作者|Zolzaya Luvsandorj
编译|VK
来源|Towards Datas Science
掌握sklearn必须知道这三个强大的工具。因此,在建立机器学习模型时,学习如何有效地使用这些方法是至关重要的。
在深入讨论之前,我们先从两个方面着手:
-
Transformer:Transformer是指具有fit()和transform()方法的对象,用于清理、减少、扩展或生成特征。简单地说,transformers帮助你将数据转换为机器学习模型所需的格式。OneHotEncoder和MinMaxScaler就是Transformer的例子。
-
Estimator:Estimator是指机器学习模型。它是一个具有fit()和predict()方法的对象。我们将交替使用模型和Estimator这2个术语。该链接是一些Estimator的例子:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html。

安装
如果你想在你电脑上运行代码,确保你已经安装了pandas,seaborn和sklearn。我在Jupyter notebook中在python3.7.1中编写脚本。
让我们导入所需的库和数据集。关于这个数据集(包括数据字典)的详细信息可以在这里找到(这个源实际上是针对R的,但是它似乎引用了相同的底层数据集):https://vincentarelbundock.github.io/Rdatasets/doc/reshape2/tips.html。
# 设置种子
seed = 123
# 为数据导入包/模块
import pandas as pd
from seaborn import load_dataset
# 为特征工程和建模导入模块
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LinearRegression
# 加载数据集
df = load_dataset('tips').drop(columns=['tip', 'sex']).sample(n=5, random_state=seed)
# 添加缺失的值
df.iloc[[1, 2, 4], [2, 4]] = np.nan
df
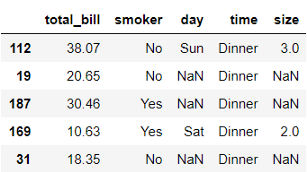
使用少量的记录可以很容易地监控每个步骤的输入和输出。因此,我们将只使用数据集中5条记录的样本。
管道
假设我们想用smoker、day和time列来预测总的账单。我们将先删除size列并对数据进行划分:
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['total_bill', 'size']),
df['total_bill'],
test_size=.2,
random_state=seed)
通常情况下,原始数据不是我们可以直接将其输入机器学习模型的状态。因此,将数据转换为可接受且对模型有用的状态成为建模的必要先决条件。让我们做以下转换作为准备:
-
用“missing”填充缺失值
-
one-hot编码
以下完成这两个步骤:
# 输入训练数据
imputer = SimpleImputer(strategy='constant', fill_value='missing')
X_train_imputed = imputer.fit_transform(X_train)
# 编码训练数据
encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
X_train_encoded = encoder.fit_transform(X_train_imputed)
# 检查训练前后的数据
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(X_train_imputed, columns=X_train.columns))
display(pd.DataFrame(X_train_encoded, columns=encoder.get_feature_names(X_train.columns)))
# 转换测试数据
X_test_imputed = imputer.transform(X_test)
X_test_encoded = encoder.transform(X_test_imputed)
