ES核心概念和原理
ElasticSearch作为目前比较流行的企业级搜索引擎框架,在面试和工作的比重越来越大,掌握ES将会让你去大厂面试的成功率大大提高,因此笔者将从ES的使用到ES核心原理到核心源码,逐步讲解深入剖析,从概念到代码的实现都尽量解释的清楚,那么最后将会做一个完整的搜索引擎项目,当然因作者能力有限,难免有错误之处,烦请指正,谢谢
1、什么是搜索:
早期的搜索引擎是把因特网中的资源服务器的地址收集起来,由其提供的资源的类型不同而分成不同的目录,再一层层地进行分类。人们要找自己想要的信息可按他们的分类一层层进入,就能最后到达目的地,找到自己想要的信息。这其实是最原始的方式,只适用于因特网信息并不多的时候。随着因特网信息按几何式增长,出现了真正意义上的搜索引擎,这些搜索引擎知道网站上每一页的开始,随后搜索因特网上的所有超级链接,把代表超级链接的所有词汇放入一个数据库。这就是搜索引擎的原型。
搜索:通过一个关键词或一段描述,得到你想要的(相关度高)结果。
2、如何实现搜索功能?
可以使用关系型数据库来进行处理,例如MySQL,但是同样会有很多的问题让我们不得不去考虑其他实现方式,比如性能差、不可靠、结果不准确(相关度低)
3、倒排索引、Lucene和全文检索?
倒排索引
What is it?
首先我们看看数据库中的索引分布。
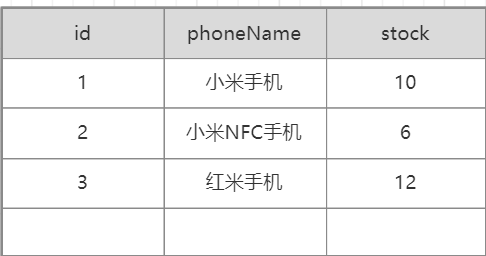
ok,这是我们数据库索引的一张表,我们看到有三种手机,小米手机、小米NFC手机、红米手机,按照id1、2、3来进行排列
