Linux 常用系统性能命令
查看系统负载top,free
**w/uptime **
最后面三个数字表示1分钟,5分钟,15分钟平均有多少个进程占用CPU占用CPU的进程可以是Running,也可以是Waiting
某一时刻1颗CPU只能有一个进程在使用其资源
top命令:
top 回车就可以进入到top界面
每3秒刷新一次
默认按cpu百分比排序,可以按M键按照内存使用率大小排序
按数字1,可以显示所有CPU使用率详情
top -bn1 静态显示所有进程的情况,也是按cpu百分比排序
静态显示进程信息,方便在shell脚本中使用top命令
free命令:
free查看内存和swap使用情况,关注最后一列的available,这个数字是真正剩余的物理内存大小
free -k -m -g -h
手动增加swap
dd if=/dev/zero of=/bigfile bs=1M count=1000
mkswap /bigfile
chmod 600 /bigfile
swapon /bigfile
监控磁盘 sysstat,iostat
iostat --> yum install -y sysstat
iostat -dx 1
iostat -dx 1 5
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以K为单位显示
-m 以M为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS使用情况
-p 可以报告出每块磁盘的每个分区的使用情况
-t 显示终端和CPU的信息
-x 显示详细信息
示例1:
root@localhost ~]# iostat -x
Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 07/24/2019 \_x86_64\_ (1
CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.24 0.00 0.71 0.08 0.00 97.97
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await
w_await svctm %util
sda 27.94 8.17 17.76 9.01 589.90 138.94 54.44 0.08 2.88 2.64 3.33 0.20 0.54
scd0 0.00 0.00 0.00 0.00 0.02 0.00 90.26 0.00 0.48 0.48 0.00 0.43 0.00
输出内容详解:
%user:CPU处在用户模式下的时间百分比
%nice:CPU处在带NICE值的用户模式下的时间百分比
%system:CPU处在系统模式下的时间百分比
%iowait:CPU等待输入输出完成时间的百分比
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比
%idle:CPU空闲时间百分比
当然了,iostat命令的重点不是用来看CPU的,重点是用来监测磁盘性能的。
Device:设备名称
rrqm/s:每秒合并到设备的读取请求数
wrqm/s:每秒合并到设备的写请求数
r/s:每秒向磁盘发起的读操作数
w/s:每秒向磁盘发起的写操作数
rkB/s:每秒读K字节数
wkB/s:每秒写K字节数
avgrq-sz:平均每次设备I/O操作的数据大小
avgqu-sz:平均I/O队列长度
await:平均每次设备I/O操作的等待时间
(毫秒),一般地,系统I/O响应时间应该低于5ms,如果大于 10ms就比较大了
r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间
w_await:每个写操作平均所需的时间;不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间
svctm:平均每次设备I/O操作的服务时间 (毫秒)(这个数据不可信!)
%util:一秒中有百分之多少的时间用于I/O操作,即被IO消耗的CPU百分比,一般地,如果该参数是100%表示设备已经接近满负荷运行了
----
[root@localhost ~]# iostat
Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 07/24/2019 \_x86_64\_ (1
CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.23 0.00 0.71 0.08 0.00 97.97
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 26.70 588.19 138.54 32169000 7576930
scd0 0.00 0.02 0.00 1038 0
输出内容详解:
cpu状态
%user:CPU处在用户模式下的时间百分比
%nice:CPU处在带NICE值的用户模式下的时间百分比
%system:CPU处在系统模式下的时间百分比
%iowait:CPU等待输入输出完成时间的百分比
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比
%idle:CPU空闲时间百分比
磁盘状态
tps:每秒I/O数(即IOPS。磁盘连续读和连续写之和)
kB_read/s:每秒从磁盘读取数据大小,单位KB/s
kB_wrtn/s:每秒写入磁盘的数据的大小,单位KB/s
kB_read:从磁盘读出的数据总数,单位KB
kB_wrtn:写入磁盘的的数据总数,单位KB
iotop --> yum install -y iotop
iotop 回车 动态显示,按IO使用率大小排序
综合工具vmstat
vmstat 1
vmstat 1 10
常见选项:
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M
,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
