一. 梳理JML语言的理论基础、应用工具链情况
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。
JML语言的理论基础:
1. 注释结构
JML以javadoc注释的方式来表示规格,每行都以@起头。有两种注释方式,行注释和块注释。其中行注释的表示方式为//@annotation,块注释的方式为/* @ annotation @*/。
2. JML表达式 (JML的表达式是对Java表达式的扩展,新增了一些操作符和原子表达式。)
(1).原子表达式:
esult表达式:表示一个非void类型的方法执行所获得的结果,即方法执行后的返回值。
old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。
ot_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
ot_modified(x,y,...)表达式:与 ot_assigned表达式类似。
onnullelements(container)表达式:表示container对象中存储的对象不会有null。
ype(type)表达式:返回类型type对应的类型(Class)。
ypeof(expr)表达式:该表达式返回expr对应的准确类型。
(2).量化表达式:
forall表达式:全称量词修饰的表达式。
exists表达式:存在量词修饰的表达式。
sum表达式:返回给定范围内的表达式的和。
max表达式:返回给定范围内的表达式的最大值。
min表达式:返回给定范围内的表达式的最小值。
um_of表达式:返回指定变量中满足相应条件的取值个数。
(3).集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。
(4).操作符:
子类型关系操作符:E1<:E2,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。