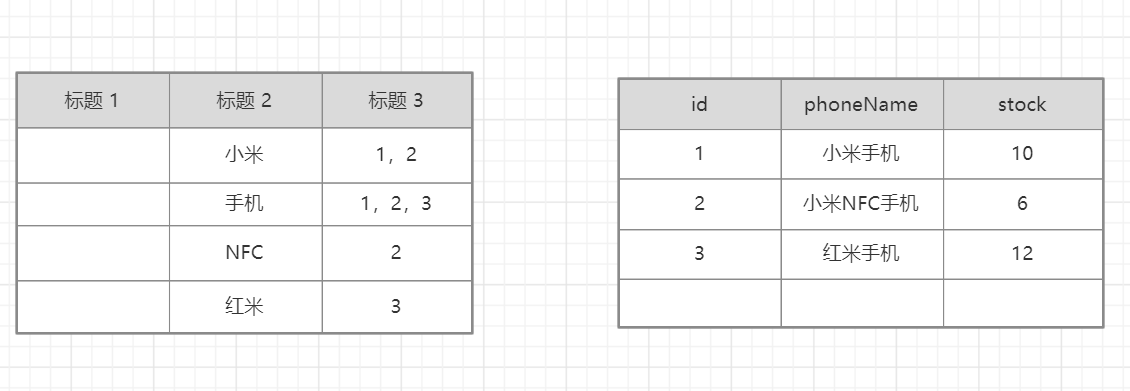
在这张图里,小米出现的次数是在id为1、2之中,手机在123中均出现,NFC和红米也如此排列,这就是倒排索引
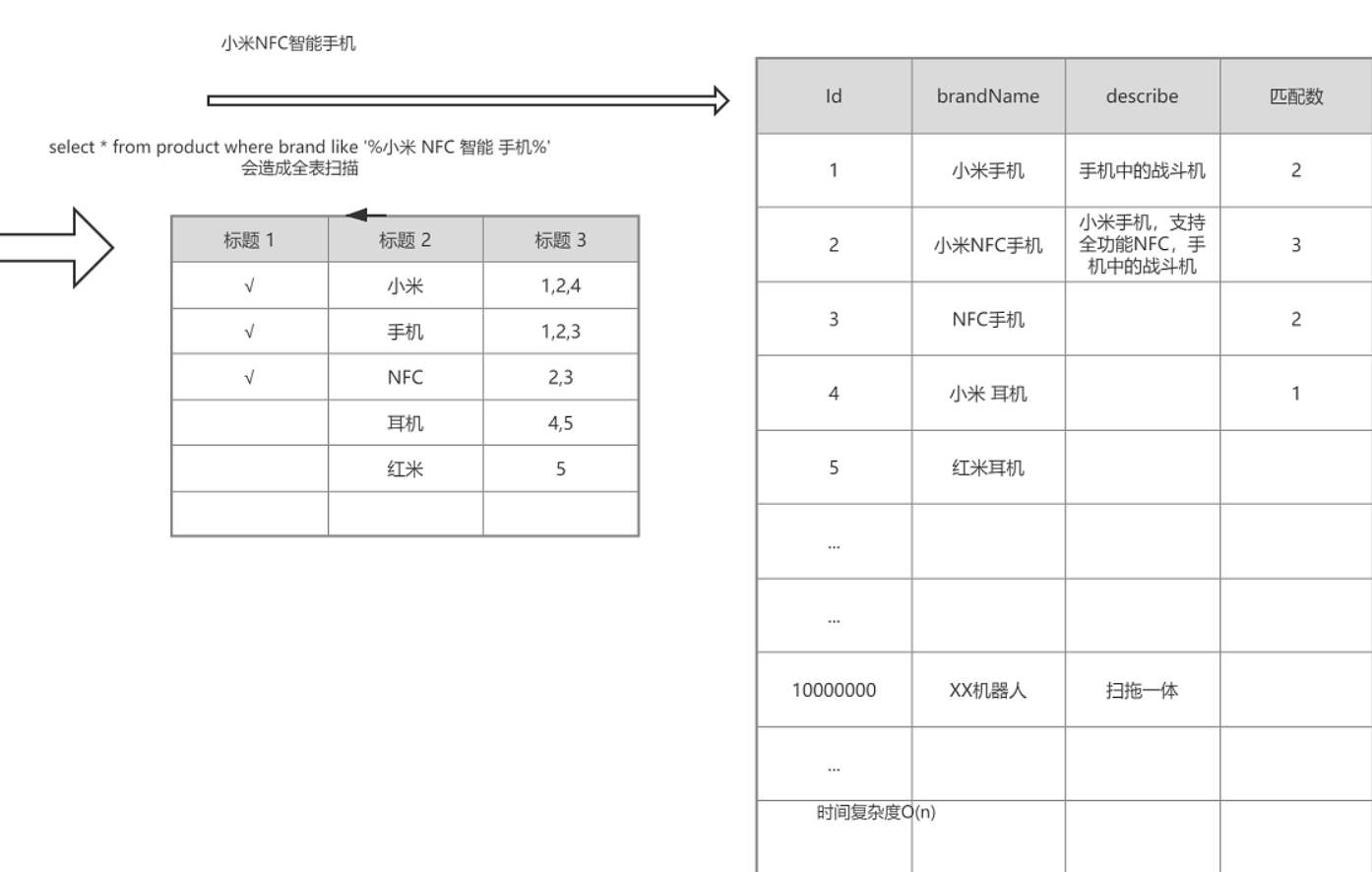
那么在我们的select * from product where brand like '%小米 NFC 智能 手机'之中,小米、手机、NFC是会被匹配到的。小米手机在我们匹配到的结果中是出现了2次,小米NFC手机出现了3次...后面的依次按照该规律进行排列。匹配数字其实就是我们所谓的相关度,那么小米NFC手机出现了3次,那么它的相关度就是3,是最大的,那么就可能是我们最想要的结果,即这就是倒排索引最简单的一个demo,那么以后我们会对其进行更深入的讲解,目前了解有个认识即可。
数据结构:
- 包含这个关键词的document list (理解为表中一行)
- 关键词在每个doc中出现的次数 TF term frequency
- 关键词在整个索引中出现的次数 IDF inverse doc frequency
- 关键词在当前doc中出现的次数
- 每个doc的长度,越长相关度越低
- 包含这个关键词的所有doc的平均长度
Lucene:
就是一个jar包,帮我们创建倒排索引,提供了复杂的API
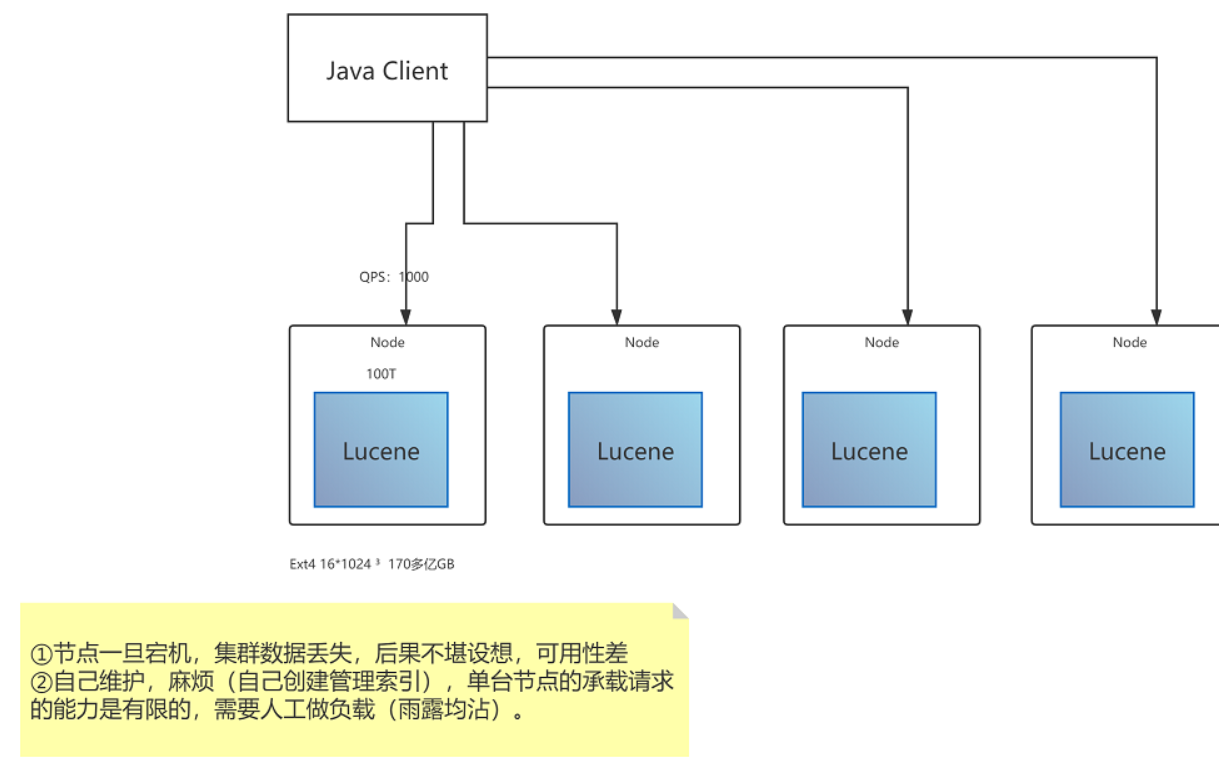
Lucene集群问题
如果用Lucene做集群实现搜索,会有那些问题?