vmstat 命令详解
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
3 0 122232 58944 208692 102840 137 60 580 136 117 111 1 1 98 0 0
Procs(进程)
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b 等待IO的进程数量。
Memory(内存)
swpd
使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free 空闲物理内存大小。
buff 用作缓冲的内存大小。
cache
用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO
bi会非常小。
Swap
si 每秒从交换区写到内存的大小,由磁盘调入内存。
so 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。因为linux总是先把内存用光
IO
bi 每秒读取的块数
bo 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
in 每秒中断数,包括时钟中断。
cs 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示)
us 用户进程执行时间百分比(user time)
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)
sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa IO等待时间百分比
wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id 空闲时间百分比
关注:r、b、si、so、bi、bo、id、wa
vmstat –a 显示活跃和非活跃内存,显示增加了inact和active列

监控网卡流量sar,nload,iftop, ethtool
sar -n DEV 1 10
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
怀疑网络存在瓶颈,可以使用sar –n DEV 来进行查看。
yum install -y epel-release
yum install nload
nload 回车后查看网卡流量,动态显示
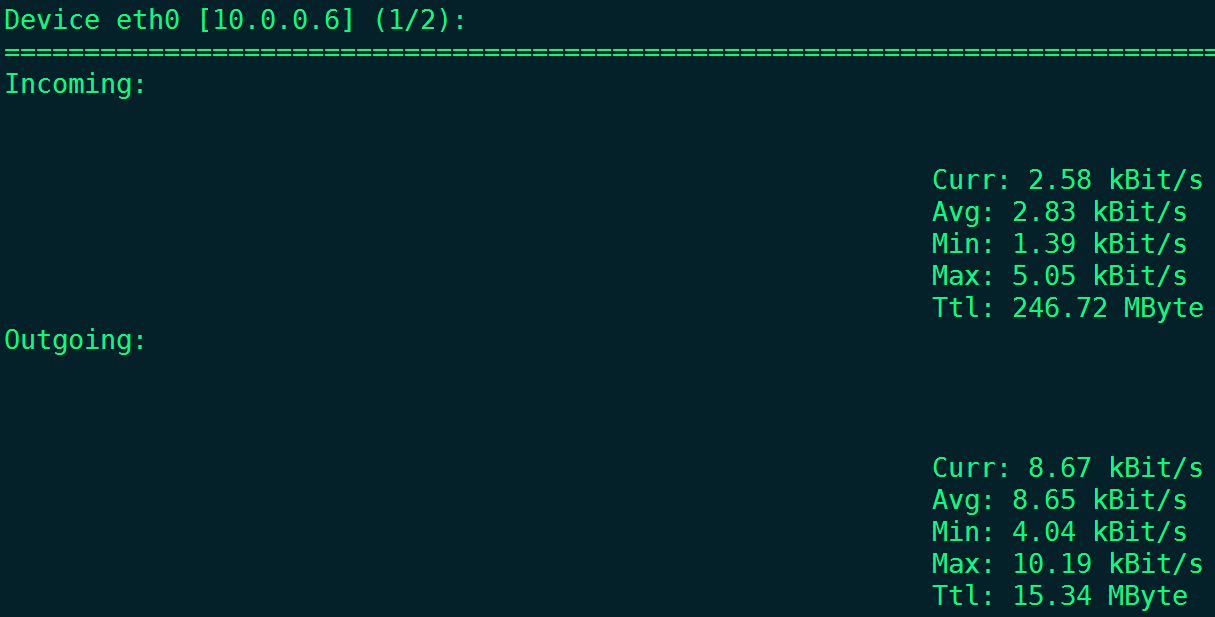
扩展:
nload 默认分为上下两块(如上图):
上半部分是:Incoming也就是进入网卡的流量,
下半部分是:Outgoing,也就是从这块网卡出去的流量,
每部分都有当前流量(Curr),
平均流量(Avg),
最小流量(Min),
最大流量(Max),
总和流量(Ttl)
nload默认的是eth0网卡,如果你想监测eth1网卡的流量#nload eth1
---------------------
ethtool ens33 #查看网卡信息
ethtool --identify eth2 20
这个意思是说,让eth2标识的网卡的灯点亮20秒!如果网卡标号与网卡实际的物理位置关系乱了,你又不知道eth2是哪个网卡,上述网卡点灯程序就会让你知道了。
mii-tool ens33 #查看网卡硬件信息
查看进程 ps,top
ps aux 、 ps -elf 、
ps -eLf (查看线程)
top –Hp pid号 (查看线程)
STAT
S Sleep
R Running
s 父进程
N 低优先级
< 高优先级
- 前台进程
l 多线程进程
Z 僵尸进程
ls -l /proc/pid号/ #查看一个进程的一些详细信息
查看网络连接状况:
netstat -lnp 、netstat -lntp 、 netstat -lntup
netstat -an
ss -an
抓包工具 tcpdump,wireshark
wireshark (安装:yum install -y wireshark)
tshark -i ens33 -n -t a -R http.request -T fields -e "frame.time" -e "ip.src" -e
"http.host" -e "http.request.method" -e "http.request.uri"
补充:
查看cpu核数
cat /proc/cpuinfo
lscpu
buffer和cached 详解
buffer : 这部分内存是从CPU产生即将写入到磁盘里去的那部分数据;
cached 这部分数据是先从磁盘里读出来,然 后临时存到内存里的那部分数据,
小常识:
bit 比特(带宽单位)
Byte 字节 (速度传输单位)
8bit = 1Byte 2MB/s 2*8=16Mbit 100Mbit 12.8MB/s
抓包工具tcpdump用法说明
tcpdump (安装:yum install -y tcpdump)
tcpdump -nn -i ens33 port 80
tcpdump -nn -i ens33 -c 100 -w 1.cap
tcpdump -i ens33 -nn not port 22 and not port 80 and not host 192.168.222.1
tcpdump -nn -r 1.cap
tcpdump采用命令行方式对接口的数据包进行筛选抓取,其丰富特性表现在灵活的表达式上。
不带任何选项的tcpdump,默认会抓取第一个网络接口,且只有将tcpdump进程终止才会停止抓包。
例如:
shell> tcpdump -nn -i eth0 icmp
下面是详细的tcpdump用法。
1.1 tcpdump选项
它的命令格式为:
tcpdump [ -DenNqvX ] [ -c count ] [ -F file ] [ -i interface ] [ -r file ] [ -s
