一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | 900 | 740 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 60 | 30 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 120 | 30 |
| · Coding | · 具体编码 | 360 | 360 |
| · Code Review | · 代码复审 | 120 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 90 | 90 |
| Reporting | 报告 | 120 | 140 |
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 40 |
| · 合计 | 1020 | 910 |
二、计算模块接口
1) 计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
算法关键是DFA算法
First.在程序里接受命令行参数
- 读入敏感词词汇文件和待检测文件,将其中的内容转化为字符串,敏感词生成的字符串用于传到
public Map WordsHashMap(Set<String> keyWords)函数中生成哈希树。
public class InputFile {
public static String inputfile(String name) throws IOException {
/*Scanner scanner = new Scanner(System.in);
String name = scanner.nextLine();*/
File f = new File(name);
FileInputStream word=new FileInputStream(f);
InputStreamReader wordreader=new InputStreamReader(word,"UTF-8");
BufferedReader reader = new BufferedReader(wordreader);//将文件通过绝对路径读出文件
String br =null;
String bt ="";
while ((br = reader.readLine()) != null) {//按行读取
bt+=br;//按行读入
bt+='
';
}//将文本转换为字符串
return bt;
}
- 将答案放到读出文件中
public class OutputFile {
public OutputFile() {
}
public static void rwFile(String file, String filepath) {
FileWriter fw = null;
try {
fw = new FileWriter(filepath, true);
fw.write(file);
fw.flush();
} catch (FileNotFoundException var14) {
var14.printStackTrace();
} catch (IOException var15) {
var15.printStackTrace();
} finally {
if (fw != null) {
try {
fw.close();
} catch (IOException var13) {
var13.printStackTrace();
}
}
}
}
}
Second.敏感词检测
- 构造敏感词
public class AddSensitiveWords {
public Set<String> addSensitiveWords(String[] ss)throws PinyinException{
Set<String>set = new HashSet<>();
/*System.out.println(sword.toString());*/
int j= ss.length;
for(int i=0;i<j;i++){
set.add(ss[i]);
}
for(int i=0;i<j;i++){
String word=ss[i];
/* System.out.println(ss[i]);*/
char key=word.charAt(0);
if(ChineseHelper.isChinese(key)){
set.add(PinyinHelper.convertToPinyinString(ss[i],"", PinyinFormat.WITHOUT_TONE));//将中文转化成拼音
/*System.out.println(PinyinHelper.convertToPinyinString(ss[i],"", PinyinFormat.WITHOUT_TONE));*/
set.add(PinyinHelper.getShortPinyin(ss[i]));//将中文转换成拼音开头缩写
}
}//将转化后的新增词汇加入set当中
return set;
}
}
- 实现敏感词查询
- 最简易实现,计算总个数,检测出与给出的敏感词文件完全相同的形式的词汇
- 查找英文敏感词的大小写形式
public boolean isContaintSensitiveWord(String txt, int matchType)
public List<String> getSensitiveWord(String txt, int matchType)
public int CheckSensitiveWord(String txt, int beginIndex, int matchType)
- 输出个数、行数、敏感词原型
Final.打包——jar包

2) 计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。


消耗较大的是一些树的生成,可通过减少结点或者最小路径算法来简化算法。
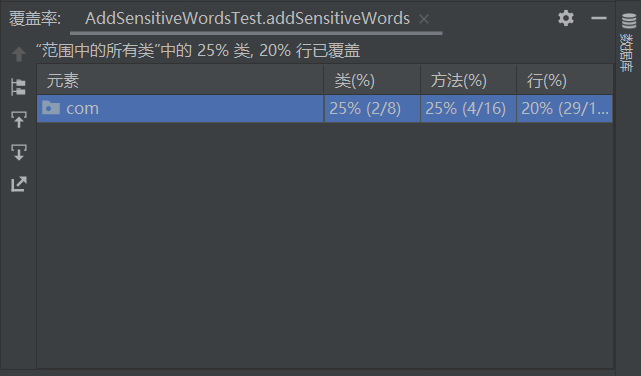
3) 计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
对AddSensitiveWordsTest函数的单元测试
package com;
import com.github.stuxuhai.jpinyin.PinyinException;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.HashSet;
import java.util.Set;
import static org.junit.Assert.*;
public class AddSensitiveWordsTest {
@Before
public void setUp() throws Exception {
System.out.println("测试开始!");
}
@After
public void tearDown() throws Exception {
System.out.println("测试结束!");
}
@Test
public void addSensitiveWords()throws PinyinException {
String[] ss={"笨蛋","sMart","小可爱"};
Set<String>aa =new HashSet<>();
aa.add("笨蛋");
aa.add("sMart");
aa.add("小可爱");
aa.add("bendan");
aa.add("xiaokeai");
aa.add("bd");
aa.add("xka");
AddSensitiveWords awords=new AddSensitiveWords();
assertEquals(aa,awords.addSensitiveWords(ss));
}
}
按照目前这个函数的功能是将一些中文的敏感词进行扩充,比如将中文转换成拼音和拼音缩写,而英文则不做处理。