# 检查测试前后的数据
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(X_test_imputed, columns=X_train.columns))
display(pd.DataFrame(X_test_encoded, columns=encoder.get_feature_names(X_train.columns)))
你可能已经注意到,当映射回测试数据集的列名时,我们使用了来自训练数据集的列名。这是因为我更喜欢使用来自于训练Transformer的数据的列名。但是,如果我们使用测试数据集,它将给出相同的结果。
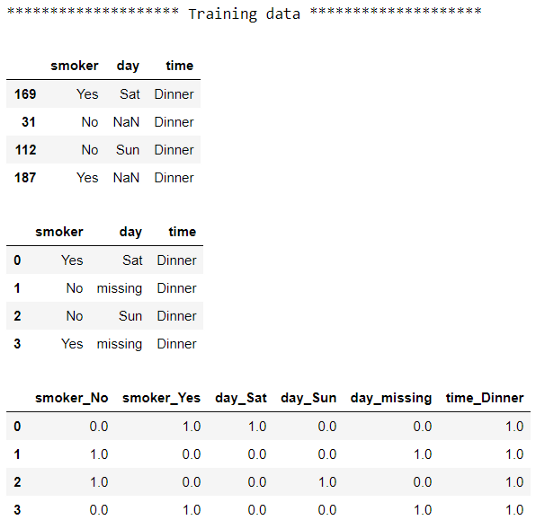

对于每个数据集,我们首先看到原始数据,然后是插补后的输出,最后是编码后的输出。
这种方法可以完成任务。但是,我们将上一步的输出作为输入手动输入到下一步,并且有多个临时输出。我们还必须在测试数据上重复每一步。随着步骤数的增加,维护将变得更加繁琐,更容易出错。
我们可以使用管道编写更精简和简洁的代码:
# 将管道与训练数据匹配
pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
pipe.fit(X_train)
# 检查训练前后的数据
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(pipe.transform(X_train), columns=pipe['encoder'].get_feature_names(X_train.columns)))
# 检查测试前后的数据
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(pipe.transform(X_test), columns=pipe['encoder'].get_feature_names(X_train.columns)))
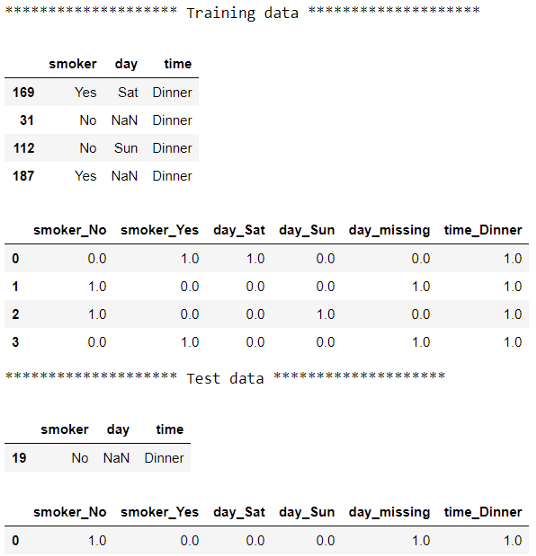
使用管道时,每个步骤都将其输出作为输入传递到下一个步骤。因此,我们不必手动跟踪数据的不同版本。这种方法为我们提供了完全相同的最终输出,但是使用了更优雅的代码。
在查看了转换后的数据之后,现在是在我们的示例中添加模型的时候了。让我们从为第一种方法添加一个简单模型:
# 输入训练数据
imputer = SimpleImputer(strategy='constant', fill_value='missing')
X_train_imputed = imputer.fit_transform(X_train)
# 编码训练数据
encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
X_train_encoded = encoder.fit_transform(X_train_imputed)
# 使模型拟合训练数据
model = LinearRegression()
model.fit(X_train_encoded, y_train)
# 预测训练数据
y_train_pred = model.predict(X_train_encoded)
print(f"Predictions on training data: {y_train_pred}")
# 转换测试数据
X_test_imputed = imputer.transform(X_test)
X_test_encoded = encoder.transform(X_test_imputed)
# 预测测试数据
y_test_pred = model.predict(X_test_encoded)
print(f"Predictions on test data: {y_test_pred}")

我们将对管道方法进行同样的处理:
# 将管道与训练数据匹配
pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False)),
('model', LinearRegression())])
pipe.fit(X_train, y_train)
# 预测训练数据
y_train_pred = pipe.predict(X_train)
print(f"Predictions on training data: {y_train_pred}")
# 预测测试数据
y_test_pred = pipe.predict(X_test)
print(f"Predictions on test data: {y_test_pred}")
