作者|Anders Ohrn
编译|VK
来源|Towards Data Science
利用深度卷积神经网络(DCNN)进行监督图像分类是一个成熟的过程。通过预训练模板模型加上微调优化,可以在许多有意义的应用中获得非常高的准确率——比如最近在医学图像上的这项研究,在日常物体图像上预训练的模板Inception v3模型对前列腺癌诊断的准确率达到了99.7%。
对于无监督的图像机器学习,目前的研究现状远没有定论。
聚类是无监督机器学习的一种形式,其中数据(本例中的图像)根据数据收集本身的某种结构进行分簇。在同一个簇中结束的图像应该比不同簇中的图像更相似。
图像数据可能是复杂的-变化的背景,视图中的多个对象-因此一对图像比另一对图像更相似意味着什么并不明显。如果没有基本的真实性标签,通常不清楚是什么使一种聚类方法优于另一种聚类方法。
一方面,无监督的问题因此比有监督的问题更加模糊。没有现成的正确答案可供优化。另一方面,从模糊的问题、假设的产生、问题的发现和修补中,最有趣的东西出现了。
我将描述一种最新的图像聚类方法的实现(https://arxiv.org/abs/1903.12355)。这是近年来发表的许多先进的DCNN聚类技术之一。
我使用PyTorch库来演示如何实现这个方法,并在整个文本中提供了几个详细的代码片段。仓库中提供完整的代码:https://github.com/anderzzz/monkey_caput
在标准库中没有无监督版本的聚类方法,这点不像有监督版本,它可以很容易获得图像聚类方法,但PyTorch仍然能够平稳地实现实际上非常复杂的方法。因此,我能够探索、测试和轻微地探究DCNNs应用于聚类任务时可以做什么。
我的目标是展示如何从一些概念和方程开始,你可以使用PyTorch来得到一些可以在计算机上运行的非常具体的东西,并指导进一步的创新和修改你所拥有的任何任务
我将把这个应用到真菌的图像上。为什么是真菌?你待会儿再看。
但首先…实现VGG自编码器
在讨论聚类方法之前,我将实现一个自动编码器(AE)。AEs有各种各样的应用,包括降维,并且本身很有趣。它们在图像聚类中的作用将在以后变得更加清楚。
用PyTorch库实现基本的ae并不是那么困难(请看这两个例子)。我将实现特定的AE架构,它是SegNet方法的一部分,它建立在VGG模板卷积网络上。VGG定义了一种体系结构,最初是为监督图像分类而开发的。
AE的架构如下图所示。
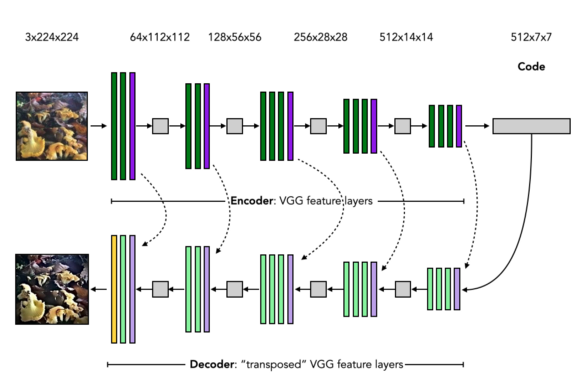
图像自编码的步骤如下:
-
准备输入图像(左上角)
-
将图像输入编码器,由具有标准CNN和ReLU激活的卷积层(绿色)和最大池层(紫色)组成
-
得到一个低维的编码
-
将编码输入译码器,它由转置的卷积层(带归一化和ReLU激活)(浅绿色)和解池化层(浅紫色)加上一个没有归一化或激活的最终卷积层(黄色)
-
获得与输入尺寸相同的输出图像。
是时候把这个设计变成代码了。
我从创建一个编码器模块开始。第一行,包括初始化方法,如下所示:
import torch
from torch import nn
from torchvision import models
class EncoderVGG(nn.Module):
'''
基于vgg16体系结构的图像编码器,具有batch normalization。
Args:
预训练的params (bool,可选):是否应该用预训练的vGG参数填充网络,默认值为True
'''
channels_in = 3
channels_code = 512
def __init__(self, pretrained_params=True):
super(EncoderVGG, self).__init__()
vgg = models.vgg16_bn(pretrained=pretrained_params)
del vgg.classifier
del vgg.avgpool
self.encoder = self._encodify_(vgg)
编码器的结构与VGG-16卷积网络的特征提取层结构相同。因此,PyTorch库中很容易找到该部分—PyTorch models.vgg16_bn,请参阅代码片段中的第19行。
与VGG的规范应用程序不同,编码不会被输入到分类层中。最后两层vgg.classifier以及vgg.avgpool被丢弃。
编码器的层需要一次调整。在解码器的解池层中,编码器的最大池层中的池索引必须可用,在前面的图像中虚线箭头表示。VGG -16的模板版本不生成这些索引。然而,池化层可以重新初始化。这就是EncoderVGG模块的_encodify方法完成的工作。
def _encodify_(self, encoder):
'''
基于VGG模板的架构创建编码器模块列表。在编码器-解码器体系结构中,解码器中的解池操作需要来自编码器中相应池操作的池索引。在VGG模板中,这些索引不返回。因此需要使用此方法扩展池操作。
参数:
编码器:模板VGG模型
返回:
模块:定义与VGG模型对应的编码器的模块列表
'''
modules = nn.ModuleList()
for module in encoder.features:
if isinstance(module, nn.MaxPool2d):
module_add = nn.MaxPool2d(kernel_size=module.kernel_size,