等价关系操作符:b_expr1<==>b_expr2或者b_expr1<=!=>b_expr2,其中b_expr1和b_expr2都是布尔表达式,这两个表达式的意思是b_expr1==b_expr2或者b_expr1!=b_expr2。
推理操作符:b_expr1==>b_expr2或者b_expr2<==b_expr1。
变量引用操作符: othing指示一个空集;everything指示一个全集。
3. 方法规格
前置条件(requires):对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性。
后置条件(ensures):对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。
副作用(assignable或者modifiable):方法在执行过程中对输入对象或this对象进行了修改.
4. 对数据规格的抽象:
不变式限制(invariant)。
约束限制(constraints)。
JML语言的应用工具链情况:
JML工具链
openjml:检测JML注释正确性,可以自动识别和分析处理JML规格。
SMT Solver工具:以静态方式来检查代码实现对规格的满足情况。
单元测试生成器jmlunit:可以从JML注释中生成JUnit测试代码。
二.部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
测试代码如下:
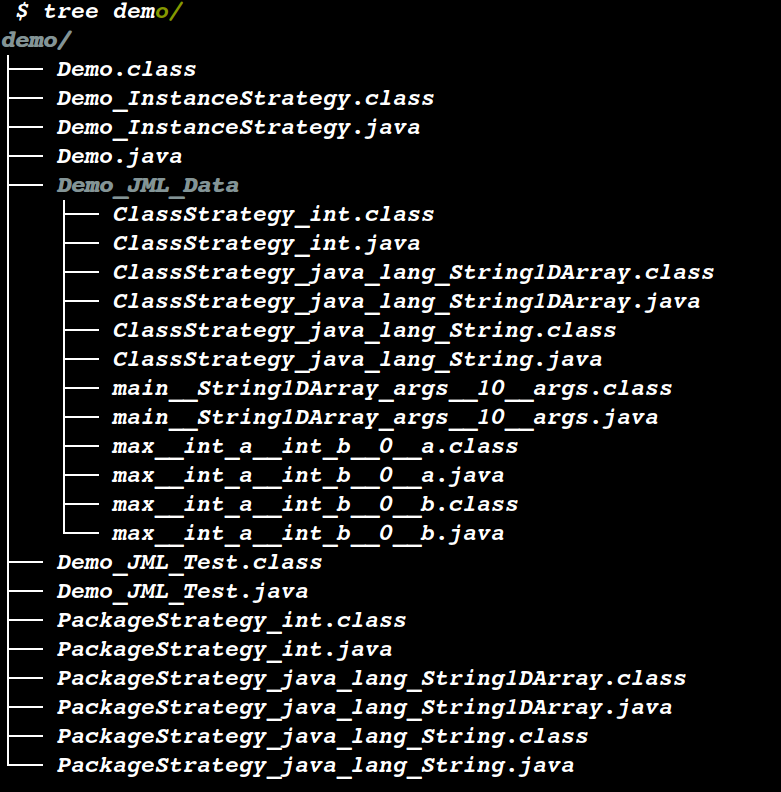
得到的文件树:
测试结果:

从Passed测试数据来看,自动测试选取了一些边界条件进行测试,通过自动测试,基本可以认为代码符合规格。
三.按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
1.第一次作业:实现一个路径管理系统,可以通过各类输入指令来进行数据的增删查改等交互。