你可能已经注意到,一旦我们训练了一条管道,进行预测是多么简单。pipe.predict(X)对原始数据进行转换,然后返回预测。也很容易看到步骤的顺序。让我们直观地总结一下这两种方法:
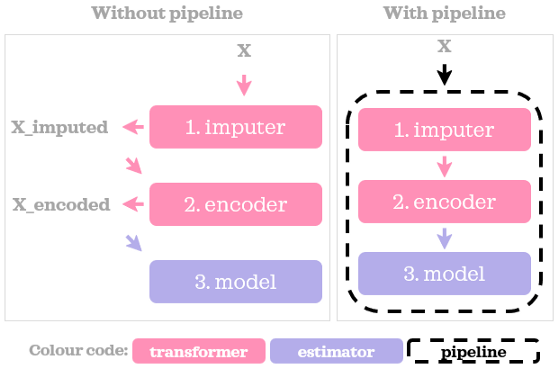
使用管道不仅可以组织和简化代码,而且还有许多其他好处,下面是其中一些好处:
-
微调管道的能力:当构建一个模型时,你可能需要尝试不同的方法来预处理数据并再次运行模型,看看预处理步骤中的调整是否能提高模型的泛化能力。在优化模型时,微调不仅存在于模型的超参数中,而且存在于预处理步骤的实现中。考虑到这一点,当我们有一个统一了Transformer和Estimator的管道对象时,我们可以微调整个管道的超参数,包括使用GridSearchCV或RandomizedSearchCV的Estimator和两个Transformer。
-
更容易部署:在训练模型时用于准备数据的所有转换步骤在进行预测时也可以应用于生产环境中的数据。当我们训练管道时,我们训练一个包含数据转换器和模型的对象。一旦经过训练,这个管道对象就可以用于更平滑的部署。
ColumnTransformer
在前面的例子中,我们以相同的方式对所有列进行插补和编码。但是,我们经常需要对不同的列组应用不同的transformer。例如,我们希望将OneHotEncoder仅应用于分类列,而不应用于数值列。这就是ColumnTransformer的用武之地。
这一次,我们将对保留所有列的数据集进行分区,以便同时具有数值和类别特征。
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['total_bill']),
df['total_bill'],
test_size=.2,
random_state=seed)
# 定义分类列
categorical = list(X_train.select_dtypes('category').columns)
print(f"Categorical columns are: {categorical}")
# 定义数字列
numerical = list(X_train.select_dtypes('number').columns)
print(f"Numerical columns are: {numerical}")
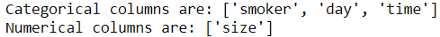
我们根据数据类型将特征分为两组。列分组可以根据数据的适当情况进行。例如,如果不同的预处理管道更适合分类列,则可以将它们进一步拆分为多个组。
上一节的代码现在将不再工作,因为我们有多个数据类型。让我们看一个例子,其中我们使用ColumnTransformer和Pipeline在存在多个数据类型的情况下执行与之前相同的转换。
# 定义分类管道
cat_pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 使ColumnTransformer拟合训练数据
preprocessor = ColumnTransformer(transformers=[('cat', cat_pipe, categorical)],
remainder='passthrough')
preprocessor.fit(X_train)
# 准备列名
cat_columns = preprocessor.named_transformers_['cat']['encoder'].get_feature_names(categorical)
columns = np.append(cat_columns, numerical)
# 检查训练前后的数据
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(preprocessor.transform(X_train), columns=columns))
# 检查测试前后的数据
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(preprocessor.transform(X_test), columns=columns))
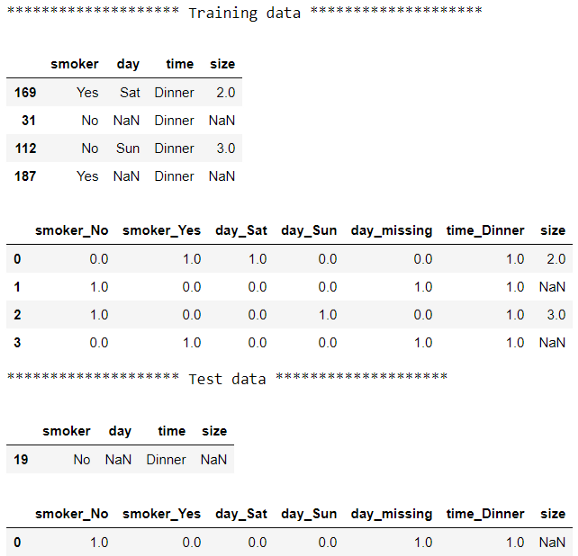
分类列的输出与上一节的输出相同。唯一的区别是这个版本有一个额外的列:size。我们已经将cat_pipe(在上一节中称为pipe)传递给ColumnTransformer来转换分类列,并指定remainment='passthrough'以保持其余列不变。