stride=module.stride,
padding=module.padding,
return_indices=True)
modules.append(module_add)
else:
modules.append(module)
return modules
因为这是一个PyTorch模块(nn.Module),通过EncoderVGG实例实现小批量图像数据的前向传播需要一个forward方法:
def forward(self, x):
'''将图像输入encoder
Args:
x (Tensor): 图片tensor
Returns:
x_code (Tensor): 编码 tensor
pool_indices (list): 池索引张量
'''
pool_indices = []
x_current = x
for module_encode in self.encoder:
output = module_encode(x_current)
# 如果模块是池,有两个输出,第二个是池索引
if isinstance(output, tuple) and len(output) == 2:
x_current = output[0]
pool_indices.append(output[1])
else:
x_current = output
return x_current, pool_indices
该方法按顺序执行编码器中的每个层,并在创建池索引时收集它们。在执行编码器模块之后,代码与池索引的有序集合一起返回。
接下来是解码器。
它是VGG-16网络的“转置”版本。我使用引号是因为解码器层看起来很像反向的编码器,但严格地说,它不是反转或转置。
译码器模块的初始化:
class DecoderVGG(nn.Module):
'''译码器的代码基于vgg16体系结构与batch normalization。
Args:
encoder: ' EncoderVGG '的编码器实例,它将被转换成一个解码器
'''
channels_in = EncoderVGG.channels_code
channels_out = 3
def __init__(self, encoder):
super(DecoderVGG, self).__init__()
self.decoder = self._invert_(encoder)
def _invert_(self, encoder):
'''将编码器反转,以将译码器创建为编码器的镜像
译码器由两种主要类型组成:二维转置卷积和二维解池,2D卷积之后是批处理归一化和激活。
译码器是反向的,编码器中的卷积变成了转置卷积加上归一化和激活,编码器中的maxpooling变成了unpooling。
Args:
encoder (ModuleList): 编码器
Returns:
decoder (ModuleList): 通过编码器的“反转”获得的译码器
'''
modules_transpose = []
for module in reversed(encoder):
if isinstance(module, nn.Conv2d):
kwargs = {'in_channels' : module.out_channels, 'out_channels' : module.in_channels,
'kernel_size' : module.kernel_size, 'stride' : module.stride,
'padding' : module.padding}
module_transpose = nn.ConvTranspose2d(**kwargs)
module_norm = nn.BatchNorm2d(module.in_channels)
module_act = nn.ReLU(inplace=True)
modules_transpose += [module_transpose, module_norm, module_act]
elif isinstance(module, nn.MaxPool2d):
kwargs = {'kernel_size' : module.kernel_size, 'stride' : module.stride,
'padding' : module.padding}
module_transpose = nn.MaxUnpool2d(**kwargs)
modules_transpose += [module_transpose]
# 放弃最后的归一化和激活函数
modules_transpose = modules_transpose[:-2]
return nn.ModuleList(modules_transpose)
_invert_方法反向遍历编码器的各个层。
编码器中的卷积(图像中为绿色)替换为解码器中相应的转置卷积(图像中为浅绿色)。这个nn.ConvTranspose2d是PyTorch中的模块,它对数据进行上采样,而不是像众所周知的卷积操作那样进行下采样。如需进一步解释,请参阅此处:https://naokishibuya.medium.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
编码器中的最大池(紫色)替换为相应的解池层(浅紫色),或nn.MaxUnpool2d,参考PyTorch库模块。