第一次作业因为需要求出容器内不同结点个数,而那时候没有了解hashset,hashmap,一直用的是ArrayList,当每次求容器内不同结点个数,采用了快排,然后在计算不同结点的算法,没有进行充分的测试,导致强测没过。听同学讲思路分析后,重构了这次作业的架构。
重构后的架构如下:

MyPath类除了记录结点的容器(ArrayList)nodes外,还使用了一个容器(HashSet)distinctode用于记录不同结点,这样distinctnode.size就表示了MyPath里面不同结点的个数了。MyPathContainer类中使用了三个容器,一个是记录全部Path的容器(ArrayList),一个是记录Path序号的容器(ArrayList),还有一个记录全部Path的所有不同结点的HashMap容器,键值为结点,value为结点的数量,当有新的Path进入或者删除Path时,只需取出该结点对应的value,对value进行操作即可。
2. 第二次作业:在第一次作业的基础上,实现一个无向图系统。
架构如下:
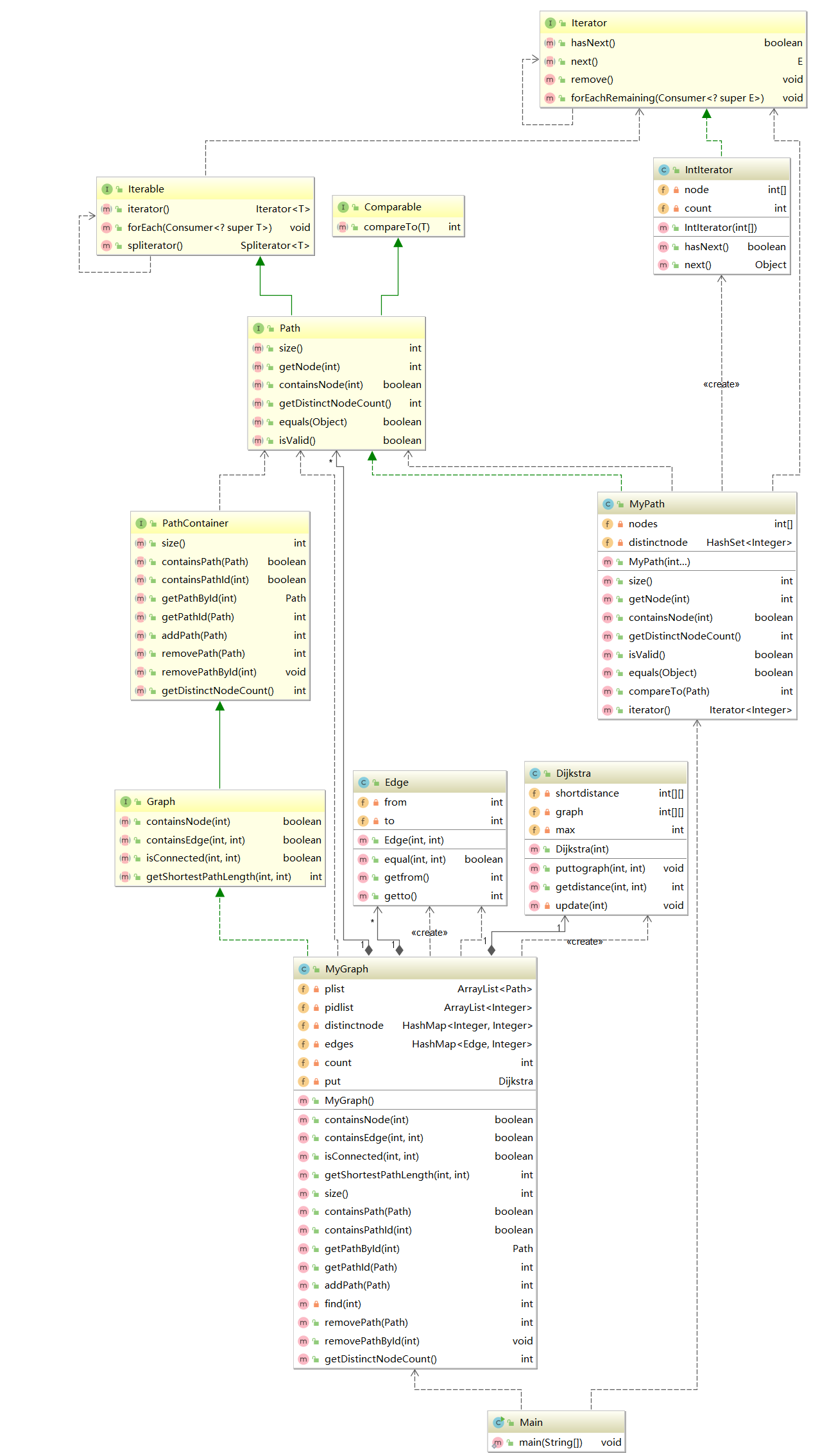
第二次作业相对第一次作业,只需要多实现containsNode(), containsEdge(), isConnected(), getShortestPathLength()四个方法。在第一次作业的基础上,增加了两个类,Dijkstra和Edge类,MyGraph增加一个容器(HashMap,key为Edge,value为equal key的数量)edges在每次增加或者删除Path时,只需做到和distinctnode相同的操作即可,先判断,然后决定是否改变value,containsNode(), containsEdge()只需用上面的算法即可实现,isConnected(), getShortestPathLength()两个方法主要与Dijkstra类有关,因为考虑到时间复杂度,采用迪杰斯特拉算法,并且保存中间已经算出的距离,当没有增加或者删除的操作,若已经在前面算出了距离,下次需要用时直接返回就行;当有增加或者删除的操作时,就需要改变整张图,需要重新计算。