让我们用中值填充缺失值,并将其缩放到0和1之间:
# 定义分类管道
cat_pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定义数值管道
num_pipe = Pipeline([('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# 使ColumnTransformer拟合训练数据
preprocessor = ColumnTransformer(transformers=[('cat', cat_pipe, categorical),
('num', num_pipe, numerical)])
preprocessor.fit(X_train)
# 准备列名
cat_columns = preprocessor.named_transformers_['cat']['encoder'].get_feature_names(categorical)
columns = np.append(cat_columns, numerical)
# 检查训练前后的数据
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(preprocessor.transform(X_train), columns=columns))
# 检查测试前后的数据
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(preprocessor.transform(X_test), columns=columns))

现在所有列都被插补,范围在0到1之间。使用ColumnTransformer和Pipeline,我们将数据分成两组,将不同的管道和不同的Transformer应用到每组,然后将结果粘贴在一起:
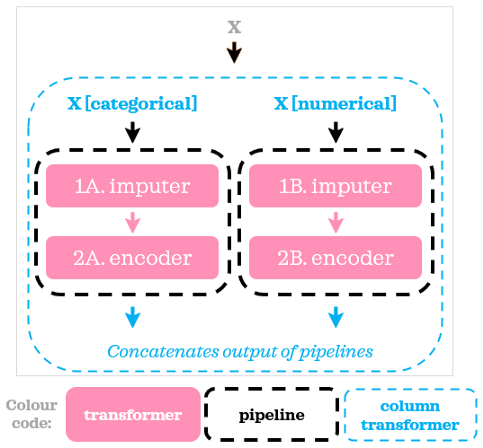
尽管在我们的示例中,数值管道和分类管道中的步骤数相同,但管道中可以有任意数量的步骤,并且不同列子集的步骤数不必相同。现在我们将一个模型添加到我们的示例中:
# 定义分类管道
cat_pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定义数值管道
num_pipe = Pipeline([('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# 组合分类管道和数值管道
preprocessor = ColumnTransformer(transformers=[('cat', cat_pipe, categorical),
('num', num_pipe, numerical)])
# 在管道上安装transformer和训练数据的estimator
pipe = Pipeline(steps=[('preprocessor', preprocessor),
('model', LinearRegression())])
pipe.fit(X_train, y_train)
# 预测训练数据
y_train_pred = pipe.predict(X_train)
print(f"Predictions on training data: {y_train_pred}")
# 预测测试数据
y_test_pred = pipe.predict(X_test)
print(f"Predictions on test data: {y_test_pred}")

为了将ColumnTransformer中指定的预处理步骤与模型结合起来,我们在外部使用了一个管道。以下是它的视觉表现:
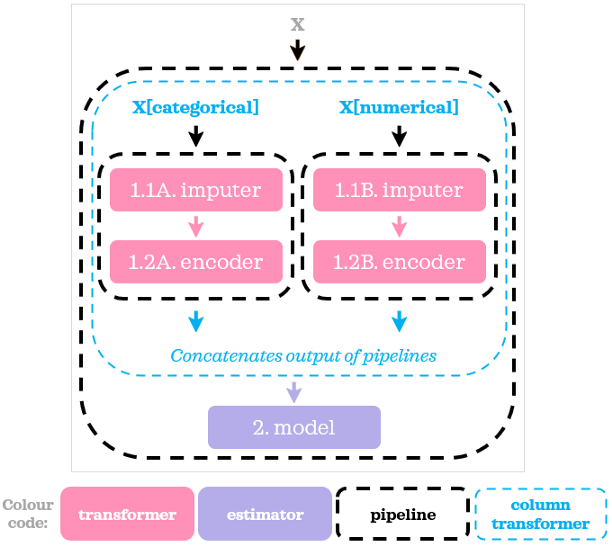
当我们需要对不同的列子集执行不同的操作时,ColumnTransformer很好地补充了管道。
FeatureUnion
以下代码的输出在本节中被省略,因为它们与ColumnTransformer章节的输出相同。
FeatureUnion是另一个有用的工具。它可以做ColumnTransformer刚刚做过的事情,但要做得更远:
# 自定义管道
class ColumnSelector(BaseEstimator, TransformerMixin):
"""Select only specified columns."""