snaplen ] [ -w file ] [ expression ]
抓包选项:
-c:指定要抓取的包数量。注意,是最终要获取这么多个包。例如,指定"-c
10"将获取10个包,但可能已经处理了100个包,只不过只有10个包是满足条件的包。
-i
interface:指定tcpdump需要监听的接口。若未指定该选项,将从系统接口列表中搜寻编号最小的已配置好的接口(不包括loopback接口,要抓取loopback接口使用tcpdump
-i
lo),一旦找到第一个符合条件的接口,搜寻马上结束。可以使用'any'关键字表示所有网络接口。
-n:对地址以数字方式显式,否则显式为主机名,也就是说-n选项不做主机名解析。
-nn:除了-n的作用外,还把端口显示为数值,否则显示端口服务名。
-N:不打印出host的域名部分。例如tcpdump将会打印'nic'而不是'nic.ddn.mil'。
-P:指定要抓取的包是流入还是流出的包。可以给定的值为"in"、"out"和"inout",默认为"inout"。
-s
len:设置tcpdump的数据包抓取长度为len,如果不设置默认将会是65535字节。对于要抓取的数据包较大时,长度设置不够可能会产生包截断,若出现包截断,输出行中会出现"[|proto]"的标志(proto实际会显示为协议名)。但是抓取len越长,包的处理时间越长,并且会减少tcpdump可缓存的数据包的数量,从而会导致数据包的丢失,所以在能抓取我们想要的包的前提下,抓取长度越小越好。
输出选项:
-e:输出的每行中都将包括数据链路层头部信息,例如源MAC和目标MAC。
-q:快速打印输出。即打印很少的协议相关信息,从而输出行都比较简短。
-X:输出包的头部数据,会以16进制和ASCII两种方式同时输出。
-XX:输出包的头部数据,会以16进制和ASCII两种方式同时输出,更详细。
-v:当分析和打印的时候,产生详细的输出。
-vv:产生比-v更详细的输出。
-vvv:产生比-vv更详细的输出。
其他功能性选项:
-D:列出可用于抓包的接口。将会列出接口的数值编号和接口名,它们都可以用于"-i"后。
-F:从文件中读取抓包的表达式。若使用该选项,则命令行中给定的其他表达式都将失效。
-w:将抓包数据输出到文件中而不是标准输出。可以同时配合"-G
time"选项使得输出文件每time秒就自动切换到另一个文件。可通过"-r"选项载入这些文件以进行分析和打印。
-r:从给定的数据包文件中读取数据。使用"-"表示从标准输入中读取。
所以常用的选项也就这几个:
tcpdump -D
tcpdump -c num -i int -nn -XX –vvv
1.2 tcpdump表达式
表达式用于筛选输出哪些类型的数据包,如果没有给定表达式,所有的数据包都将输出,否则只输出表达式为true的包。在表达式中出现的shell元字符建议使用单引号包围。
tcpdump的表达式由一个或多个"单元"组成,每个单元一般包含ID的修饰符和一个ID(数字或名称)。
有三种修饰符:
(1).type:指定ID的类型。
可以给定的值有host/net/port/portrange。例如"host foo","net 128.3","port
20","portrange 6000-6008"。默认的type为host。
(2).dir:指定ID的方向。
可以给定的值包括src/dst/src or dst/src and dst,默认为src or dst。例如,"src
foo"表示源主机为foo的数据包,"dst net 128.3"表示目标网络为128.3的数据包,"src or
dst port 22"表示源或目的端口为22的数据包。
(3).proto:通过给定协议限定匹配的数据包类型。
常用的协议有tcp/udp/arp/ip/ether/icmp等,若未给定协议类型,则匹配所有可能的类型。例如"tcp
port 21","udp portrange 7000-7009"。
所以,一个基本的表达式单元格式为"proto dir type ID"

除了使用修饰符和ID组成的表达式单元,还有关键字表达式单元:gateway,broadcast,less,greater以及算术表达式。
表达式单元之间可以使用操作符" and / && / or / || / not / !
"进行连接,从而组成复杂的条件表达式。如"host foo and not port ftp and not port
ftp-data",这表示筛选的数据包要满足"主机为foo且端口不是ftp(端口21)和ftp-data(端口20)的包",常用端口和名字的对应关系可在linux系统中的/etc/service文件中找到。
另外,同样的修饰符可省略,如"tcp dst port ftp or ftp-data or domain"与"tcp dst
port ftp or tcp dst port ftp-data or tcp dst port
domain"意义相同,都表示包的协议为tcp且目的端口为ftp或ftp-data或domain(端口53)。
使用括号"()"可以改变表达式的优先级,但需要注意的是括号会被shell解释,所以应该使用反斜线""转义为"()",在需要的时候,还需要包围在引号中。
1.3 tcpdump示例
注意,tcpdump只能抓取流经本机的数据包。
(1).默认启动
tcpdump
默认情况下,直接启动tcpdump将监视第一个网络接口(非lo口)上所有流通的数据包。这样抓取的结果会非常多,滚动非常快。
(2).监视指定网络接口的数据包
tcpdump -i eth1
如果不指定网卡,默认tcpdump只会监视第一个网络接口,如eth0。
(3).监视指定主机的数据包,例如所有进入或离开longshuai的数据包
tcpdump host longshuai
(4).打印helios<-->hot或helios<-->ace之间通信的数据包
tcpdump host helios and ( hot or ace )
(5).打印ace与任何其他主机之间通信的IP数据包,但不包括与helios之间的数据包
