又花了些财力物力购置了另外一条生产线,然后再招些工人这样效率又再一步提高了,即多进程多线程方式
3.老板发现,现在已经有了很多条生产线,并且每条生产线上已经有很多工人了(即程序是多进程的,每个进程中又有多个线程), 为了再次提高效率,老板想了个损招,规定:如果某个员工在上班时临时没事或者再等待某些条件(比如等待另一个工人生产完某道工序之后他才能再次工作), 那么这个员工就利用这个时间去做其它的事情,那么也就是说:如果一个线程等待某些条件,可以充分利用这个时间去做其它事情,其实这就是:协程方式