def __init__(self, columns):
self.columns = columns
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.columns]
# 定义分类管道
cat_pipe = Pipeline([('selector', ColumnSelector(categorical)),
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定义数值管道
num_pipe = Pipeline([('selector', ColumnSelector(numerical)),
('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# FeatureUnion拟合训练数据
preprocessor = FeatureUnion(transformer_list=[('cat', cat_pipe),
('num', num_pipe)])
preprocessor.fit(X_train)
# 准备列名
cat_columns = preprocessor.transformer_list[0][1][2].get_feature_names(categorical)
columns = np.append(cat_columns, numerical)
# 检查训练前后的数据
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(preprocessor.transform(X_train), columns=columns))
# 检查测试前后的数据
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(preprocessor.transform(X_test), columns=columns))
我们可以将FeatureUnion视为创建数据的副本,并行地转换这些副本,然后将结果粘贴在一起。这里的术语副本更像是一种辅助概念化的类比,而不是实际采用的技术。
在每个管道的开始,我们添加了一个额外的步骤,在这里我们使用一个定制的转换器来选择相关的列:第14行和第19行的ColumnSelector。下面是我们可视化上面的脚本的图:
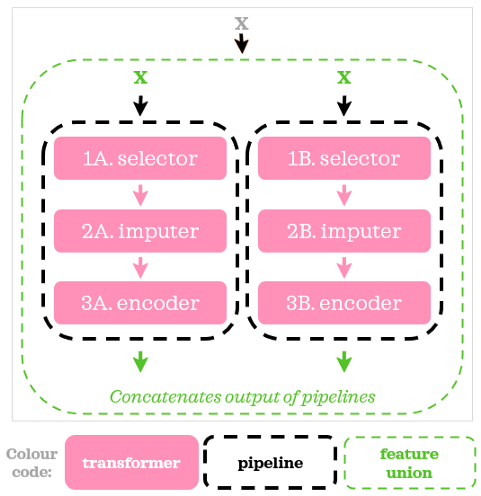
现在,是时候向脚本添加模型了:
# 定义分类管道
cat_pipe = Pipeline([('selector', ColumnSelector(categorical)),
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定义数值管道
num_pipe = Pipeline([('selector', ColumnSelector(numerical)),
('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# 组合分类管道和数值管道
preprocessor = FeatureUnion(transformer_list=[('cat', cat_pipe),
('num', num_pipe)])
# 组合分类管道和数值管道
pipe = Pipeline(steps=[('preprocessor', preprocessor),
('model', LinearRegression())])
pipe.fit(X_train, y_train)
# 预测训练数据
y_train_pred = pipe.predict(X_train)