tcpdump ip host ace and not helios
(6).截获主机hostname发送的所有数据
tcpdump src host hostname
(7).监视所有发送到主机hostname的数据包
tcpdump dst host hostname
(8).监视指定主机和端口的数据包
tcpdump tcp port 22 and host hostname
(9).对本机的udp 123端口进行监视(123为ntp的服务端口)
tcpdump udp port 123
(10).监视指定网络的数据包,如本机与192.168网段通信的数据包,"-c
10"表示只抓取10个包
tcpdump -c 10 net 192.168
(11).打印所有通过网关snup的ftp数据包(注意,表达式被单引号括起来了,这可以防止shell对其中的括号进行错误解析)
shell> tcpdump 'gateway snup and (port ftp or ftp-data)'
(12).抓取ping包
[root@server2 ~]# tcpdump -c 5 -nn -i eth0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
12:11:23.273638 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16422, seq 10, length 64
12:11:23.273666 IP 192.168.100.62 > 192.168.100.70: ICMP echo reply, id 16422,
seq 10, length 64
12:11:24.356915 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16422, seq 11, length 64
12:11:24.356936 IP 192.168.100.62 > 192.168.100.70: ICMP echo reply, id 16422,
seq 11, length 64
12:11:25.440887 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16422, seq 12, length 64
5 packets captured
6 packets received by filter
0 packets dropped by kernel
如果明确要抓取主机为192.168.100.70对本机的ping,则使用and操作符。
[root@server2 ~]# tcpdump -c 5 -nn -i eth0 icmp and src 192.168.100.62
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
12:09:29.957132 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16166, seq 1, length 64
12:09:31.041035 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16166, seq 2, length 64
12:09:32.124562 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16166, seq 3, length 64
12:09:33.208514 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16166, seq 4, length 64
12:09:34.292222 IP 192.168.100.70 > 192.168.100.62: ICMP echo request, id
16166, seq 5, length 64
5 packets captured
5 packets received by filter
0 packets dropped by kernel
注意不能直接写icmp src 192.168.100.70,因为icmp协议不支持直接应用host这个type。
(13).抓取到本机22端口包
[root@server2 ~]# tcpdump -c 10 -nn -i eth0 tcp dst port 22
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
12:06:57.574293 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack
535528834, win 2053, length 0
12:06:57.629125 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 193,
win 2052, length 0
12:06:57.684688 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 385,
win 2051, length 0
12:06:57.738977 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 577,
win 2050, length 0
12:06:57.794305 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 769,
win 2050, length 0
12:06:57.848720 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 961,
win 2049, length 0
12:06:57.904057 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 1153,