解码器forward为:
def forward(self, x, pool_indices):
'''执行解码器
Args:
x (Tensor): 从编码器得到的编码张量
pool_indices (list): 池索引
Returns:
x (Tensor): 解码后的图像张量
'''
x_current = x
k_pool = 0
reversed_pool_indices = list(reversed(pool_indices))
for module_decode in self.decoder:
# 如果模块正在解池,收集适当的池索引
if isinstance(module_decode, nn.MaxUnpool2d):
x_current = module_decode(x_current, indices=reversed_pool_indices[k_pool])
k_pool += 1
else:
x_current = module_decode(x_current)
return x_current
编码以及编码器创建的池索引列表是输入。每当执行一个解池层时,反向地,每次取一个池索引。这样,关于编码器如何执行最大池的信息被转移到解码器。
因此,在镜像编码器层的转置层之后,forward的输出张量形状是与输入到编码器的图像张量形状相同。
完整的自编码器模块实现为编码器和解码器实例的组合:
class AutoEncoderVGG(nn.Module):
'''基于vgg16的batch normalization的自编码器。该类由编码器和解码器组成。
Args:
pretrained_params (bool, optional): 是否应该用先训练好的VGG参数填充网络。
默认值为True。
'''
channels_in = EncoderVGG.channels_in
channels_code = EncoderVGG.channels_code
channels_out = DecoderVGG.channels_out
def __init__(self, pretrained_params=True):
super(AutoEncoderVGG, self).__init__()
self.encoder = EncoderVGG(pretrained_params=pretrained_params)
self.decoder = DecoderVGG(self.encoder.encoder)
def forward(self, x):
'''自编码器前向传播
Args:
x (Tensor): 图像张量
Returns:
x_prime (Tensor): 编码和解码后的图像张量
'''
code, pool_indices = self.encoder(x)
x_prime = self.decoder(code, pool_indices)
return x_prime
AE的一组参数可以产生与相应输入非常相似的输出,这是一组很好的参数。我使用AE输入和输出之间每个像素的均方误差来作为一个目标函数量化它,也就是PyTorch库的nn.MSELoss。
通过定义AE模型和一个可微目标函数,利用PyTorch强大的工具进行反向传播,得到一个梯度,然后进行网络参数优化。我不会详细介绍训练是如何实施的(好奇的读者可以看看在仓库中的ae_learner.py,https://github.com/anderzzz/monkey_caput)。
编码器通过特征压缩图像,是聚类的起点
在训练AE之后,它包含一个编码器,它可以在较低的维度上近似地表示图像数据集重复出现的高层特征。对于真菌的图像数据集,这些特征可以是形状、边界和颜色,这些特征在几幅蘑菇图像中是共享的。换句话说,编码器体现了蘑菇样式加上典型背景的简洁表示。
因此,两个与这些高级特征非常相似的图像对应的编码应该比任何一对随机编码更接近——例如通过欧几里得距离或余弦相似度来衡量。
另一方面,图像的低维压缩是高度非线性的。因此,如果两个编码之间的距离大于某个相当小的阈值,就不能说明是互相对应的图像。这对于创建定义良好、清晰的簇并不理想。
编码器是一个起点。下一步将对编码器进行改进,利用已学的蘑菇特征将图像压缩成编码,这些编码也会形成固有的良好簇。
关于局部聚集损失的几个字和方程
局部聚集(LA)方法定义了一个目标函数来量化一组代码的聚类效果(https://arxiv.org/abs/1903.12355)。目标函数不像有监督的机器学习方法那样直接引用图像内容的真实标签。相反,目标函数量化编码图像数据本质上对定义良好的簇的适应程度。
用这种方法得到的定义是否可以创建有意义的聚类,这一点并不明显。这就是为什么需要实现和测试。
首先从LA的几个定义中说明要实现什么。
LA的簇目标是:
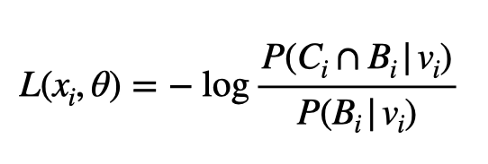
方程中的xᵢ是图像张量,θ表示编码器的参数。右侧的vᵢ是与xᵢ相对应的编码。这两个集合Cᵢ和Bᵢ由集合中其他图像的编码组成,它们分别被命名为vᵢ的近邻和背景邻居。
一组编码A的概率P定义为:
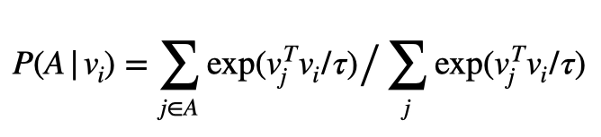
换句话说,指数定义了概率,其中如果概率密度越大,vᵢ与其他成员的点积越大。因此,集合a由与vᵢ相似,vᵢ可能是其簇的成员。