print(f"Predictions on training data: {y_train_pred}")
# 预测测试数据
y_test_pred = pipe.predict(X_test)
print(f"Predictions on test data: {y_test_pred}")
它看起来很像我们用ColumnTransformer做的。
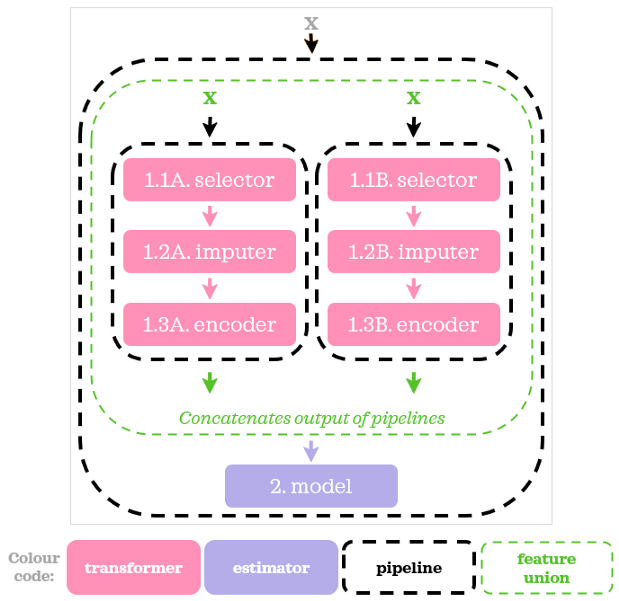
如本例所示,使用FeatureUnion比使用ColumnTransformer要复杂得多。因此,在我看来,在类似的情况下最好使用ColumnTransformer。
然而,FeatureUnion肯定有它的位置。如果你需要以不同的方式转换相同的输入数据并将它们用作特征,FeatureUnion就是其中之一。例如,如果你正在处理一个文本数据,并且希望对数据进行tf-idf矢量化以及提取文本长度,FeatureUnion是一个完美的工具。
总结
你可能已经注意到,Pipeline是超级明星。ColumnTransformer和FeatureUnion是用于管道的附加工具。ColumnTransformer更适合于并行划分,而FeatureUnion允许我们在同一个输入数据上并行应用多个转换器。下面是一个简单的总结:
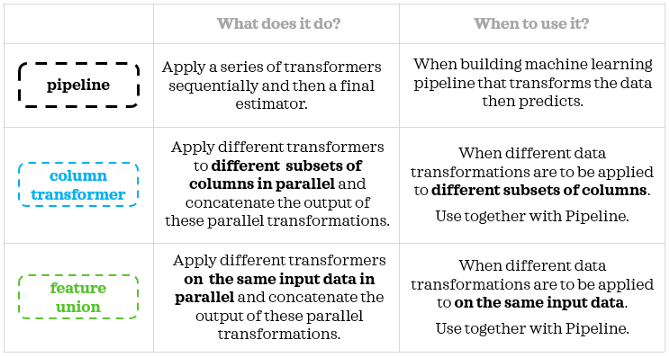
谢谢你阅读我的帖子。希望这篇文章能帮助你更多地了解这些有用的工具。我希望你能在你的数据科学项目中使用它们。如果你感兴趣,以下是我的一些帖子的链接:
- Exploratory text analysis in Python(https://towardsdatascience.com/exploratory-text-analysis-in-python-8cf42b758d9e)
- Preprocessing text in Python(https://towardsdatascience.com/preprocessing-text-in-python-923828c4114f)
Sentiment classification in Python(https://towardsdatascience.com/sentiment-classification-in-python-da31833da01b) - 5 tips for pandas users(https://towardsdatascience.com/5-tips-for-pandas-users-e73681d16d17)
- 5 tips for data aggregation in pandas(https://towardsdatascience.com/writing-5-common-sql-queries-in-pandas-90b52f17ad76)
- Writing 5 common SQL queries in pandas(https://towardsdatascience.com/writing-5-common-sql-queries-in-pandas-90b52f17ad76)
- Writing advanced SQL queries in pandas(https://towardsdatascience.com/writing-advanced-sql-queries-in-pandas-1dc494a17afe)
原文链接:https://towardsdatascience.com/vectorizing-code-matters-66c5f95ddfd5
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/