3. 第三次作业:实现一个简单地铁系统。
架构如下:
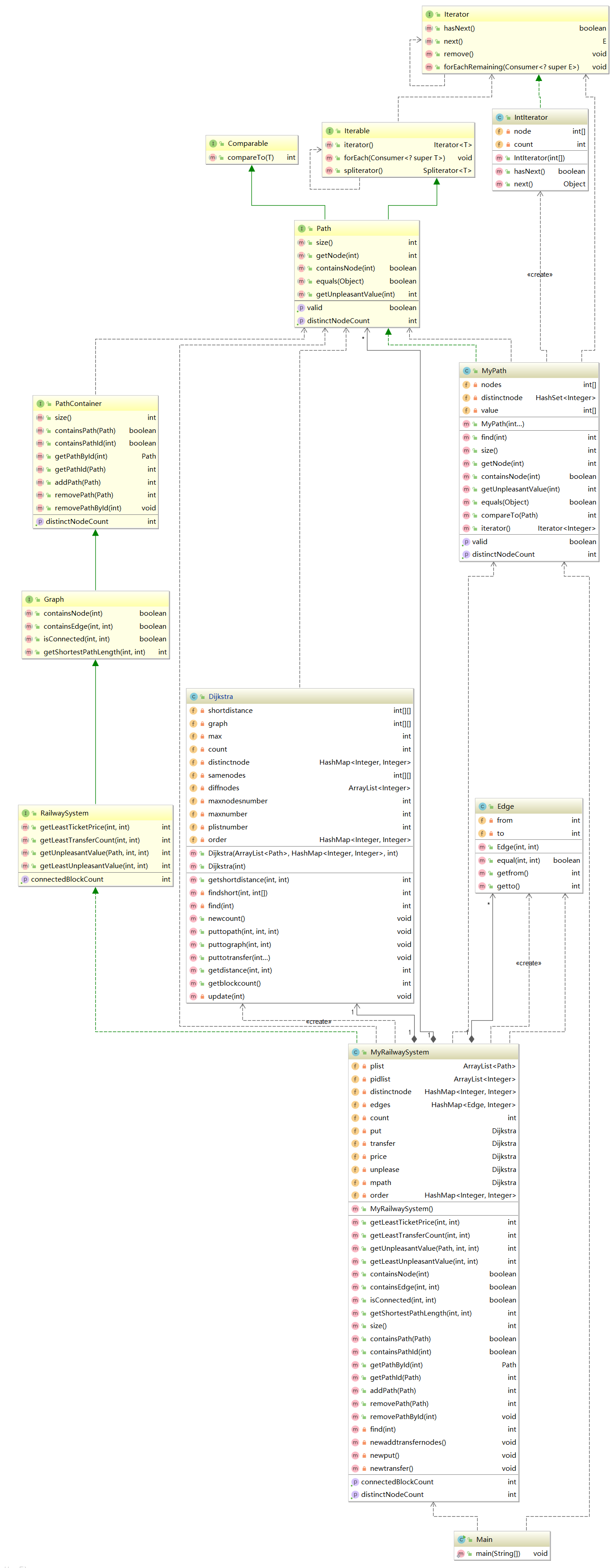
第三次作业相对于第二次作业主要是多了四个问题,连通块,LeastTransfer(最少换乘次数),LeastPrice(最少票价),LeastUnpleasantValue(最小不满意度)的问题,其余与第二次作业一致,连通块和最少换乘次数是基于一个图操作的,即建一个图把每一个条路径上所有相连的点都记录下来,且相连点之间的距离均为1,使用迪杰斯特拉算法求两点之间的距离时就是求出最少换乘次数,通过广度优先算法,即可求出连通块数量;LeastPrice(最少票价),LeastUnpleasantValue(最小不满意度)这两个问题基于添加结点解决,将所有在两条Path中出现的结点一分为二,两个点之间距离为转乘票价或者转乘的不满意度,只需这样,然后采用迪杰斯特拉算法算出最小值即可。
四.按照作业分析代码实现的bug和修复情况
第一次因为架构的问题,导致强测超时,没有进入互测,除了重构外,还发现了一个bug,通过ArrayList存数据时,取出来的并不是该数据,而是Integer对象。
第二次互测时被找出了一个bug,之前是当起点与终点相同时,没有将该边加入边的容器中,导致了结果的错误。
第三次作业因为优化不够的问题,导致了强测中两个点没有过,修复时做了一些优化,因为是迪杰斯特拉算法,所以当知道起点和终点时,可以计算起点到终点,也可以计算终点到起点,找中间计算结果时可以找两次后再进行更新,这样,应该能节省一点时间。
五.阐述对规格撰写和理解上的心得体会
使用规格能将一个问题讲清楚,能将一个方法描述清楚,只不过因为这样,规格写起来可能会比自然语言表达更加繁杂;
通过规格也能进行自动化测试,能够使自己写的代码更加可靠,以前只能对一个类进行测试,通过规格测试工具能够对一个方法进行测试,这样,以后出现bug的机率也变小了;
通过规格,也能使一个方法做一件事,如果将所有事都交给一个方法来实现,规格将会变得非常复杂;
规格也能将设计与实现分离开,各做各的,不容易产生错误。