标量τ被称为温度,它定义了点积相似性的尺度。
对于给定的真菌图像集合{xᵢ},目标是找到使集合的聚类目标最小化的参数θ。LA论文的作者提出了一个论点,为什么这个目标是有意义的。我在这里不再重复这个论点。简单地说,分配给一个簇的编码越清晰,与该簇的补集的编码相比,簇的目标函数值就越低。
如何将LA目标作为自定义损失函数来实现
在上面关于AE的部分中,描述了定制编码器模块。缺少的是LA的目标函数,因为它不是PyTorch中库损失函数的一部分。
需要实现自定义损失模块。
loss函数模块的初始化初始化了许多scikit-learn函数,这些函数是在forward方法中定义背景集和近邻集中很有用。
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
from sklearn.neighbors import NearestNeighbors
from sklearn.cluster import KMeans
from sklearn.preprocessing import normalize
from scipy.spatial.distance import cosine as cosine_distance
class LocalAggregationLoss(nn.Module):
'''Local Aggregation Loss module from "Local Aggregation for Unsupervised Learning of Visual Embeddings" by
Zhuang, Zhai and Yamins (2019), arXiv:1903.12355v2
'''
def __init__(self, temperature,
k_nearest_neighbours, clustering_repeats, number_of_centroids,
memory_bank,
kmeans_n_init=1, nn_metric=cosine_distance, nn_metric_params={}):
super(LocalAggregationLoss, self).__init__()
self.temperature = temperature
self.memory_bank = memory_bank
self.neighbour_finder = NearestNeighbors(n_neighbors=k_nearest_neighbours + 1,
algorithm='ball_tree',
metric=nn_metric, metric_params=nn_metric_params)
self.clusterer = []
for k_clusterer in range(clustering_repeats):
self.clusterer.append(KMeans(n_clusters=number_of_centroids,
init='random', n_init=kmeans_n_init))
NearestNeighbors实例提供了一种有效的方法来计算数据点的最近邻。这将用于定义集合B。KMeans实例提供了一种有效的方法来计算数据点的簇。这些将用于定义集合C。
其中:LocalAggregationLoss所需的forward方法为
def forward(self, codes, indices):
'''local aggregation loss 模块的forward方法'''
assert codes.shape[0] == len(indices)
codes = codes.type(torch.DoubleTensor)
code_data = normalize(codes.detach().numpy(), axis=1)
# 计算和收集定义损失函数中的常量的索引数组。请注意,这些数据值在反向传播时不计算梯度
self.memory_bank.update_memory(code_data, indices)
background_neighbours = self._nearest_neighbours(code_data, indices)
close_neighbours = self._close_grouper(indices)
neighbour_intersect = self._intersecter(background_neighbours, close_neighbours)
# 计算给定记忆库常数的编码的概率密度
v = F.normalize(codes, p=2, dim=1)
d1 = self._prob_density(v, background_neighbours)
d2 = self._prob_density(v, neighbour_intersect)
return torch.sum(torch.log(d1) - torch.log(d2)) / codes.shape[0]
forward方法接受当前版本的编码器生成的一小批编码,以及完整数据集中所述编码的索引。由于在创建小批量时通常会对数据进行无序处理,因此索引可以是一个非连续整数的列表。
forward有两个主要部分。首先计算相邻集B,C及其交集。其次,对给定的一批编码和集合计算概率密度,然后将其计算LA目标函数。
“记忆库”是什么?