win 2048, length 0
12:06:57.958477 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 1345,
win 2047, length 0
12:06:58.014338 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 1537,
win 2053, length 0
12:06:58.069361 IP 192.168.100.1.5788 > 192.168.100.62.22: Flags [.], ack 1729,
win 2052, length 0
10 packets captured
10 packets received by filter
0 packets dropped by kernel
(14).解析包数据
[root@server2 ~]# tcpdump -c 2 -q -XX -vvv -nn -i eth0 tcp dst port 22
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 65535
bytes
12:15:54.788812 IP (tos 0x0, ttl 64, id 19303, offset 0, flags [DF], proto TCP
(6), length 40)
192.168.100.1.5788 > 192.168.100.62.22: tcp 0
0x0000: 000c 2908 9234 0050 56c0 0008 0800 4500 ..)..4.PV.....E.
0x0010: 0028 4b67 4000 4006 a5d8 c0a8 6401 c0a8 .(Kg@.@.....d...
0x0020: 643e 169c 0016 2426 5fd6 1fec 2b62 5010 d>....$&_...+bP.
0x0030: 0803 7844 0000 0000 0000 0000 ..xD........
12:15:54.842641 IP (tos 0x0, ttl 64, id 19304, offset 0, flags [DF], proto TCP
(6), length 40)
192.168.100.1.5788 > 192.168.100.62.22: tcp 0
0x0000: 000c 2908 9234 0050 56c0 0008 0800 4500 ..)..4.PV.....E.
0x0010: 0028 4b68 4000 4006 a5d7 c0a8 6401 c0a8 .(Kh@.@.....d...
0x0020: 643e 169c 0016 2426 5fd6 1fec 2d62 5010 d>....$&_...-bP.
0x0030: 0801 7646 0000 0000 0000 0000 ..vF........
2 packets captured
2 packets received by filter
0 packets dropped by kernel
总的来说,tcpdump对基本的数据包抓取方法还是较简单的。只要掌握有限的几个选项(-nn
-XX -vvv -i -c -q),再组合表达式即可。
- Http 访问分析命令curl
- Curl 的实战案例测试详解
curl语法结构如下:
curl [options...] <url>
常用选项:
-v 详细输出,包含请求和响应的首部
-o test 将指定curl返回保存为test文件,内容从html/jpg到各种MIME类型文件
-O 把输出写到该文件中,保留远程文件的文件名
-C 在保存文件时进行续传
-x ip:port 指定使用的http代理
-c <file> 保存服务器的cookie文件
-H <header:value> 为HTTP请求设置任意header及值
-L 跟随重定向
-S 显示错误信息
-s 静默模式,不输出任何信息
-G 以get的方式发送数据
-f 连接失败是不显示http错误
-d 以post方式传送数据
-A 自定义 User-Agent
实例:
- 获取页面内容
当我们不加任何选项使用 curl 时,默认会发送 GET 请求来获取链接内容到标准输出。
curl http://www.codebelief.com
- 显示 HTTP 头
如果我们只想要显示 HTTP 头,而不显示文件内容,可以使用 -I 选项:
curl -I http://www.codebelief.com
输出为:
HTTP/1.1 200 OK
Server: nginx/1.10.3
Date: Thu, 11 May 2017 08:24:45 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 24206
Connection: keep-alive
X-Powered-By: Express
Cache-Control: public, max-age=0
ETag: W/"5e8e-Yw5ZdnVVly9/aEnMX7fVXQ"
Vary: Accept-Encoding
也可以同时显示 HTTP 头和文件内容,使用 -i 选项:
curl -i http://www.codebelief.com
输出为:
HTTP/1.1 200 OK
Server: nginx/1.10.3
Date: Thu, 11 May 2017 08:25:46 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 24206
Connection: keep-alive
X-Powered-By: Express
Cache-Control: public, max-age=0
ETag: W/"5e8e-Yw5ZdnVVly9/aEnMX7fVXQ"
Vary: Accept-Encoding
<!DOCTYPE html>
<html lang="en">
......