① 节点一旦宕机,节点数据丢失,后果不堪设想,可用性差。
② 自己维护,麻烦(自己创建管理索引),单台节点的承载请求的能力是有限的,需要人工做负载(雨露均沾)。
4、Elasticsearch
分布式、高性能、高可用、可伸缩、易维护
But!! ES≠搜索引擎
(1) 分布式
分布式的搜索,存储和数据分析引擎:
(2) 优点:
① 面向开发者友好,屏蔽了Lucene的复杂特性,集群自动发现(cluster discovery)
② 自动维护数据在多个节点上的建立
③ 会帮我做搜索请求的负载均衡
④ 自动维护冗余副本,保证了部分节点宕机的情况下仍然不会有任何数据丢失
⑤ ES基于Lucene提供了很多高级功能:复合查询、聚合分析、基于地理位置等。
⑥ 对于大公司,可以构建几百台服务器的大型分布式集群,处理PB级别数据;对于小公司,开箱即用,门槛低上手简单。
⑦ 相遇传统数据库,提供了全文检索,同义词处理(美丽的cls>漂亮的cls),相关度排名。聚合分析以及海量数据的近实时(NTR)处理,这些传统数据库完全做不到。
(3) 应用领域:
① 百度(全文检索、高亮、搜索推荐)
② 各大网站的用户行为日志(用户点击、浏览、收藏、评论)
③ BI(Business Intelligence商业智能),数据分析:数据挖掘统计。
④ Github:代码托管平台,几千亿行代码
⑤ ELK:Elasticsearch(数据存储)、Logstash(日志采集)、Kibana(可视化)
5、ES核心概念:
(1) cluster(集群):每个集群至少包含两个节点.