LA的创造者采用了一种记忆库的技巧,他们将其归因于吴等人的另一篇论文(https://arxiv.org/pdf/1808.04699.pdf)。这是一种处理LA目标函数的梯度依赖于数据集所有编码的梯度的方法。
所述函数的适当梯度必须计算如下所示:
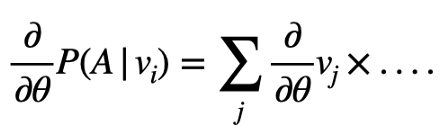
右边所有编码的和意味着需要计算大量的张量并且在反向传播时一直保留下来。在小批图像上迭代不会提高效率,因为必须计算与解码器参数有关编码的梯度。
因为聚类的质量将一个图像与数据集的所有其他图像相关联,而不是一个固定的真实标签,这种纠缠是可以理解的。
记忆库技巧相当于将当前小批量中的编码以外的其他编码视为常量。因此,与其他编码的导数的纠缠就消失了。只要近似的梯度足够好地引导优化朝最小值方向发展,这是一个有用的方法。
记忆库类实现为:
class MemoryBank(object):
'''Memory bank
Args:
n_vectors (int): 记忆库应该持有的向量数量
dim_vector (int): 记忆库应该持有的向量的维度
memory_mixing_rate (float, optional): 要添加到当前存储向量的新向量的一部分。值应该在0.0到1.0之间,值越大更新越快。混合速率可以在调用' update_memory '时设置。.
'''
def __init__(self, n_vectors, dim_vector, memory_mixing_rate):
self.dim_vector = dim_vector
self.vectors = np.array([marsaglia(dim_vector) for _ in range(n_vectors)])
self.memory_mixing_rate = memory_mixing_rate
self.mask_init = np.array([False] * n_vectors)
def update_memory(self, vectors, index):
'''用新的向量更新'''
if isinstance(index, int):
self.vectors[index] = self._update_(vectors, self.vectors[index])
elif isinstance(index, np.ndarray):
for ind, vector in zip(index, vectors):
self.vectors[ind] = self._update_(vector, self.vectors[ind])
def mask(self, inds_int):
'''给定整数索引构造一个布尔掩码'''
ret_mask = []
for row in inds_int:
row_mask = np.full(self.vectors.shape[0], False)
row_mask[row.astype(int)] = True
ret_mask.append(row_mask)
return np.array(ret_mask)
def _update_(self, vector_new, vector_recall):
return vector_new * self.memory_mixing_rate + vector_recall * (1.0 - self.memory_mixing_rate)
它由与待聚类数据集维数相同、个数相同的单位数据向量组成(在超球面上用Marsaglia的方法统一初始化)。
因此,一个用编码生成尺寸为512的1000幅图像的编码器任务,意味着在尺寸为512的真实坐标向量空间中有1000个单位向量的记忆库。一旦向记忆库提供了一组新的向量以及相应的索引,记忆就会用某种混合速率memory_mixing_rate更新。该类还包含一个方便的方法,用于将整数索引集合转换为整个数据集的布尔掩码。
注意,记忆库只处理数字。记忆库无法连接到PyTorch张量的反向传播机制。记忆库是更新的,而不是直接作为反向传播的一部分。
它是MemoryBank的一个实例,存储在LocalAggregationLoss的memory_bank属性中。
如何创建背景邻居集和近邻集
再次回到LocalAggregationLoss的forward方法。我使用先前初始化的scikit-learn实现邻居集的创建。
def _nearest_neighbours(self, codes_data, indices):
'''确定记忆库中给定编码的k个最近邻的索引
Returns:
indices_nearest (numpy.ndarray): 这批编码的k个最近邻的布尔数组
'''
self.neighbour_finder.fit(self.memory_bank.vectors)
indices_nearest = self.neighbour_finder.kneighbors(codes_data, return_distance=False)
return self.memory_bank.mask(indices_nearest)
def _close_grouper(self, indices):
'''确定与给定索引的向量在同一簇中的向量在记忆库中的索引
Returns:
indices_close (numpy.ndarray): 批代码相邻的布尔数组
'''
memberships = [[]] * len(indices)
for clusterer in self.clusterer:
clusterer.fit(self.memory_bank.vectors)