</html>
- 将链接保存到文件
我们可以使用 > 符号将输出重定向到本地文件中。
curl http://www.codebelief.com > index.html
也可以通过 curl 自带的 -o/-O 选项将内容保存到文件中。
-o(小写的 o):结果会被保存到命令行中提供的文件名
-O(大写的 O):URL 中的文件名会被用作保存输出的文件名
curl -o index.html http://www.codebelief.com
curl -O http://www.codebelief.com/page/2/
注意:使用 -O 选项时,必须确保链接末尾包含文件名,否则 curl
无法正确保存文件。如果遇到链接中无文件名的情况,应该使用 -o
选项手动指定文件名,或使用重定向符号。
- 同时下载多个文件
我们可以使用 -o 或 -O 选项来同时指定多个链接,按照以下格式编写命令:
curl -O http://www.codebelief.com/page/2/ -O http://www.codebelief.com/page/3/
或者:
curl -o page1.html http://www.codebelief.com/page/1/ -o page2.html
http://www.codebelief.com/page/2/
- 使用 -L 跟随链接重定向
如果直接使用 curl
打开某些被重定向后的链接,这种情况下就无法获取我们想要的网页内容。例如:
会得到如下提示:
<html>
<head><title>301 Moved Permanently</title></head>
<body bgcolor="white">
<center><h1>301 Moved Permanently</h1></center>
<hr><center>nginx/1.10.3</center>
</body>
</html>
而当我们通过浏览器打开该链接时,会自动跳转到
http://www.codebelief.com。此时我们想要 curl
做的,就是像浏览器一样跟随链接的跳转,获取最终的网页内容。我们可以在命令中添加
-L 选项来跟随链接重定向:
curl -L http://codebelief.com
这样我们就能获取到经过重定向后的网页内容了。
- 使用 -A 自定义 User-Agent
我们可以使用 -A
来自定义用户代理,例如下面的命令将伪装成安卓火狐浏览器对网页进行请求:
curl -A "Mozilla/5.0 (Android; Mobile; rv:35.0) Gecko/35.0 Firefox/35.0"
http://www.baidu.com
下面我们会使用 -H 来实现同样的目的。
- 使用 -H 自定义 header
当我们需要传递特定的 header 的时候,可以仿照以下命令来写
curl -H "Referer: www.example.com" -H "User-Agent: Custom-User-Agent"
http://192.168.0.215

可以看到,当我们使用 -H 来自定义 User-Agent 时,需要使用 "User-Agent: xxx"
的格式。
我们能够直接在 header 中传递 Cookie,格式与上面的例子一样:
curl -H "Cookie: JSESSIONID=D0112A5063D938586B659EF8F939BE24"
http://www.example.com
另一种方式会在下面介绍。
- 使用 -c 保存 Cookie
当我们使用 cURL 访问页面的时候,默认是不会保存 Cookie 的。有些情况下我们希望保存
Cookie
以便下次访问时使用。例如登陆了某个网站,我们希望再次访问该网站时保持登陆的状态,这时就可以现将登陆时的
Cookie 保存起来,下次访问时再读取。
-c 后面跟上要保存的文件名。
curl -c "cookie-example" http://www.example.com
- 使用 -b 读取 Cookie
前面讲到了使用 -H 来发送 Cookie 的方法,这种方式是直接将 Cookie
字符串写在命令中。如果使用 -b 来自定义 Cookie,命令如下:
curl -b "JSESSIONID=D0112A5063D938586B659EF8F939BE24" http://www.example.com
如果要从文件中读取 Cookie,-H 就无能为力了,此时可以使用 -b 来达到这一目的:
curl -b "cookie-example" http://www.example.com
即 -b 后面既可以是 Cookie 字符串,也可以是保存了 Cookie 的文件名。
- 使用 -d 发送 POST 请求
我们以登陆网页为例来进行说明使用 curl 发送 POST 请求的方法。假设有一个登录页面
www.example.com/login,只需要提交用户名和密码便可登录。我们可以使用 cURL