(2) node:集群中的每个节点,一个节点不代表一台服务器
(3) field:一个数据字段,与index和type一起,可以定位一个doc
(4) document:ES最小的数据单元 Json
{
"id": "1",
"name": "小米",
"price": {
"标准版": 3999,
"尊享版": 4999,
"吴磊签名定制版": 19999
}
}
Type:逻辑上的数据分类,es 7.x中删除了type的概念
Index:一类相同或者类似的doc,比如一个员工索引,商品索引。
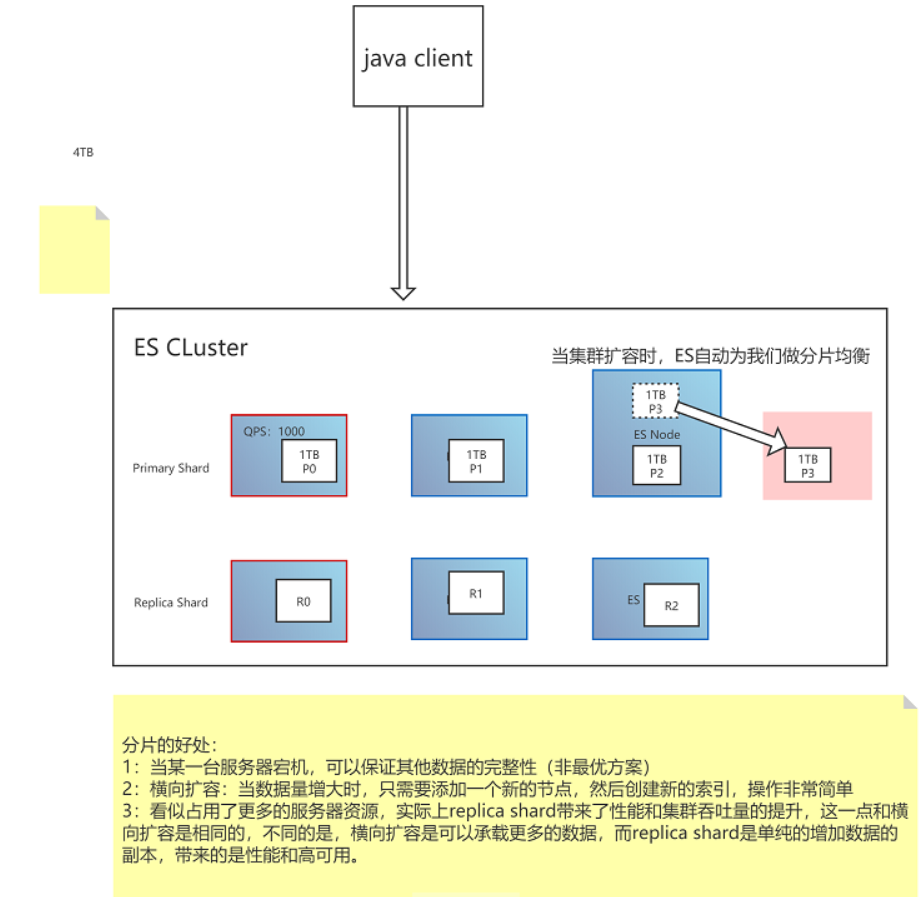
6.Shard分片:
1:一个index包含多个Shard,默认5P,默认每个P分配一个R,P的数量在创建索引的时候设置,如果想修改,需要重建索引。
2:每个Shard都是一个Lucene实例,有完整的创建索引的处理请求能力。
3:ES会自动在nodes上为我们做shard 均衡。
4:一个doc是不可能同时存在于多个PShard中的,但是可以存在于多个RShard中。
5: P和对应的R不能同时存在于同一个节点,所以最低的可用配置是两个节点,互为主备。
分片