for k_index, cluster_index in enumerate(clusterer.labels_[indices]):
other_members = np.where(clusterer.labels_ == cluster_index)[0]
other_members_union = np.union1d(memberships[k_index], other_members)
memberships[k_index] = other_members_union.astype(int)
return self.memory_bank.mask(np.array(memberships, dtype=object))
def _intersecter(self, n1, n2):
'''两个布尔数组的交集计算'''
return np.array([[v1 and v2 for v1, v2 in zip(n1_x, n2_x)] for n1_x, n2_x in zip(n1, n2)])
_nearest_neighbours和_intersecter都很简单。前者依赖于寻找最近邻居的方法。它考虑记忆库中的所有数据点。
_close_grouper在记忆库中执行多个数据点聚类。与关注点vᵢ属于同一簇的那些数据点定义了这个近邻集Cᵢ。LA论文的作者鼓励使用多个聚类运行,因为聚类包含一个随机成分,所以通过执行多个聚类,可以消除噪声。
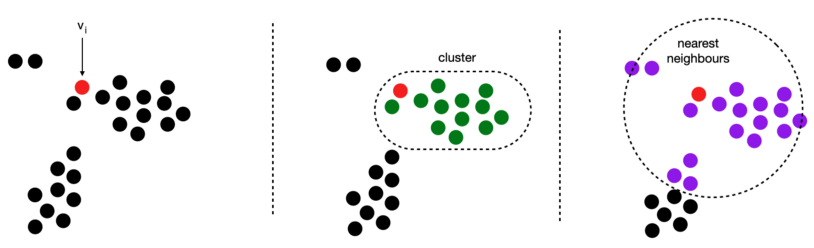
为了说明这一点,下图中的红点是其他编码海洋中感兴趣的编码。记忆库当前状态的聚类将感兴趣的点放在其他点的簇中(中间图像中的绿色)。最近邻定义了另一组相关数据点(右侧图像中为紫色)。“_nearest_neighbours”和“_close_grouper为小批量中的每个编码创建这两个集合,并将这些集合表示为布尔掩码。
计算概率密度,以便PyTorch反向传播能够计算梯度
对于批处理中每个代码vᵢ的两个集合(Bᵢ和Bᵢ与Cᵢ相交),是时候计算概率密度了。这个密度也可以用PyTorch方法来区分。
其实现方式为:
def _prob_density(self, codes, indices):
'''计算由指标定义的集合中编码的非归一化概率密度
Returns:
prob_dens (Tensor): 给定编码的向量的非归一化概率密度
'''
ragged = len(set([np.count_nonzero(ind) for ind in indices])) != 1
# 在该情况下,所有的向量子集都是相同的大小,可以简洁地使用广播和批处理。
if not ragged:
vals = torch.tensor([np.compress(ind, self.memory_bank.vectors, axis=0) for ind in indices],
requires_grad=False)
v_dots = torch.matmul(vals, codes.unsqueeze(-1))
exp_values = torch.exp(torch.div(v_dots, self.temperature))
pdensity = torch.sum(exp_values, dim=1).squeeze(-1)
#如果向量子集是不同的大小, 广播是不可能的,所以手动循环
else:
xx_container = []
for k_item in range(codes.size(0)):
vals = torch.tensor(np.compress(indices[k_item], self.memory_bank.vectors, axis=0),
requires_grad=False)
v_dots_prime = torch.mv(vals, codes[k_item])
exp_values_prime = torch.exp(torch.div(v_dots_prime, self.temperature))
xx_prime = torch.sum(exp_values_prime, dim=0)
xx_container.append(xx_prime)
pdensity = torch.stack(xx_container, dim=0)
return pdensity
在第14-16行中,所有不同的点积都是在小批量编码和记忆库子集之间计算的。这个np.compress将掩码应用于记忆库向量。
这个torch.matmul计算所有点积。还请注意,张量codes包含编码器的数学运算记录。因此,当这使PyTorch的反向传播机制autograd能够评估关于编码器所有参数的损耗准则的梯度。
概念上相同的操作发生在第25-27行,但是在这个子句中,mini-batch维度被显式地迭代。当numpy数组不能被广播时,这是必需的,对于参差不齐的数组(至少目前是这样)。
把模型和损失放在一起
总而言之,下面的代码可以为特定的数据集VGG编码器和LA提供训练。
from torch.optim import SGD
from torch.utils.data import DataLoader
from sklearn.preprocessing import normalize
import fungidata
from ae_deep import EncoderVGGMerged
from cluster_utils import MemoryBank, LocalAggregationLoss
# 创建真菌数据集
dataset = fungidata.factory.create('grid basic idx', ...)
dataloader = DataLoader(dataset, ...)
