1 简介
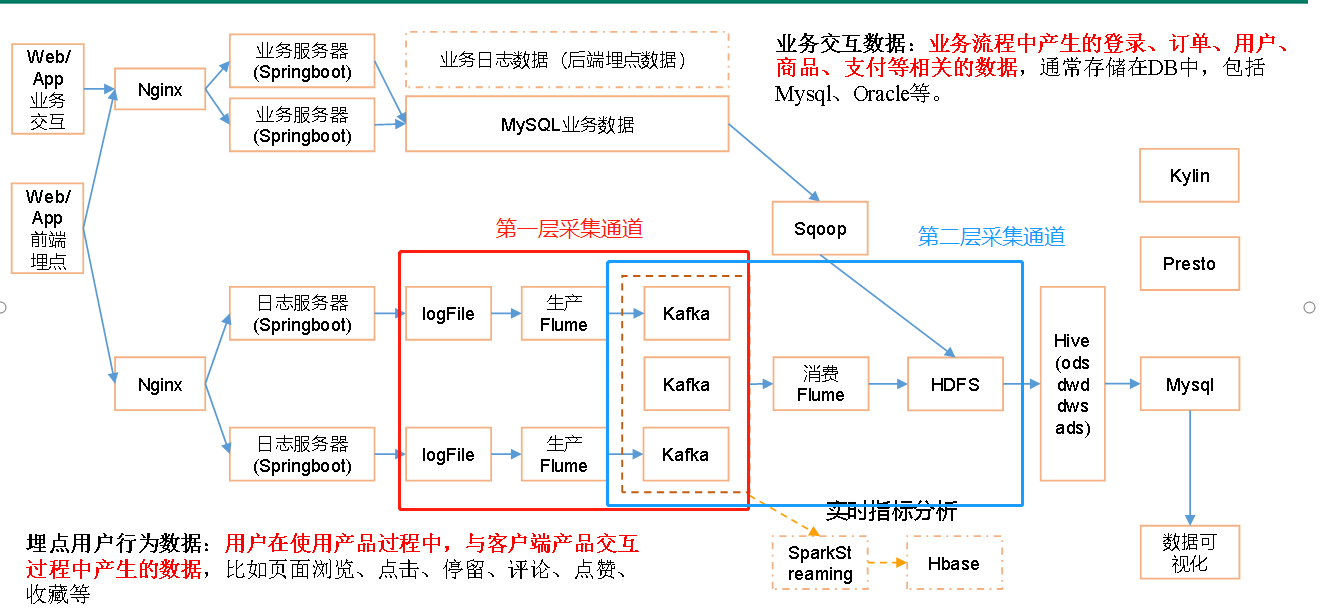
2 第一层数据采集通道
2.1 组件
1.第一层采集脚本Source的选择
①Source:
数据源在日志文件中!
读取日志中的数据,可以使用以下Source
ExecSource: 可以执行一个linux命令,例如tail -f 日志文件,
讲读取的到的数据封装为Event!
不用!不安全,可能丢数据!
SpoolingDirSource: 可以读取一个目录中的文本文件!
保证目录中没有重名的文件!
保证目录中的文件都是封闭状态,一旦放入目录中,不能再继续写入!
每个日志封闭后,才能放入到SpoolingDir,不然agent就故障!
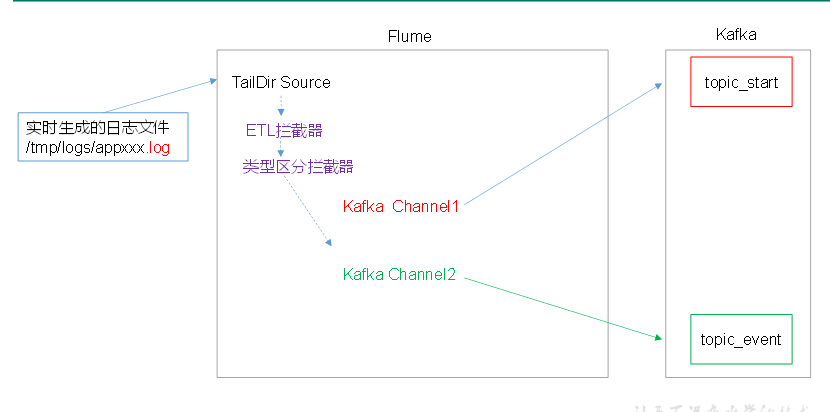
TailDirSource: 接近实时第读取指定的文件!断点续传功能!