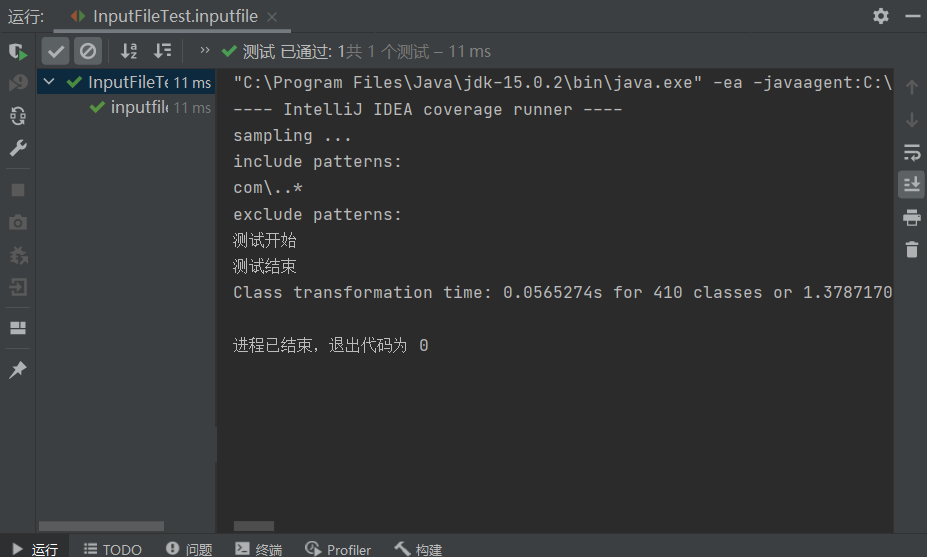
对InputFileTest函数的单元测试
package com;
import java.io.IOException;
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
public class InputFileTest {
InputFile input = new InputFile();
public InputFileTest() {
}
@Before
public void setUp() throws Exception {
System.out.println("测试开始");
}
@After
public void tearDown() throws Exception {
System.out.println("测试结束");
}
@Test
public void inputfile() throws IOException {
InputFile var10001 = this.input;
Assert.assertEquals("我盡力了哈哈哈害人不淺太過分了要少熬夜dsqbdquidq@#!#!&*#!hhhh1hw1uhw1
", InputFile.inputfile("C:\Users\24427\Desktop\test.txt"));
}
}
对于读到的文件的数据转换成字符串形式并返回主函数,验证是否有乱码或者换行符错误。
4) 计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
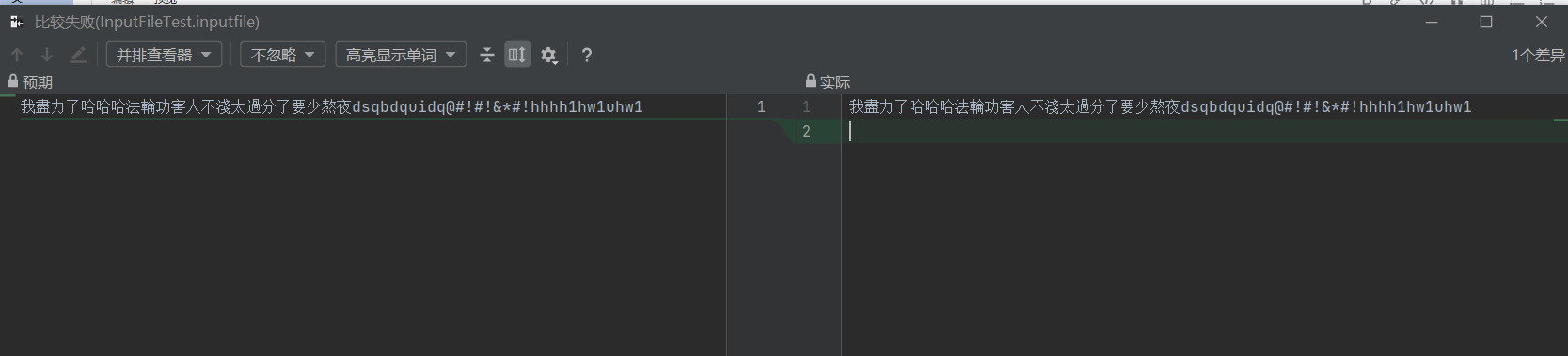
对AddSensitiveWords函数输出结果异常,因为在处理时每个字符串之后都加了一个换行符。但是对解题过程影响不大。

三、心得
- 不要想着一步登天,一个看似很困难的项目可以分为好几步去做。要先去分析这个项目,先找到它的基本功能,在将基本功能拆解,之后再进行功能的拓展。比如这个敏感词检测的题目,可以先实现将没有任何变形的敏感词找到并统计个数,再实现更加进阶的功能。二步骤可以拆解为:输入文件存入一个设定的变量中->构建敏感词的hashmap树->在待检测文件中检测敏感词,并输出总数->输出答案到指定文件的位置。而每个步骤可以分为一个类,这样能使自己的思路更清楚。
- 无论用哪一门语言,基础知识得先掌握。不然一下直奔算法,将会看不懂网上所提供的代码的每一步含义。还需要了解语言的一些原有的函数,这会在打代码的过程中减少很多困难并减少代码量。