# 实例化定制的模型和初始预训练的vgg编码器
model = EncoderVGGMerged(merger_type='mean')
memory_bank = MemoryBank(n_vectors=5400, dim_vector=model.channels_code, memory_mixing_rate=0.5)
memory_bank.vectors = normalize(model.eval_codes_for_(dataloader), axis=1)
criterion = LocalAggregationLoss(memory_bank=memory_bank,
temperature=0.07, k_nearest_neighbours=500, clustering_repeats=6, number_of_centroids=100)
# 实例化一个随机梯度下降优化器
optimizer = SGD(model.parameters())
# 基本训练循环
for epoch in range(20):
for inputs in dataloader:
optimizer.zero_grad()
output = model(inputs['image'])
loss = criterion(output, inputs['idx'])
loss.backward()
optimizer.step()
我在讨论中省略了数据是如何准备的(我放在fungidata文件中的操作)。详细信息可以在仓库中找(https://github.com/anderzzz/monkey_caput)
对于这个讨论,将dataloader看作它可以返回真菌图像的小批量数据,inputs['image'],以及它们在更大数据集中的相应索引,inputs['idx']。
训练循环是函数式的,虽然很简短,但详细信息请参阅la_learner文件,不过没有使用任何不同寻常的东西。
我使用稍微修改过的编码器EncoderVGGMerged版本。它是EncoderVGG的子类。
class EncoderVGGMerged(EncoderVGG):
'''VGG编码器的特殊情况,其中代码是沿着高度/宽度维度合并的。这是' EncoderVGG '的一个瘦子类。
Args:
merger_type (str, optional): 定义如何合并代码.
'''
def __init__(self, merger_type='mean', pretrained_params=True):
super(EncoderVGGMerged, self).__init__(pretrained_params=pretrained_params)
if merger_type is None:
self.code_post_process = lambda x: x
self.code_post_process_kwargs = {}
elif merger_type == 'mean':
self.code_post_process = torch.mean
self.code_post_process_kwargs = {'dim' : (-2, -1)}
elif merger_type == 'flatten':
self.code_post_process = torch.flatten
self.code_post_process_kwargs = {'start_dim' : 1, 'end_dim' : -1}
else:
raise ValueError('Unknown merger type for the encoder code: {}'.format(merger_type))
def forward(self, x):
'''图像输入到编码器
Args:
x (Tensor): 图片张量
Returns:
x_code (Tensor): 合并
'''
x_current, _ = super().forward(x)
x_code = self.code_post_process(x_current, **self.code_post_process_kwargs)
return x_code
这个类在编码器的结果中附加一个应用于代码的合并层,因此它是一个一维的向量。
我将演示用于聚类的编码器模型,该模型应用于一个RGB 64x64图像作为输入。
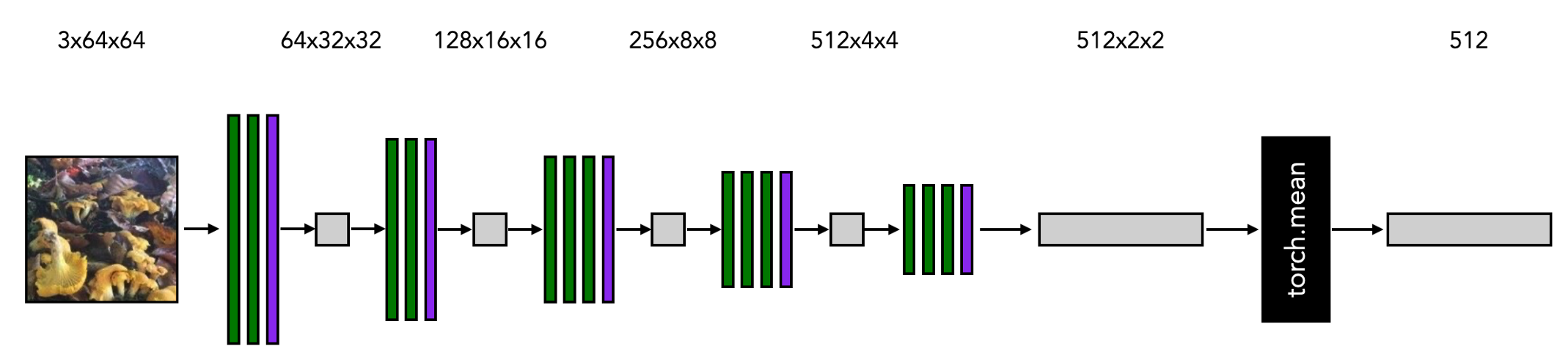
接下来,我将演示创建输出和损失变量的模型的一小批图像的前向过程。

图中的LALoss模块与记忆库交互,考虑到大小为N的总数据集中的小批量图像的索引。它构建记忆库当前状态的簇和最近邻,并将小批量代码与这些子集关联起来。
backward执行反向传播,从LA准则的损失输出开始,然后遵循涉及代码的数学运算,并通过链式规则获得LA目标函数相对于编码器参数的近似梯度。
关于真菌图像
我将把这个方法应用到真菌图像中。我的理由:
-
我使用的软件库不是为这个特定任务开发或预先训练的。我希望测试使用通用库工具处理特殊图像任务的场景。
-
真菌的外观在形状、颜色、大小、光泽、结构细节以及它们典型的背景(秋叶、青苔、土壤、采摘者的手)等方面各不相同。信号和噪声都是不同的。
-
真菌图像位于人类凭直觉识别的明显物体(例如狗、猫和汽车)与需要深层专业知识才能掌握的图像之间的最佳位置。我相信这有助于理解方法。
-
丹麦真菌学协会(2016)提供了非常好的注释众包公开数据。(https://svampe.databasen.org/).