使用此Source!
使用TailDirSource
②Channel:
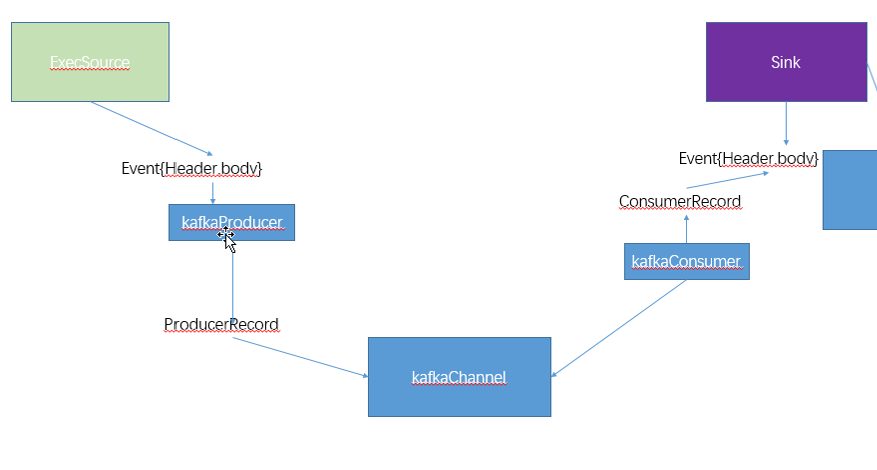
KafkaChannel:
优点: 基于kafka的副本功能,提供了高可用性!event被存储在kafka中!
即便agent挂掉或broker挂掉,依然可以让sink从channel中读取数据!
应用场景:
①KafkaChannel和sink和source一起使用,单纯作为channel。
②KafkaChannel+拦截器+Source,只要Source把数据写入到kafka就完成
目前使用的场景!
③KafkaChannel+sink,使用flume将kafka中的数据写入到其他的目的地,例如hdfs!
为例在上述场景工作,KafkaChannel可以配置生产者和消费者的参数!
配置参数:
①在channel层面的参数,例如channel的类型,channel的容量等,需要和之前一样,
在channel层面配置,例如:a1.channel.k1.type
②和kafka集群相关的参数,需要在channel层面配置后,再加上kafka.
例如: a1.channels.k1.kafka.topic : 向哪个主题发送数据
a1.channels.k1.kafka.bootstrap.servers: 集群地址
③和Produer和Consumer相关的参数,需要加上produer和consumer的前缀:
例如:a1.channels.k1.kafka.producer.acks=all
a1.channels.k1.kafka.consumer.group.id=atguigu
必须的配置:
type=org.apache.flume.channel.kafka.KafkaChannel
kafka.bootstrap.servers=
可选:
kafka.topic: 生成到哪个主题
parseAsFlumeEvent=true(默认):
如果parseAsFlumeEvent=true,kafkaChannel会把数据以flume中Event的结构作为参考,
把event中的header+body放入ProducerRecord的value中!
如果parseAsFlumeEvent=false,kafkaChannel会把数据以flume中Event的结构作为参考,
把event中body放入ProducerRecord的value中!
a1.channels.k1.kafka.producer.acks=0
2. 拦截器
日志数据有两种类型,一种是事件日志,格式 时间戳|{"ap":xx,"cm":{},"et":[{},{}]}
另一种是启动日志,格式:{"en":"start"}
在1个source对接两个KafkaChannel时,需要使用MulitPlexing Channel Selector,
讲启动日志,分配到启动日志所在的Chanel,讲事件日志分配到事件日志所在的Channel!
