敏捷冲刺三
Task1:团队TSP
| 团队任务 | 预估时间 | 实际时间 | 完成日期 |
|---|---|---|---|
| 搜索引擎相关内容了解 | 300 | 500 | 11-5 |
| 数据库表的创建 | 180 | 150 | 11-8 |
| 学院网站的爬取 | 210 | 460 | 11-10 |
| 建立数据库索引 | 190 | -- | -- |
| 代码测试 | 180 | -- | -- |
| 前端页面的设计 | 240 | -- | -- |
| 前后端的交互 | 300 | -- | -- |
| 搜索引擎测试 | 260 | -- | -- |
Task2:描述项目进展
| 成员 | 任务安排 | 预期任务量/小时 |
|---|---|---|
| 秦玉(组长) | 安装Twisted18.7.0,pyOpenSSL18.0.0,python-dateutil2.7.3等,配置环境 | 180 |
| 陈晓菲 | 安装Twisted18.7.0,pyOpenSSL18.0.0,python-dateutil2.7.3等,配置环境 | 180 |
| 韩烨 | 前端模板的设计 | 180 |
| 姚雯婷 | 分析学院页面结构,并且编写爬虫代码 | 180 |
| 罗佳 | 完成团队TSP表格,完成第三次冲刺博客园,实践、初步编写代码 | 180 |
| 高天 | 完成团队TSP表格,完成第三次冲刺博客园,实践、初步编写代码 | 180 |
Task3:目前面临的困难
- 雯婷:学校的网站太奇怪了,根本就不是正常的css页面,还在用老式的table,然后网上教的都是css页面的抓取选择,一个div都没有,所以我们的爬虫爬不到里面的数据。然后尝试了很多方法终于找到了一个方法从a里找到对应的href的内容并爬取下来:
#1. 获取文章列表页中的文章url交给scrapy下载并进行解析
#2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse
# 解析列表页中的所有文章url并交给scrapy下载后并进行解析
post_urls = response.css("a::attr(href)").extract()
能爬取出页面,但是进不了回调函数里,就不能写入数据库,dont_filter=True这个方法就是不过滤,就可以进入回调函数了
yield Request(url=parse.urljoin(response.url, post_url), callback=self.parse_content,dont_filter=True)
- 秦玉:在安装Twisted模块中,没办法用pip install直接在线安装,因为需要C++编译,所以采用WHL来安装这些模块库。但是在安装过程中出现了如图版本不匹配的问题。经过检测版本代码,我的pytho版本是3.7的,windows是64位的,和下载的whl版本是匹配的,但是一直这样报错:
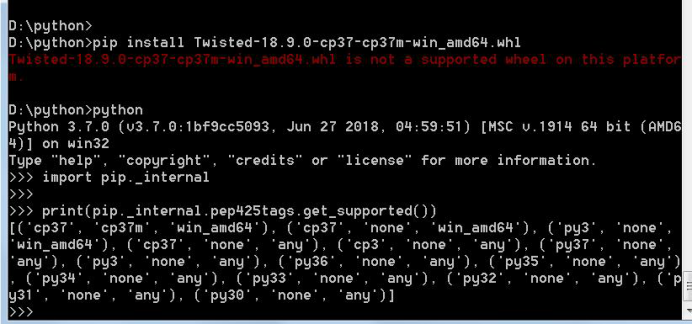
经过检测和我下载的python版本没差别,但是一直出现这个问题,后来摸索中发现mysqlclient的模块库最开始successfully,但是后续import导入时仍然报错,显示没有安装这个库。最后在我的D:pythonLibsite-packages路径下的这些库文件中,模块名字带上了版本号。经过文件的更名,然后就成功导入了。。。
- 晓菲:
需要学习的内容太多了,一个插件就有很多的用法,还需要一个个去百度去查资料然后在一个一个的尝试自己再调用。
Task4:下一步计划
- 解决学院网站的爬虫问题
- 了解django框架的结构
- 开始准备前端网页样式设计
Task5:项目燃尽图

Task6:提交历史截图
因为爬虫的爬取校园网的一些问题,没办法成功爬取下来,所以没有提交记录
Task7:站立式会议照片