以下是由真菌照片创建的图像数据,数据库中的三幅图像如下所示。

说明性测试运行和探索
LA的一个缺点是它涉及多个超参数。可悲的是,我没有足够的gpu来支持,所以我必须限制自己在超参数和真菌图像选择的许多可能变化中的很少一部分。
我在这篇文章中的重点是从概念和方程实现(外加一个真菌图像数据的插件)。因此,我在这里寻求说明和启发,并将继续对高层次的观察得出进一步的结论。
我训练AE的香肠菌和木耳蘑菇压缩到224x224。在随机梯度下降优化器下,AE最终收敛,但对于某些优化参数,训练陷入次优。下面显示了一个经过训练的AE的输入和输出示例。
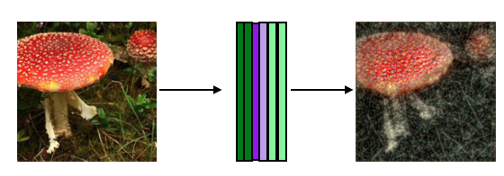
这是一个明显的损失保真度,特别是在周围的草地。
以AE的编码器为起始点,进一步对编码器进行LA目标优化。使用相同的一组蘑菇图像,温度为0.07,混合速率为0.5(如原始论文中所述),聚类的数量约为待聚类图像数量的十分之一。由于我的图像数据集比较小,所以我设置了背景邻居,将所有的图像都包含在数据集中。
一组图像说明如下:

很明显,苍蝇琼脂簇有明显的白色斑点。然而,在簇中所包含的图像也是相当不同的。观察其他簇,在其他簇中偶尔会出现白点苍耳帽。
另一个说明性簇如下所示。

这些图像有一些共同点,使它们与典型的图像有所不同:颜色较深,大部分来自背景中的褐色叶子。
但是,同样的,满足这个粗略标准的图像也出现在其他的聚类中,说明编码中还有额外的非线性关系,这使得上面的图像对应的编码相对紧密和不同,而其他的则不是,较难解释。
我还注意到许多簇只包含一个图像。改变进入k-means聚类的簇质心的数量会影响到这一点,但是随后会出现非常大的图像簇,因此很难提供对共享特征的直观解释。
这些是其他运行所生成的结果的说明。我在这里进行的有限的几次运行中最小化了LA的场景,创造出了一组图像,至少在我看来是一组自然的图像。
考虑到深度神经网络的灵活性,我希望有很多方法可以将图像压缩成清晰的簇,但就我所知,这些方法并不一定包含有用的含义。与实际情况标签不同的是,神经网络的灵活性被引导到一个我们在优化之前定义为有用的目标,优化器在这里可以自由地寻找特征来利用,以提高簇质量。
也许需要一个不同的归纳偏差来更好地限制灵活性的部署,以最小化LA目标函数?就我的视觉认知而言,也许LA目标函数应该与一个附加目标相结合,以防止它偏离某个合理的范围?也许我应该使用标准化的图像,例如某些医学图像、护照照片或固定透视相机,将图像的变化限制为较少的高级特征,而这些特征可以在聚类中使用?或者,我担心的真正答案是在这个问题上投入更多的gpu,然后找出超参数的完美组合?
当然都是猜测。多亏了PyTorch,从概念和方程式到原型设计和创建模板解决方案的障碍降低了。
结尾
常规警告:我对LA的实现与最初的论文一样,所以有出现误解或bug的可能性。
我没有花任何精力来优化实现。很可能我忽略了PyTorch和/或NumPy技巧,它们可以加快CPU或GPU的速度。
原文链接:https://towardsdatascience.com/image-clustering-implementation-with-pytorch-587af1d14123
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/