MulitPlexing Channel Selector根据event,header中指定key的映射,来分配!
需要自定义拦截器,根据不同的数据类型,在每个Event对象的header中添加key!
功能: ①为每个Event,在header中添加key
②过滤不符合要求的数据(格式有损坏)
启动日志: {},验证JSON字符串的完整性,是否以{}开头结尾
事件日志: 时间戳|{}
时间戳需要合法:
a)长度合法(13位)
b)都是数字
验证JSON字符串的完整性,是否以{}开头结尾
2.2 组件关系(请先复习flume)
2.3 flume配置
f1.conf
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔 a1.sources = r1 a1.channels = c1 c2 #组名名.属性名=属性值 a1.sources.r1.type=TAILDIR a1.sources.r1.filegroups=f1 a1.sources.r1.batchSize=1000 #读取/tmp/logs/app-yyyy-mm-dd.log ^代表以xxx开头$代表以什么结尾 .代表匹配任意字符 #+代表匹配任意位置 a1.sources.r1.filegroups.f1=/tmp/logs/^app.+.log$ #JSON文件的保存位置 a1.sources.r1.positionFile=/opt/module/flume/test/log_position.json #定义拦截器 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.dw.flume.MyInterceptor$Builder #定义ChannelSelector a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = topic a1.sources.r1.selector.mapping.topic_start = c1 a1.sources.r1.selector.mapping.topic_event = c2 #定义chanel a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.channels.c1.kafka.topic=topic_start a1.channels.c1.parseAsFlumeEvent=false a1.channels.c2.type=org.apache.flume.channel.kafka.KafkaChannel a1.channels.c2.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.channels.c2.kafka.topic=topic_event a1.channels.c2.parseAsFlumeEvent=false #连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据! a1.sources.r1.channels=c1 c2
2.4 第一层通道启动脚本
#!/bin/bash #使用start启动脚本,使用stop停止脚本 if (($#!=1)) then echo 请输入start或stop! exit; fi #定义cmd用来保存要执行的命令 cmd=cmd if [ $1 = start ] then cmd="source /etc/profile;nohup flume-ng agent -c $FLUME_HOME/conf/ -n a1 -f $FLUME_HOME/myagents/f1.conf -Dflume.root.logger=DEBUG,console > /home/atguigu/f1.log 2>&1 &" elif [ $1 = stop ] then cmd="ps -ef | grep f1.conf | grep -v grep | awk '{print $2}' | xargs kill -9" else echo 请输入start或stop! fi #在hadoop102和hadoop103开启采集 for i in hadoop102 hadoop103 do ssh $i $cmd done
3 第二层数据采集通道
3.1 组件
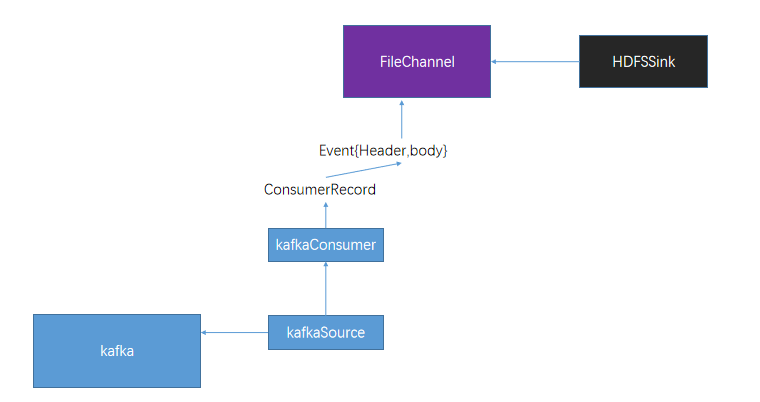
①kafkaSource:kafkaSource就是kafka的一个消费者线程,可以从指定的主题中读取数据!
如果希望提供消费的速率,可以配置多个kafkaSource,这些source组成同一个组!
kafkaSource在工作时,会检查event的header中有没有timestamp属性,如果没有,
kafkaSource会自动为event添加timestamp=当前kafkaSource所在机器的时间!
kafkaSource启动一个消费者,消费者在消费时,默认从分区的最后一个位置消费!