来完成这一 POST 请求,-d 用于指定发送的数据,-X 用于指定发送数据的方式:
curl -d "userName=tom&passwd=123456" -X POST http://www.example.com/login
在使用 -d 的情况下,如果省略 -X,则默认为 POST 方式:
curl -d "userName=tom&passwd=123456" http://www.example.com/login
强制使用 GET 方式
发送数据时,不仅可以使用 POST 方式,也可以使用 GET 方式,例如:
curl -d "somedata" -X GET http://www.example.com/api
或者使用 -G 选项:
curl -d "somedata" -G http://www.example.com/api
从文件中读取 data
curl -d "@data.txt" http://www.example.com/login
带 Cookie 登录
当然,如果我们再次访问该网站,仍然会变成未登录的状态。我们可以用之前提到的方法保存
Cookie,在每次访问网站时都带上该 Cookie 以保持登录状态。
curl -c "cookie-login" -d "userName=tom&passwd=123456"
http://www.example.com/login
再次访问该网站时,使用以下命令:
curl -b "cookie-login" http://www.example.com/login
这样,就能保持访问的是登录后的页面了。
curl命令来路伪装(referer)和浏览器伪装(user-agent)
一般的知名站点,都有一套比较完善的机器流量检测系统;它通过流量的IP、流量的来源、使用的浏览设备、访问频次、用户行为等综合分析,来判断当前流量是真实的用户流量,还是机器在爬网站的数据,从而做出是否封禁当前流量的决定。第三方统计站点,也是使用此原理来帮助站长统计用户行文的。
而其中的流量来源、使用的浏览设备、甚至流量的IP都是可以伪造的。本文为介绍curl伪装访问来源、和伪装使用的浏览器的方法。伪装来路IP地址,请参考“linux
curl命令使用代理服务器”。
一、原理说明:
浏览器与http服务器是通过http协议通讯的,而http请求头中包含了客户端的一些信息,其中包括:浏览器类型、当前页面的来源页面,cookies等;
下面我们来看看一个标准的http请求头后响应头:
[root@localhost.com ~]# curl -v -I --referer http://baidu.com --user-agent
'Chrome/54.0 (Windows NT 10.0)' http://baidu.com/
* About to connect() to baidu.com port 80 (#0)
* Trying 180.149.132.47...
* Connected to baidu.com (180.149.132.47) port 80 (#0)
> HEAD / HTTP/1.1
> User-Agent: Chrome/54.0 (Windows NT 10.0)
> Host: baidu.com
> Accept: */*
> Referer: http://baidu.com
>
< HTTP/1.1 302 Moved Temporarily
HTTP/1.1 302 Moved Temporarily
< Server: bfe/1.0.8.18
Server: bfe/1.0.8.18
< Date: Fri, 02 Dec 2016 03:46:11 GMT
Date: Fri, 02 Dec 2016 03:46:11 GMT
< Content-Type: text/html
Content-Type: text/html
< Content-Length: 161
Content-Length: 161
< Connection: Keep-Alive
Connection: Keep-Alive
< Location: https://www.baidu.com/
Location: https://www.baidu.com/
< Expires: Sat, 03 Dec 2016 03:46:11 GMT
Expires: Sat, 03 Dec 2016 03:46:11 GMT
< Cache-Control: max-age=86400
Cache-Control: max-age=86400
< Cache-Control: private
Cache-Control: private
<
* Connection #0 to host baidu.com left intact
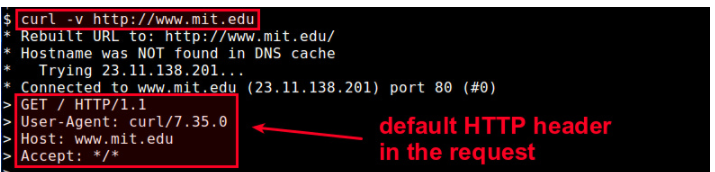
-A (or --user-agent): 设置 "User-Agent" 字段.
