https://blog.csdn.net/qq_33982605/article/details/106075809
目录
检查点生成多个
Flink的检查点默认是生成一个,想要生成多个可以在conf/flink-conf.yaml中添加如下的参数,在这里我设置的是让其生成2个:state.checkpoints.num-retained: 2
如何通过检查点重新提交?
保存点和检查点内部的生成算法是一致的,工作方式也一致,但保存点相比较检查点有什么不同呢?
保存点与检查点有什么不同?
- 生成逻辑不同
a) 检查点:通过代码进行生成
b) 保存点:由用户通过flink命令行或者web控制台进行手动触发 - 存储的信息不同
保存点相比较检查点来说存储了更为详细的一些元数据信息。
检查点在什么情况下触发?
例如我在另一篇博文中所描述的“重启策略”中的例子,检查点在作业意外失败后会自动重启,并能够从保存的检查点路径中自动恢复状态,且不影响作业逻辑的准确性。
Q:由于作业重启失败,程序退出,我此时修改完BUG后,想要让我的程序接着当初失败的地方重新运行,那么我应如何启动程序呢?
A:读取失败的检查点,然后依托它重新运行即可
sudo
-u hdfs /myflink/flink-1.7.2/bin/flink run -s
hdfs://master:8020/flink/checkpoint0/61c58bf29cbcabb8c2e3146ff4eb24b9/chk-15
-m yarn-cluster
-c flink.ceshi /opt/flink_path/sbt-solr-assembly.jar(-s后面表示的是我检查点的路径,该命令代表的是从我当初检查点处“继续”运行)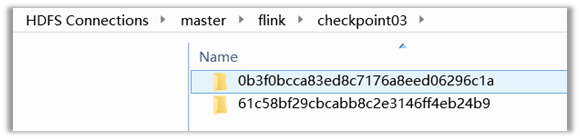 此时可以看到我该目录下面有2个检查点了,
此时可以看到我该目录下面有2个检查点了,
“0b3f0bcca83ed8c7176a8eed06296c1a”
该检查点是依托
“61c58bf29cbcabb8c2e3146ff4eb24b9”
检查点的状态生成的新检查点
保存点在什么情况下触发?
保存点侧重的是维护,即flink作业需要在人工干预的情况下进行重启或升级,维护完毕后再从保存点恢复到升级后的状态。
不取消当前应用时创建保存点
sudo -u hdfs /myflink/flink-1.7.2/bin/flink
savepoint 0b3f0bcca83ed8c7176a8eed06296c1a(注意这里的与前面的检查点要保持一致,因为我要对A程序的检查点进行手动创建保存点,而A程序对应的检查点则是该检查点)
-yid application_1588754764898_0023(针对flink on yarn模式需要指定jobID)
hdfs://master:8020/flink/checkpoint03/s1
取消当前flink应用之前生成保存点
sudo -u hdfs /myflink/flink-1.7.2/bin/flink cancel
-s hdfs://master:8020/flink/checkpoint03/s2
b5745a9e4fe87c403a05e7fc73cacee7
-yid application_1588995876125_0052
从保存点处启动程序
sudo -u hdfs /myflink/flink-1.7.2/bin/flink run
-s
hdfs://master:8020/flink/checkpoint03/s1/savepoint-0b3f0b-ed13f369aadc
-m yarn-cluster
-c flink.ceshi /opt/flink_path/sbt-solr-assembly.jar
Q:在我杀死A程序到我从保存点启动A程序的这个过程当中,我的kafka数据没有断过,那么此时当我从保存点重新启动程序时,我的数据会丢失吗?
A:答案是不会,因为当你在生成保存点时,是通过检查点进行生成的,而检查点中是有Kafka的偏移量的,因此你kafka的数据不会丢失