必须的配置:
type=org.apache.flume.source.kafka.KafkaSource
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafka.topics=消费的主题
kafka.topics.regex=使用正则表达式匹配主题
可选的配置:
kafka.consumer.group.id=消费者所在的组id
batchSize=一次put多少数据,小于10000
batchDurationMillis=一次put可以最多使用多少时间
和kafkaConsumer相关的属性:kafka.consumer=consumer的属性名
例如:kafka.consumer.auto.offset.reset
②fileChannel: channel中的event是存储在文件中!比memorychannel可靠,但是效率略低!
必须的配置:
type=file
checkpointDir=checkpoint线程(负责检查文件中哪些event已经被sink消费了,将这些event的文件删除)保存数据的目录!
useDualCheckpoints=false 是否启动双检查点,如果启动后,会再启动一个备用的checkpoint线程!
如果改为true,还需要设置backupCheckpointDir(备用的checkpoint线程的工作目录)
dataDirs=在哪些目录下保存event,默认为~/.flume/file-channel/data,可以是逗号分割的多个目录!
③hdfssink: hdfssink将event写入到HDFS!目前只支持生成两种类型的文件: text | sequenceFile,这两种文件都可以使用压缩!
写入到HDFS的文件可以自动滚动(关闭当前正在写的文件,创建一个新文件)。基于时间、events的数量、数据大小进行周期性的滚动!
支持基于时间和采集数据的机器进行分桶和分区操作!
HDFS数据所上传的目录或文件名可以包含一个格式化的转义序列,这个路径或文件名会在上传event时,被自动替换,替换为完整的路径名!
使用此Sink要求本机已经安装了hadoop,或持有hadoop的jar包!
配置:
必须配置:
type – The component type name, needs to be hdfs
hdfs.path – HDFS directory path (eg hdfs://namenode/flume/webdata/)
3.2 组件关系(请先复习flume)
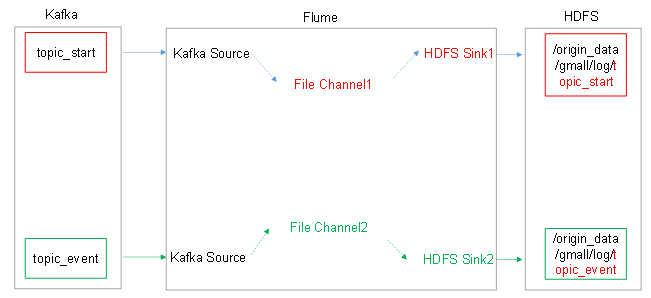
3.3 flume 配置
#配置文件编写 a1.sources = r1 r2 a1.sinks = k1 k2 a1.channels = c1 c2 #配置source a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource a1.sources.r1.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r1.kafka.topics=topic_start a1.sources.r1.kafka.consumer.auto.offset.reset=earliest a1.sources.r1.kafka.consumer.group.id=CG_Start a1.sources.r2.type=org.apache.flume.source.kafka.KafkaSource a1.sources.r2.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r2.kafka.topics=topic_event a1.sources.r2.kafka.consumer.auto.offset.reset=earliest a1.sources.r2.kafka.consumer.group.id=CG_Event #配置channel a1.channels.c1.type=file a1.channels.c1.checkpointDir=/opt/module/flume/c1/checkpoint #启动备用checkpoint a1.channels.c1.useDualCheckpoints=true a1.channels.c1.backupCheckpointDir=/opt/module/flume/c1/backupcheckpoint #event存储的目录 a1.channels.c1.dataDirs=/opt/module/flume/c1/datas a1.channels.c2.type=file a1.channels.c2.checkpointDir=/opt/module/flume/c2/checkpoint a1.channels.c2.useDualCheckpoints=true a1.channels.c2.backupCheckpointDir=/opt/module/flume/c2/backupcheckpoint a1.channels.c2.dataDirs=/opt/module/flume/c2/datas #sink a1.sinks.k1.type = hdfs #一旦路径中含有基于时间的转义序列,要求event的header中必须有timestamp=时间戳,如果没有需要将useLocalTimeStamp = true a1.sinks.k1.hdfs.path = hdfs://hadoop102:9000/origin_data/gmall/log/topic_start/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = logstart- a1.sinks.k1.hdfs.batchSize = 1000 #文件的滚动 #60秒滚动生成一个新的文件 a1.sinks.k1.hdfs.rollInterval = 30 #设置每个文件到128M时滚动 a1.sinks.k1.hdfs.rollSize = 134217700 #禁用基于event数量的文件滚动策略 a1.sinks.k1.hdfs.rollCount = 0 #指定文件使用LZO压缩格式 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = lzop #a1.sinks.k1.hdfs.round = true #a1.sinks.k1.hdfs.roundValue = 10 #a1.sinks.k1.hdfs.roundUnit = second a1.sinks.k2.type = hdfs a1.sinks.k2.hdfs.path = hdfs://hadoop102:9000/origin_data/gmall/log/topic_event/%Y-%m-%d a1.sinks.k2.hdfs.filePrefix = logevent- a1.sinks.k2.hdfs.batchSize = 1000 a1.sinks.k2.hdfs.rollInterval = 30 a1.sinks.k2.hdfs.rollSize = 134217700 a1.sinks.k2.hdfs.rollCount = 0 a1.sinks.k2.hdfs.fileType = CompressedStream a1.sinks.k2.hdfs.codeC = lzop #a1.sinks.k2.hdfs.round = true #a1.sinks.k2.hdfs.roundValue = 10 #a1.sinks.k2.hdfs.roundUnit = second #连接组件 a1.sources.r1.channels=c1 a1.sources.r2.channels=c2 a1.sinks.k1.channel=c1 a1.sinks.k2.channel=c2
3.4 第二层通道脚本
#!/bin/bash #使用start启动脚本,使用stop停止脚本 if(($#!=1)) then echo 请输入start或stop! exit; fi if [ $1 = start ] then ssh hadoop104 "source /etc/profile;nohup flume-ng agent -c $FLUME_HOME/conf/ -n a1 -f $FLUME_HOME/myagents/f2.conf -Dflume.root.logger=INFO,console > /home/atguigu/f2.log 2>&1 &" elif [ $1 = stop ] then ssh hadoop104 "ps -ef | grep f2.conf | grep -v grep | awk '{print $2}' | xargs kill -9" else echo 请输入start或stop! fi
4 数据采集通道的启动
onekeyboot
#!/bin/bash #输入start和stop参数,一键启动或关闭hadoop,zk,kafka集群,启动f1,f2采集通道 if(($#!=1)) then echo 请输入start或stop! exit; fi #编写函数,这个函数的功能为返回集群中启动成功的broker的数量 function countKafkaBrokders() { count=0 for((i=102;i<=104;i++)) do result=$(ssh hadoop$i "jps | grep Kafka | wc -l") count=$[$result+$count] done #函数可以定义返回值,如果不定义,返回函数最后一条命令的执行状态(返回0,代表成功,非0,即为异常) return $count } #启动,注意启动时,各个组件的依赖关系,例如zk必须先于kafka启动,后于kafka关闭 if [ $1 = start ] then zk start hd start kf start #保证kafka集群已经启动时,才能启动f1,f2,判断当前kafka集群启动了多少 broker实例 while [ 1 ] do countKafkaBrokders #如果返回值不为3,有可能是机器还尚未执行broker的启动命令,因此继续判断 if(($?==3)) then break fi sleep 2s done f1 start f2 start #查看启动了哪些进程 xcall jps elif [ $1 = stop ] then f1 stop f2 stop kf stop #在kafka没有停止完成之前,不能停止zk集群 while [ 1 ] do countKafkaBrokders #如果返回值不为0,kafka集群没有停止完成 if(($?==0)) then break fi sleep 2s done zk stop hd stop #查看还剩了哪些进程 xcall jps else echo 请输入start或stop! fi