前述:
Python不但能非常灵活地定义函数,而且本身内置了很多有用的函数,可以直接调用。
这里就是记录一下自己学习的内容,因为是个小白,所以很多基础的东西也会记录一下,主要还是加深一下自己的印象。
资料来源于廖雪峰老师的官网,还有哔站的教学视频。
调用函数:
要调用一个函数,需要知道函数的名称和参数,可以直接从Python的官网查看文档:http://docs.python.org/3/library/functions.html#abs
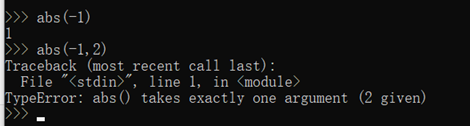
调用函数时候传入的参数数量不怼,会报错,比如:
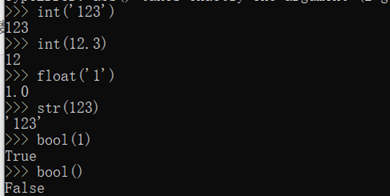
数据类型转换
Python内置的常用函数还包括数据类型转换函数,比如int()函数可以把其他数据类型转换为整数:
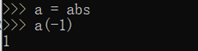
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个"别名":
就像这个变量a指向了abs,所以也可以通过a调用abs函数。
定义函数:
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
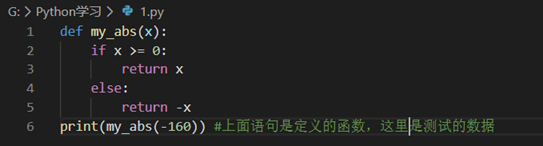
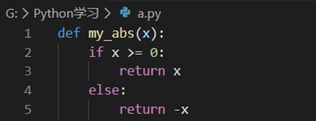
比如我们自定义个求绝对值的 my_abs 函数为例子:
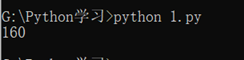
也可以这么写
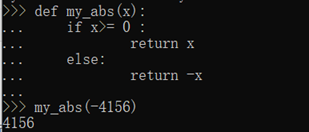
my_abs()的函数定义保存为1.py文件了,那么,可以在该文件的当前目录下启动Python解释器,用from 1 import my_abs来导入my_abs()函数,注意1是文件名(不含.py扩展名):

空函数:
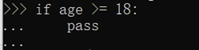
如果想定义一个什么事也不做的空函数,可以用pass语句。实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
pass还可以用在其他语句里,缺少了pass,代码运行就会有语法错误,比如:
参数检查:
调用函数时,如果参数个数不对,Python解释器会自动检查出来,并抛出TypeError :

但是如果参数类型不对,Python解释器就无法帮我们检查。试试my_abs和内置函数abs的差别:
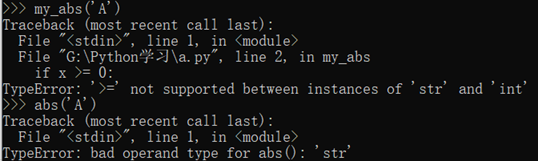
当传入了不恰当的参数时,内置函数abs会检查出参数错误,而我们定义的my_abs没有参数检查,会导致if语句出错,出错信息和abs不一样。所以,这个函数定义不够完善。
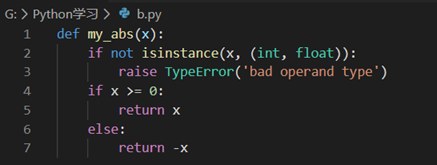
让我们修改一下my_abs的定义,对参数类型做检查,只允许整数和浮点数类型的参数。数据类型检查可以用内置函数isinstance()实现:
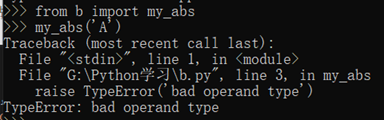
返回多个值:
给出坐标、位移和角度,就可以计算出新的坐标,import math语句表示导入math包,并允许后续代码引用math包里的sin、cos等函数。
然后,我们就可以同时获得返回值:
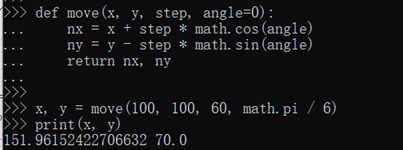
返回值是一个tuple!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。这只是一种假象,Python函数返回的仍然是单一值:

函数的参数
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
位置参数
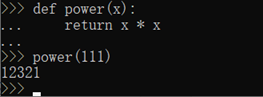
我们这里先写一个计算X²的函数,对于power(x)函数,参数x就是一个位置参数。
当我们调用power函数时,必须传入有且仅有的一个参数x:
那用来计算X的n次方怎么办?这样我们可以把power(x)修改为power(x, n):
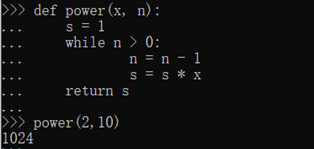
power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
默认参数
新的power(x, n)函数定义没有问题,但是,旧的调用代码失败了,原因是我们增加了一个参数,导致旧的代码因为缺少一个参数而无法正常调用:

这个时候,默认参数就排上用场了。Python的错误信息很明确:调用函数power()缺少了一个位置参数n。就像计算的X²可以这么写:
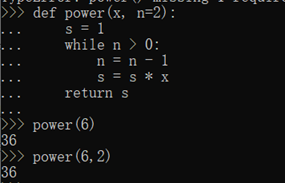
这样,当我们调用power(5)时,相当于调用power(5, 2)。
设置默认参数时,有几点要注意:
一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
二是当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
默认函数最大的好处就是降低了调用函数的难度,
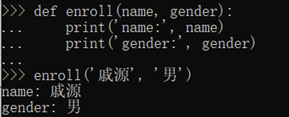
比如现在我们需要传入两个参数name和gender。这样,调用enroll()函数只需要传入两个参数:
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
注意:默认参数必须指向不变对象!
我们可以用None这个不变对象来实现,比如:
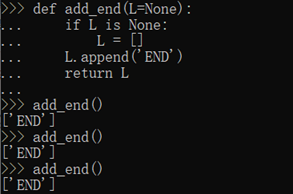
不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。
可变参数
数学题为例子,给定一组数字a,b,c……,计算a2 + b2 + c2 + ……。
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来:

调用的时候先装一个list或tuple:(正确错误作对比)

我们把函数的参数改为可变参数:

我们仅仅在参数前面加了个*号,但是表示的意义确实完全不同的。在函数内部,参数numbers接收到的是一个tuple,调用该函数时,可以传入任意个参数,包括0个参数。
关键字参数
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict,然后,把该dict转换为关键字参数传进去:

简化的写法:

**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。这种方式定义的函数如下:

如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:

命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:

由于调用时缺少参数名city和job,Python解释器把这4个参数均视为位置参数,但person()函数仅接受2个位置参数。命名关键字参数可以有缺省值,从而简化调用,由于命名关键字参数city具有默认值,调用时,可不传入city参数:

使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数。
参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
注意:虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
比如定义一个函数,包含上述若干种参数,在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去:

通过一个tuple和dict,你也可以调用上述函数:
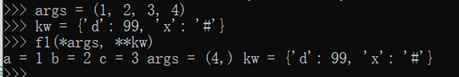
递归函数:
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
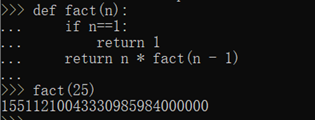
举个例子,我们来计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示,可以看出:
fact(n) = n! = 1 x 2 x 3 x ... x (n-1) x n = (n-1)! x n = fact(n-1) x n。所以,fact(n)可以表示为 n x fact(n-1),只有n=1时需要特殊处理。
于是,fact(n)用递归的方式写出来就是:
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出:
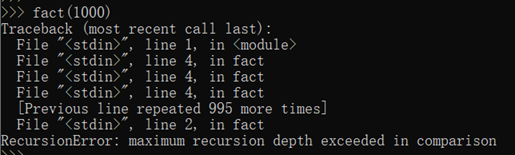
解决递归调用栈溢出的方法是通过尾递归优化,尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
要改成尾递归方式,需要多一点代码,主要是要把每一步的乘积传入到递归函数中:
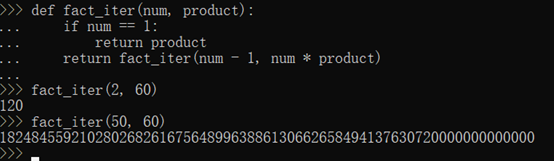
return fact_iter(num - 1, num * product)仅返回递归函数本身,num - 1和num * product在函数调用前就会被计算,不影响函数调用。