-b (or --cookie): 设置 "Cookie" 字段.
-e (or --referer): 设置 "Referer" 字段.
上面输出可以看到,第7行和第9行就是我们设置的浏览器类型字符串和流量来源页面。而httpd服务端接收到了什么呢?我们这里以http服务段使用的是PHP为例,在站点上做一个“test.php”做为测试页面,PHP的Referer、User-Agent存放在$_SERVER变量中,所以我们的“test.php”文件只需要两行代码:
test.php文件:
<?php
print_r($_SERVER);
测试返回:
[root@localhost tmp]# curl --referer http://baidu.com --user-agent
'Chrome/54.0 (Windows NT 10.0)' http://localhost.com/test.php
Array
(
[HTTP_USER_AGENT] => Chrome/54.0 (Windows NT 10.0)
[HTTP_HOST] => localhost.com
[HTTP_ACCEPT] => */*
[HTTP_REFERER] => http://baidu.com
[PATH] => /sbin:/usr/sbin:/bin:/usr/bin
...
[REQUEST_METHOD] => GET
...
[PHP_SELF] => /test.php
[REQUEST_TIME] => 1480651125
)
二、伪装来路(referer):
什么是来路?从A页面点击进入B页面,那B页面的来路就是A页面的URL。伪装来路十分简单,有两种方法:1、使用上面的“--referer”参数或“-e参数”;2、直接使用“-H”参数设置http头,下面分别介绍两种方法。
1、“-e/--referer”参数方式:
# 告诉http服务器,我是从qq.com来的
[root@localhost.com ~]# curl -e http://qq.com http://localhost.com/test.php
2>/dev/null|grep HTTP_REFERER
[HTTP_REFERER] => http://qq.com
# 告诉http服务器,我是从baidu.com搜"localhost"关键词点进来的
[root@localhost.com ~]# curl --referer https://www.baidu.com/s?wd=localhost
http://localhost.com/test.php 2>/dev/null|grep HTTP_REFERER
[HTTP_REFERER] => https://www.baidu.com/s?wd=localhost
2、“-H”参数的方式:
# 告诉http服务器,我是从微博过来的
[root@localhost ~]# curl -H "Referer: http://weibo.com"
http://localhost.com/test.php 2>/dev/null|grep HTTP_REFERER
[HTTP_REFERER] => http://weibo.com
三、伪装浏览器类型(User-Agent):
首先,我们先找到浏览器对应的“User-Agent”字符串。可以直接在Chrome中的“开发者工具”的“网络”标签查看http请求头获得;也可以在网上搜索获得,如通过百度搜索“微信useragent”、“ie
useragent”、“chrome useragent”等。
获得对应浏览器的“User-Agent”字符串后,同样可以通过两种方式告诉http服务器我用的浏览器类型:
1、“-A/--user-agent”参数方式:
# 告诉http服务器,我是通过微信内置浏览器访问
[root@localhost.com ~]# UA='Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac
OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Mobile/12A365 MicroMessenger/6.0
NetType/WIFI';
[root@localhost.com ~]# curl -A "$UA" http://localhost.com/test.php|grep
HTTP_USER_AGENT
[HTTP_USER_AGENT] => Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X)
AppleWebKit/600.1.4 (KHTML, like Gecko) Mobile/12A365 MicroMessenger/6.0
NetType/WIFI
# 告诉http服务器,我是通过Chrome浏览器访问
[root@localhost.com ~]# UA='Mozilla/5.0 (Windows NT 6.2; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36';
[root@localhost.com ~]# curl --user-agent "$UA"
http://localhost.com/test.php|grep HTTP_USER_AGENT
[HTTP_USER_AGENT] => Mozilla/5.0 (Windows NT 6.2; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36
2、“-H”参数方式:
# 告诉网站,我是百度蜘蛛爬取
[root@localhost.com ~]# UA="Mozilla/5.0 (compatible; Baiduspider/2.0;
+http://www.baidu.com/search/spider.html)";
[root@localhost.com ~]# curl -H "User-Agent: $UA"
http://localhost.com/a.php|grep HTTP_USER_AGENT
[HTTP_USER_AGENT] => Mozilla/5.0 (compatible; Baiduspider/2.0;
+http://www.baidu.com/search/spider.html)